составная таблица FK базы данных отношения многих ко многим
Я строю API, но я слишком боюсь, что это неправильно с дизайном БД. Я пытаюсь попрактиковаться в адресной книге, где у сотрудника могут быть свои адреса (дом, работа, другое). Так это отношения многих ко многим?
Мой дизайн БД правильный? составная таблица создана для гибкости

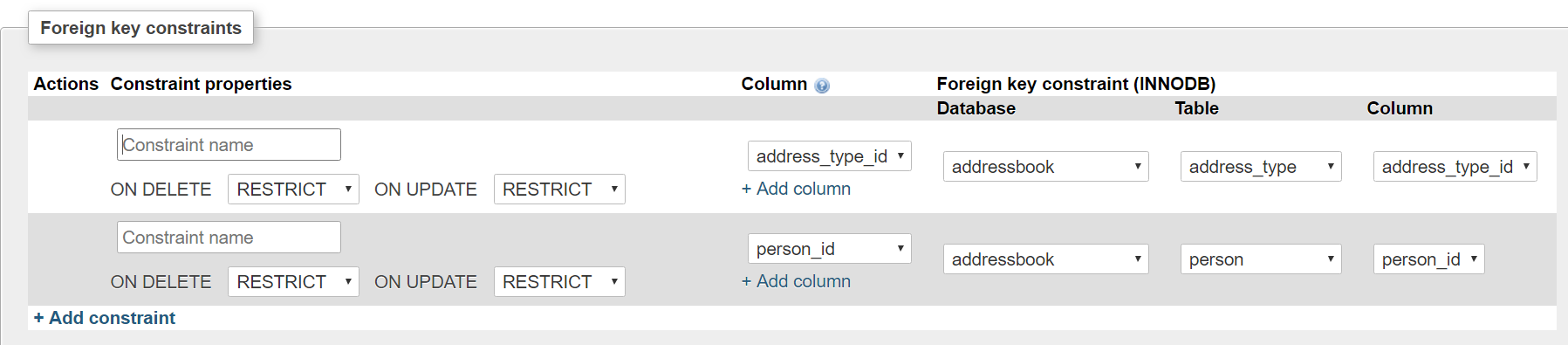
Здесь важны ON DELETE и ON UPDATE? Как установить так, чтобы сотрудник был удален, мы не хотим хранить другие записи в других 2 таблицах?
Решение
Прежде всего, я чувствую себя обязанным добавить, что SO на самом деле не место для этого, я не уверен, но меня не удивит, если есть сайт / доска только для баз данных. Многое из этого — личные предпочтения и мнение.
Вероятно, что-то вроде этого было бы более подходящим местом:
https://dba.stackexchange.com/
Это говорит:
- Я бы изменил ПК просто
idв таблицах, такaddress_type.idэто будет просто id и то же самое для человека. Это просто становится излишним делать person.person_id - Идентификаторы должны быть
INT(10) unsigned AUTO INCREMENT10 — это десять мест, или около 99 999 999 999. У вас не может быть отрицательных идентификаторов, поэтому БД должен обеспечить это. Я делаю 10, потому что этоINT(11)и это сохраняет зарезервированное место. Это не совсем необходимо, но я делаю это по привычке для любого неподписанного int. - Я бы во множественном числе стол на мосту
persons_addresses, Потому что записи вpersonили жеaddressдля одного лица. Записи в таблице мостов предназначены для нескольких объектов. Для меня легче сказать, что это бридж-стол. Все остальные в единственном числе, например, во множественном числе.
Главное для «соглашения об именах» — быть последовательным. если вы делаете {table}_id для ваших идентификаторов, то сделайте их так. Если вы делаете person не делай что-то вроде zipcodes для стола. И даже имена столбцов, если вы делаете person_id тогда не делайте никаких столбцов, таких как FullName, fullName или же Full_name и т. д. Я бы сказал, выбрать путь и придерживаться его, это значительно облегчает процесс написания кода, если вы заранее знаете, что имя таблицы будет единичным. Как я уже сказал, мне нравится множественное использование для таблицы мостов, поскольку вы редко используете их сами по себе.
Для отношений. Вам все равно придется удалить person а также address по отдельности. Но запись в persons_addresses будет обновлен или удален, если вы изменили их на каскад. Я думаю об этом так: таблица, которая определяет отношения, является той, которая получает изменения.
Хотя так и должно быть. Представьте, что у вас есть 2 записи с одним и тем же адресом. Если вы удаляете одного человека, вы не хотите, чтобы адрес удалялся из обоих. Кроме того, вы, вероятно, не хотите, чтобы человек был удален, если его адрес был удален. Так что самое большее должно быть:
person > persons_addresses > address
Я не уверен, существует ли автоматический способ удаления адреса, когда в таблице мостов нет записей. Я всегда просто делал это вручную, но вы могли бы использовать trigger сделать это, если нет лучшего способа.
Для справки:
Триггер — это именованный объект базы данных, который связан с таблицей и который активируется, когда для таблицы происходит определенное событие.
https://dev.mysql.com/doc/refman/5.7/en/triggers.html
Честно говоря, я никогда не делал этого для этого, и я думаю, что триггеры могут не срабатывать при каскадных действиях, я помню кое-что о том, что меня запускают только операторы SQL. В этом случае может быть лучше сделать удаление из person исключительно со спусковым крючком. Таким образом, вы удалили бы человека, сработал бы триггер, и вы бы проверили, использует ли кто-либо еще адрес, если false вы удаляете оба persons_addresses запись и address запись. Если true вы бы только удалили persons_addresses запись.
Еще одна вещь, которую я хотел бы сделать, это разбить адрес, чтобы иметь отдельный zipcode, На моей работе мы приобрели таблицу БД со всеми почтовыми индексами США, в которой указаны все город, штат, округ, почтовый индекс (конечно), а также широта и долгота.
Благодаря этому наша адресная таблица содержит отношение «многие к одному» с почтовыми индексами. Один почтовый индекс может иметь много адресов, связанных с ним. И мы также разбиваем это по состоянию, используя таблицу состояний. Так становится
address
id | street | street2 | zipcode_id
zipcode
id | city | state_id | county | zip | latitude | longitude
state
id | name | abbreviation
Затем, когда пользователи вводят почтовый индекс, он показывает автозаполнение со всей этой информацией.
Тогда последнее, что мы делаем, это нормализуем все ST, N, NW и т.д. Мы решили изменить их на полное имя так ST становится STREET когда сохранено. Мы пошли по этому пути, потому что вы могли бы иметь уличные адреса, как 187 NORTH PARK который будет выглядеть как 187 N PARK что намного хуже 187 PARK NE становление 187 PARK NORTH EAST, Вы будете поражены вариацией адресов, которые я называю «грязью» или «грязью».
Все это в совокупности устраняет множество ошибок. Но, как я сказал в комментариях, мы имеем дело с данными судебных исков, поэтому нам нужно иметь больше точности и, следовательно, больше сложности, чем просто адресную книгу.
Другие решения
Других решений пока нет …