Реализация дерева префиксов Php в сравнении с массивом ассоциаций
UPD: Я перенес оригинальный вопрос в https://codereview.stackexchange.com/questions/127055/building-tree-graph-from-dictionary-performance-issues
Вот короткая версия, без кодов.
Я пытаюсь построить дерево префиксов из словаря. Итак, используя следующий словарь 'and','anna','ape','apple'График должен выглядеть так:
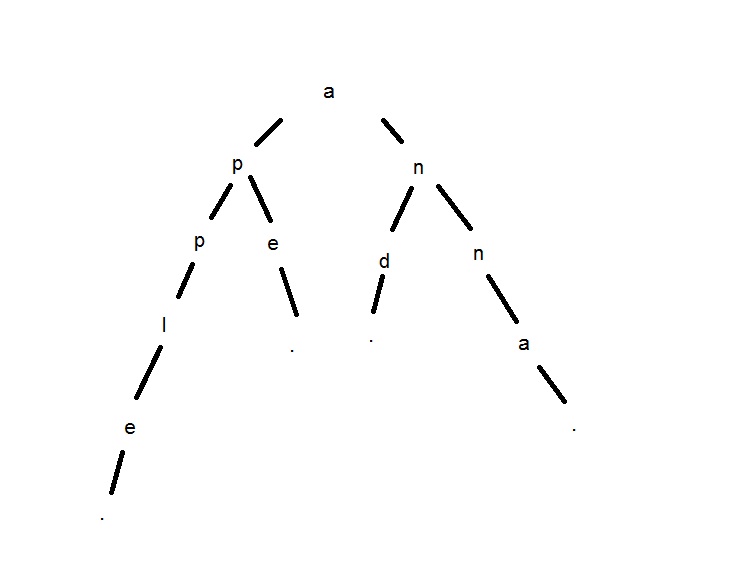
Я попробовал 2 подхода: использование ассоциативного массива и использование самописных классов дерева / узла.
Примечание: оригинальный словарь составляет около 8 МБ и содержит> 600000 слов.
Вопрос: Есть ли хороший (быстрый / эффективный) способ сделать это?
Я пробовал до сих пор:
-
PHP ассоциативные массивы (они не очень гибки для будущей работы с этим графом).
-
самописные классы Tree / Node (проблемы с производительностью — время выполнения увеличивается в 7 раз, использование памяти увеличивается в 2 раза даже без реализации чего-либо, кроме простого
insertingфункция).
Образцы кодов доступны на codereview (самая первая ссылка в вопросе)
Решение
Пока я перешел на C ++ и получил хороший ответ на Просмотр Кода, Я просто отвечу на свой вопрос здесь.
Есть еще один способ сделать это более экономичным за счет увеличения использования памяти (это не очень большое увеличение по сравнению с «array из arrayс arrays … «подход). Подход называется» двойной массив три «, и вы можете прочитать информацию по этой теме Вот и прочитайте вышеупомянутый ответ на просмотр кода, чтобы увидеть пример реализации.
Это более эффективно по времени, но при этом обеспечивает меньшую гибкость / удобство для будущего использования Trie (по сравнению с подходом ООП).
Итак, окончательный ответ на этот вопрос для меня: «php — не лучший инструмент для работы с действительно большими попытками».
Другие решения
Других решений пока нет …