строка содержит много ‘\ 0’ после инфляции
Я пытаюсь распаковать блоки данных, которые были сжаты с помощью zlib, и автор отметил, что для распаковки я должен использовать inflate_init а также inflate с Z_SYNC_FLUSH, Я уверен, что это должно работать, потому что это работает на php следующим образом:
$temp = substr($temp, 2, -4);
$temp{0} = chr(ord($temp{0}) | 1);
$temp = gzinflate($temp);
но я проверял много методов для распаковки этого на C ++ и каждый раз терпел неудачу.
Вот один из них :
char compressedblockbuffer[3371];
char uncompressedblockbuffer[8192];
is.read(compressedblockbuffer, 3371);
z_stream strm;
strm.zalloc = Z_NULL;
strm.zfree = Z_NULL;
strm.opaque = Z_NULL;
strm.avail_in = 3371;
strm.next_in = (Bytef *)compressedblockbuffer;
strm.avail_out = 8192;
strm.next_out = (Bytef *)uncompressedblockbuffer;
inflateInit(&strm);
inflate(&strm, Z_SYNC_FLUSH);
inflateEnd(&strm);
Это не полный код, просто пример, показывающий проблему, и поэтому я указал уже известные размеры.
Я использую последний zlib понимаешь, так может быть что-то изменить в zlib inflate с 2003-2004 года?
Итак, результат:
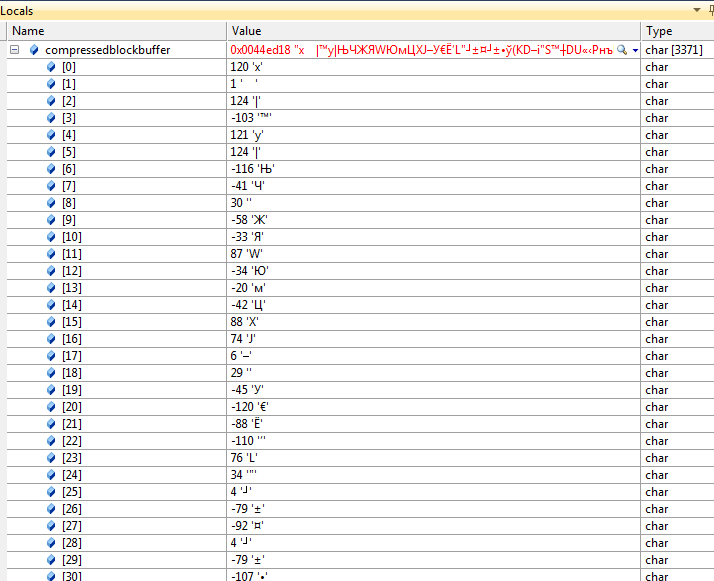
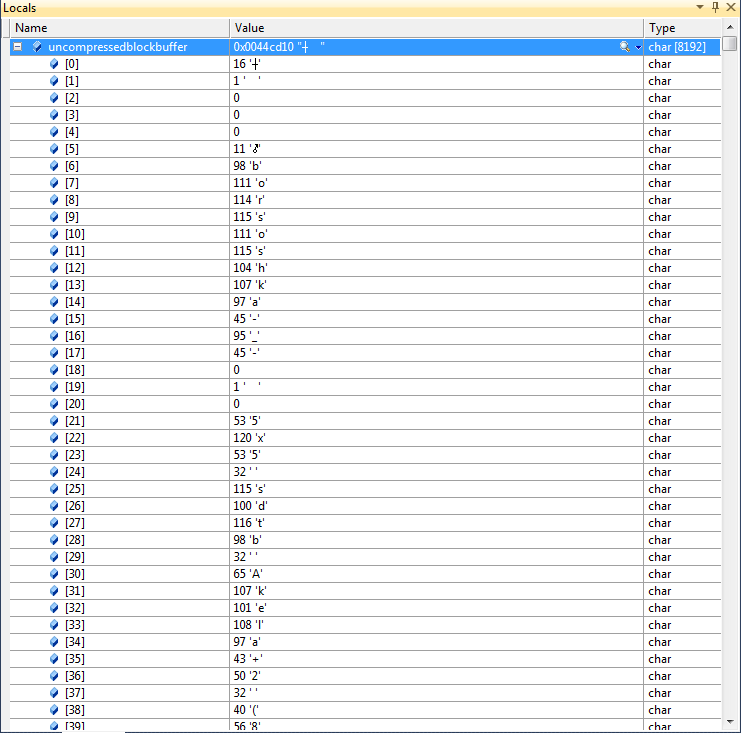
Так кажется что uncompressedblockbuffer содержит ‘\ 0’ в индексах 2,3,4 и многих других, и если я распечатаю это в консоли, я просто вижу два первых элемента.
UPD:
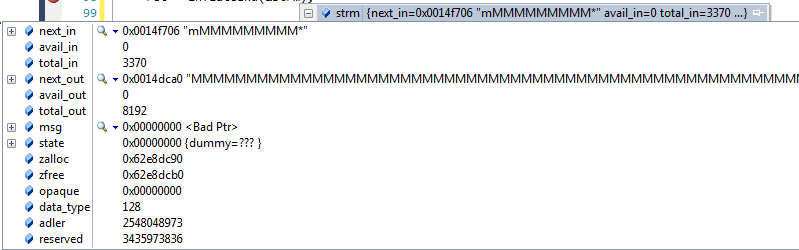
Решение
Если gzinflate() в PHP работает с данными, тогда ваш код не будет. gzinflate() ожидает необработанных данных Ваш код ищет данные с дефлированием в zlib. Если вы хотите декодировать необработанные данные, вы должны использовать inflateInit2(&strm, -15) вместо.
Ваш звонок в inflate() скорее всего, возвращает ошибку, которую вы не проверяете. Вам необходимо всегда проверять коды возврата подпрограмм zlib или, в этом случае, любую функцию, которая потенциально может вернуть ошибку.
Другие решения
Какие данные вы распаковываете? Многие двоичные форматы прекрасно принимают байты NUL в своих данных, поскольку они просто читают как значение 0. Например, внутри данных изображения во многих форматах оно просто представляет значение 0 в этом канале или пикселе ( в зависимости от размера данных). Не говоря уже о том, что двоичные форматы не обязательно читаются как байты. Нулевой байт может фактически быть частью 2- или 4-байтового значения.
Это проблема с попыткой чтения двоичных данных в виде строки символов. Двоичные данные не должны следовать правилам текста. Вот почему обычно граница данных является отдельной size значение, потому что оно не может заканчиваться на значениях NUL, таких как текст.
Если у вас есть исходные несжатые данные для сравнения, либо загрузите эти данные в память и сравните данные, либо сохраните распакованные данные в файл и используйте инструмент сравнения diff, чтобы выполнить двоичное сравнение файлов.