регулярное выражение — RegExp в PHP. Получить текст между круглыми скобками первого уровня
У меня есть два типа строк в одном тексте:
а (Ьс) де (фг) ч
а (BCD (эф) г) ч
Мне нужно получить текст в скобках первого уровня. В моем примере это:
До нашей эры
фг
BCD (эф) г
Я пытался использовать следующее регулярное выражение /\((.+)\)/ с флагом Ungreedy (U):
До нашей эры
фг
BCD (эф
И без этого
до н.э.) де (фг
BCD (эф) г
Оба варианта не делают то, что мне нужно. Может кто знает как решить мою проблему?
Решение
это вопрос в значительной степени есть ответ, но реализации немного неоднозначны. Вы можете использовать логику в принятом ответе без ~s, чтобы получить это регулярное выражение:
\(((?:\[^\(\)\]++|(?R))*)\)
проверенный с этим выводом:
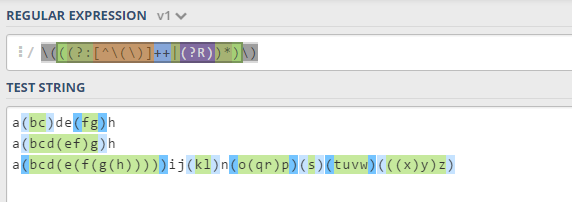
Другие решения
Используйте PCRE Рекурсивный рисунок чтобы сопоставить подстроки во вложенных скобках:
$str = "a(bc)de(fg)h some text a(bcd(ef)g)h ";
preg_match_all("/\((((?>[^()]+)|(?R))*)\)/", $str, $m);
print_r($m[1]);
Выход:
Array
(
[0] => bc
[1] => fg
[2] => bcd(ef)g
)
\( ( (?>[^()]+) | (?R) )* \)
Сначала это соответствует открывающей скобке. Тогда это соответствует любому числу
подстроки, которые могут быть последовательностью без скобок или
рекурсивное соответствие самого шаблона (то есть правильно заключенное в скобки
подстрока). Наконец, есть закрывающая скобка.
Технические предостережения:
Если есть больше чем 15 захватывая скобки в шаблоне, PCRE имеет
чтобы получить дополнительную память для хранения данных во время рекурсии, что он делает
используя pcre_malloc, впоследствии освобождая его через pcre_free. Если нет
память может быть получена, она сохраняет данные для первых 15 захватов
только круглые скобки, так как нет способа выдать ошибку нехватки памяти
изнутри рекурсии.
Пожалуйста, вы можете попробовать это:
preg_match("/\((.+)\)/", $input_line, $output_array);
Протестируйте этот код в http://www.phpliveregex.com/
Regex: \((.+)\)
Input: a(bcd(eaerga(er)gaergf)g)h
Output: array(2
0 => (bcd(eaerga(er)gaergf)g)
1 => bcd(eaerga(er)gaergf)g
)