Zend Lucene индексирует / возвращает результаты перекрестных ссылок на большой набор данных
У нас есть модуль перекрестных ссылок, который я пытаюсь встроить в поисковый индекс Zend Lucene, и у меня возникают серьезные проблемы с производительностью. Пробовал это десятью разными способами и либо ноль / плохой результат, либо супер точность и крайне медленная производительность. Текущее решение, описанное ниже, дает точные результаты, но мучительно медленно на нашем довольно большом наборе данных.
По сути, допустим, у нас есть ACME Part # ABC123 и несколько других номеров деталей. Произведено ACME и распространено WalMart, Costco и Target. У каждого из этих трех магазинов есть свой СОБСТВЕННЫЙ номер детали, который они применяют к товару на своем веб-сайте. Следующая таблица является довольно ясным примером:
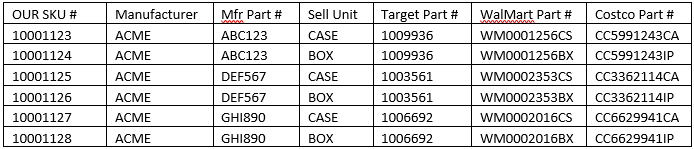
Итак, что мы хотим увидеть, так это то, что когда пользователь ищет «Target 1009936», он возвращает размеры CASE и BOX для ACME Part # ABC123. Когда я ищу «WalMart WM0002353CS», возвращается размер CASE для ACME Part # DEF567. И так далее.
Тот факт, что некоторые оптовые торговцы / дистрибьюторы вводят единицу измерения в свою систему нумерации, а некоторые нет, не имеет значения. Что важно, так это заставить Lucene быстро индексировать и извлекать данные, чего нет в нашей базе данных, содержащей более двух миллионов наименований продуктов.
Для достижения этой цели мы добавили индексированное поле для каждого оптового продавца, где существуют данные перекрестных ссылок для этого товара (давайте просто назовем поля кросс-звезда, кросс-халт и кросс-костко. Итак, в этом примере мы имеем справочные данные для всех, но на самом деле у нас есть только некоторые (но МНОГО… миллионы на миллионы перекрестных ссылок). Так что, в этом случае, я должен был сохранить журнал на $ hit-> crosstar / crosswal / crosscostco Значения в лог-файл, мы увидим:
=>10001123
crosstar: 1009936
crosswal: WM0001256CS
crosscostco: CC5991243CA
crosstarfull: Target 1009936
crosswalfull: WalMart WM0001256CS
crosscostcofull: CostCo CC5991243CA
Мы индексируем как часть, так и отдельно, имя оптовика + часть (многие люди в нашем бизнесе действительно ищут этот путь — я знаю, это звучит безумно), поэтому под sku / первичным ключом есть шесть полей, а не три ,
Проблема в том, как данные токенизируются и индексируются, потому что имена оптовиков вызывают слишком большое сходство между каждым из проиндексированных значений, что заставляет Lucene работать намного больше и дольше, чтобы найти запись. И когда пользователь вводит просто «Target», «WalMart» или «Costco», это похоже на перегрузку мозга, чувак. Пуф.
Я в лучшем случае посредственный разработчик, и тот факт, что я не могу понять это, является в значительной степени доказательством этого. Есть ли у кого-нибудь рекомендации о том, как этот сценарий может быть переработан для достижения желаемых результатов?
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …