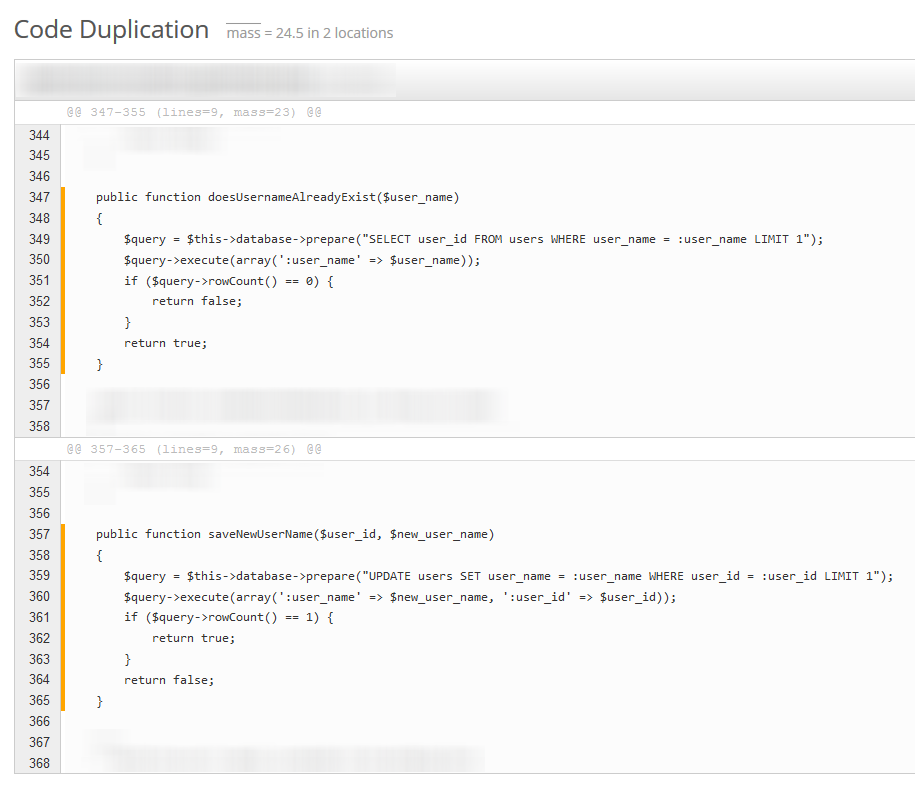
Почему Scrutinizer говорит «дублирующий код»? когда код совершенно другой?
Почему Scrutinizer говорит «дублирующий код», когда эти два метода совершенно разные? Является ли это ложноположительным или Scrutinizer действительно хочет увидеть это более абстрактно?
Решение
Я предполагаю, что они делают то, что называется «нормализацией», то есть текст разбивается на более мелкие части (называемые токенами), а затем некоторые из этих токенов заменяются другим текстом, чтобы сделать их одинаковыми. Например, все числа и строки нормализованы, чтобы быть тем же самым числом / строкой.
Это гарантирует, что вы сможете найти клоны, которые отличаются только литералами, что полезно, поскольку обычно это означает, что вы можете извлечь служебный метод, который принимает эти различные литералы в качестве параметра и, таким образом, уменьшает избыточность в вашем коде.
Поэтому для детектора клонов ваш код будет выглядеть примерно так (весь текст в верхнем регистре нормализован):
public function IDENTIFIER($VARIABLE1) {
$VARIABLE2 = $this->database->prepare(STRING);
$VARIABLE2->execute(ARRAY_EXPRESSION);
if ($VARIABLE2->rowCount() == INTEGER) {
return BOOLEAN;
}
return BOOLEAN;
}
Обе функции будут нормализованы к этому точно такому же представлению, и детектор клонов примет это как дублированный код.
Единственный разумный рефакторинг, который я вижу для вашего кода, — это извлечь вспомогательную функцию, которая обрабатывает подготовку и выполнение запроса и возвращает количество строк:
public function executeRowCountQuery($query_string, $query_variables) {
$query = this->database->prepare($query_string);
$query->execute($query_variables);
return $query->rowCount();
}
Это может иметь смысл, если у вас много разных запросов, которые заинтересованы только в количестве строк.
Другие решения
Лучше вообще отключить проверку в .scrutinizer.yml
checks:
php:
duplication: false