Разделение таблицы истории продуктов Big MySQL?
Я занимаюсь разработкой системы управления складом, написанной на php, laravel framework, mariadb. Чтобы получить всю информацию о каждом продукте, мы используем таблицу «истории» продуктов, в которой записываются все действия, предпринятые с определенным продуктом. Эта таблица начала очень быстро расширяться, и теперь у нас есть ~ 15 миллионов строк таблицы innoDB, которая начала работать медленно, особенно при запуске функции, которая требует полного анализа того, сколько продуктов продано, создано, выброшено и т. Д., Затем она занимает все 15 миллионов строк по одному запросу .. Итак, я начал искать способы управления этой большой таблицей, потому что индексирование больше не работает.
Я начинаю думать о разделении / разбиении этой таблицы по дате, может быть, действие? так что, может быть, у кого-то есть опыт в этом вопросе и он может поделиться со мной некоторыми советами? Большое спасибо за любую помощь!
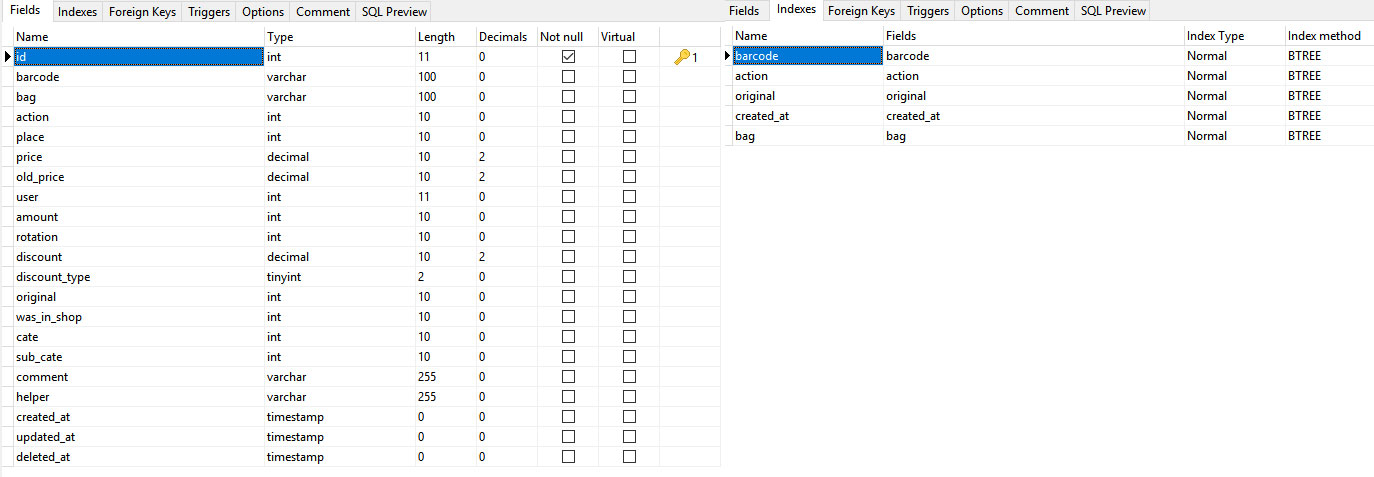
CREATE TABLE `history` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`barcode` varchar(100) DEFAULT NULL,
`bag` varchar(100) DEFAULT NULL,
`action` int(10) unsigned DEFAULT NULL,
`place` int(10) unsigned DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`old_price` decimal(10,2) DEFAULT NULL,
`user` int(11) DEFAULT NULL,
`amount` int(10) DEFAULT NULL,
`rotation` int(10) unsigned DEFAULT NULL,
`discount` decimal(10,2) DEFAULT NULL,
`discount_type` tinyint(2) unsigned DEFAULT NULL,
`original` int(10) unsigned DEFAULT NULL,
`was_in_shop` int(10) unsigned DEFAULT NULL,
`cate` int(10) unsigned DEFAULT NULL COMMENT 'grupe',
`sub_cate` int(10) unsigned DEFAULT NULL,
`comment` varchar(255) DEFAULT NULL,
`helper` varchar(255) DEFAULT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`deleted_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `barcode` (`barcode`),
KEY `action` (`action`),
KEY `original` (`original`),
KEY `created_at` (`created_at`),
KEY `bag` (`bag`)
) ENGINE=InnoDB AUTO_INCREMENT=16274267 DEFAULT CHARSET=utf8
например запрос:
select cate,
SUM(amount) AS amount, SUM(IF(discount>0,(price*amount)-discount,
(price*amount))) AS sum, SUM(IF(discount>0,IF(discount_type=1,
(discount*price)/100,discount),0)
) AS discount from history
where (history.action = '4'
and history.created_at >= '2017-11-01 00:00:00'
and history.created_at <= '2017-11-23 23:59:59'
)
and LENGTH(barcode) > 7
and history.deleted_at is null
group by cate
этот запрос используется для получения информации о сумме, сумме, скидке о проданных товарах (действие 4), в данном примере это информация между 2017-11-01 и 2017-11-23 и EXPLAIN дает мне это:
id - 1
select_type - SIMPLE
table - history
type - ref
possible_keys - action,created_at
key - action
key_len - 5
ref - const
rows - 1444272
Extra - Using where; Using temporary; Using filesort
Таким образом, для таблицы, содержащей данные за 2017-01-01 гг., требуется 1,5 млн. строк, поэтому через 2 года потребуется 3 млн. строк и т. д., когда мне понадобится только информация о проданных продуктах за 2017-2011 гг. И у меня много других запросов, похожих на этот.
Решение
- Используйте меньшие типы данных (уменьшение размера таблицы помогает повысить производительность)
INTзанимает 4 байта; Другие размеры доступны. PARTITIONingделает не по сути обеспечивают любую производительность.history.deleted_at is nullрассмотреть вопрос об удалении строк.- Узнайте о «составных» индексах, таких как
INDEX(action, created_at), (За один раз используется только один индекс.)
Большое улучшение достигается за счет создания и поддержки сводных таблиц; увидеть http://mysql.rjweb.org/doc.php/summarytables . Затем выполните запросы к ним. И большинство индексов может уйти.
Исправить некоторые из них; тогда я могу помочь тебе дальше.
Больше
Комментарий спрашивает о том, как поддерживать идентификатор сводной таблицы двумя различными способами. Любой из них может быть жизнеспособным, в зависимости от более, но пока не уточненных деталей:
INSERT INTO Factтаблицы, и немедленно используйте IODKU для вставки или обновления сводной таблицы.- Выполнять суммирование «по требованию» — когда пользователь запрашивает данные, сначала запустите
INSERT .. SELECT ..захватить еще не суммированные строки и поместить итоги / промежуточные итоги в итоговую таблицу.
Последний вариант работает, но есть две вещи, на которые следует обратить внимание:
- Если в течение долгого времени не появляется ни один пользователь, то суммирование может быть дорогостоящим. Простое решение состоит в том, чтобы периодически выполнять работу cron, «догоняя». Обязательно заблокируйте код, чтобы cron и пользователь не обновляли одни и те же строки одновременно.
- Если в итоговой таблице есть «естественный»
PRIMARY KEYтакие как дата (день или час) и пара значений измерений, то у вас возникли проблемы сINSERT, Либо избегайте этого в качестве PK (тем самым приводя к нескольким строкам, что не так уж и плохо), либо используйте IODKU в формеINSERT ... ON DUPLICATE KEY ... SELECT ... GROUP BY ...;и использоватьVALUES(xx)функция.
Другие решения
Других решений пока нет …