Поврежденные данные с использованием UTF-8 и mb_substr
Я получаю данные из поля MySQL db, varchar (255) utf8_general_ci и пытаюсь записать текст в PDF с помощью PHP. Мне нужно определить длину строки в PDF, чтобы ограничить вывод текста в таблицу. Но я заметил, что на выходе mb_substr/substr это действительно странно.
Например:
mb_internal_encoding("UTF-8");
$_tmpStr = $vfrow['title'];
$_tmpStrLen = mb_strlen($vfrow['title']);
for($i=$_tmpStrLen; $i >= 0; $i--){
file_put_contents('cutoffattributes.txt',$vfrow['field']." ".$_tmpStr."\n",FILE_APPEND);
file_put_contents('cutoffattributes.txt',$vfrow['field']." ".mb_substr($_tmpStr, 0, $i)."\n",FILE_APPEND);
}
выводит это:
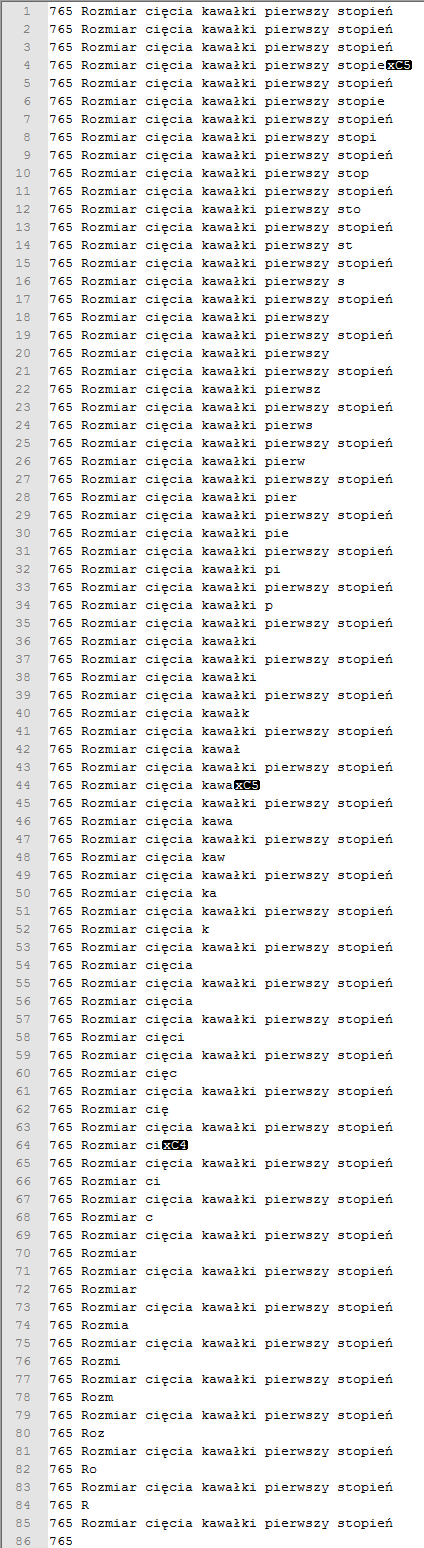
База данных:
Мой вопрос: откуда взялся этот дополнительный персонаж?
Решение
- Вы должны убедиться, что вы действительно получаете данные из базы данных в кодировке UTF-8, правильно настроив кодировку соединения. Это зависит от вашего адаптера базы данных, см. UTF-8 полностью для деталей.
-
Вы должны сказать своим
mb_функции, что данные находятся в UTF-8, чтобы они могли обрабатывать его правильно. Либо установите это глобально для всех функций, использующихmb_internal_encoding, или передать$encodingпараметр вашей функции, когда вы ее вызываете:mb_substr($_tmpStr, 0, $i, 'UTF-8')
Другие решения
Дополнительный символ является первой частью двухбайтовой последовательности UTF-8. У вас могут быть проблемы с внутренним кодированием многобайтовых строковых функций. Ваш код обрабатывает текст как фиксированную 1-байтовую кодировку. ń в UTF-8, гекс C5 84, рассматривается как Ĺ « в CP-1250 и Ĺ[IND] в ISO-8859-2, два символа.
Попробуйте выполнить это в верхней части скрипта:
mb_internal_encoding("UTF-8");
Помимо таблицы и поля, установленного в UTF-8, необходимо установить mysqli_set_charset ( ‘UTF-8’) в UTF-8 также (если вы используете mysqli).
Тоже пробовал?
$_tmpStr = utf8_encode( $vfrow['title'] );