визуализировать жанры фильмов
Используя приведенную ниже таблицу примеров, я хотел бы показать:
- а) узлы: во многих фильмах жанр «боевик» или «драма» имеет жанр
- б) края (ненаправленные): когда фильм имеет жанр «драма», то, скорее всего, фильм также имеет жанр «действие»
Мой главный вопрос: как мне лучше всего создать список всех ребер, состоящих из всех связанных жанров?
Допустим, у меня есть таблица с фильмами и жанрами:
GENRE | MOVIE
--------------------------
Drama | A
Action | A
Comedy | A
Documentary | B
Romantic | B
Action | B
Drama | B
Drama | C
Romantic | C
Action | C
---------------------------
У меня нет предпочтений для среды визуализации, но следующее близко подходит к тому, что я имел в виду:
http://visjs.org/examples/network/09_sizing.html
Другие предложения для визуализации приветствуются!
Исходя из моего примера фильма, узлы и ребра могут выглядеть так:
http://jsfiddle.net/wivaku/90oef0pg/
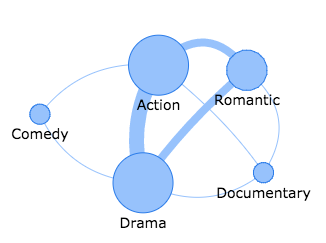
В этом примере края жестко закодированы. В реальной жизни я хотел бы создавать их динамически.
Как мне лучше всего создать ребра JSON, желательно используя PHP?
Фрагмент PHP у меня на данный момент:
<?php
//the SQL rows (normally from SQL, now static):
$rows = json_decode('[["Drama","A"],["Action","A"],["Comedy","A"],["Documentary","B"],["Romantic","B"],["Action","B"],["Drama","B"],["Drama","C"],["Romantic","C"],["Action","C"]]');
$nodes = array();
$edges = array();
// create nodes
$genres = array_count_values(array_map(function($i) {return $i[0]; }, $rows));
foreach ($genres as $key => $value) {
$nodes[] = array("id"=>$key, "value"=>$value);
}
// create edges
// helpful to have genres grouped by movie? (normally from SQL, now static)
$movieGenres = json_decode('[{"movie":"A","genres":["Drama","Action","Comedy"]},{"movie":"B","genres":["Documentary","Romantic","Action","Drama"]},{"movie":"C","genres":["Drama","Romantic","Action"]}]');
// ...
print json_encode(["nodes"=>$nodes, "edges"=>$edges], JSON_NUMERIC_CHECK);
?>
Заранее спасибо!
Обновить: относительно комментариев о деталях / опциях SQL. Таблица, которую я имею, в значительной степени соответствует списку. Итак: genreId и contentId.
Один из вариантов, который я изучал (в качестве ярлыка для кода PHP): объединить жанры для каждого фильма.
SELECT GROUP_CONCAT(genreId SEPARATOR "|") AS genres
FROM contentGenres
GROUP BY contentId
ORDER BY count(genreId) DESC
С данными примера:
Drama|Action|Comedy
Documentary|Romantic|Action|Drama
Drama|Romantic|Action
Или используя идентификаторы жанра:
1|2|3
4|5|2|1
1|5|2
Результат моего реального набора данных составляет ± 11000 строк, в некоторых фильмах 8 жанров.
Решение
Вы можете выполнить обработку на уровне SQL, например, используя этот запрос:
SELECT a.genreId,b.genreId,count(*)
FROM genres as a, genres as b
WHERE a.contentId = b.contentId AND a.genreId < b.genreId
GROUP BY a.genreId, b.genreId
Идентификаторы нумеруются как жанры в вашем примере:
1 Drama
2 Action
3 Comedy
4 Documentary
5 Romantic
Другие решения
Других решений пока нет …