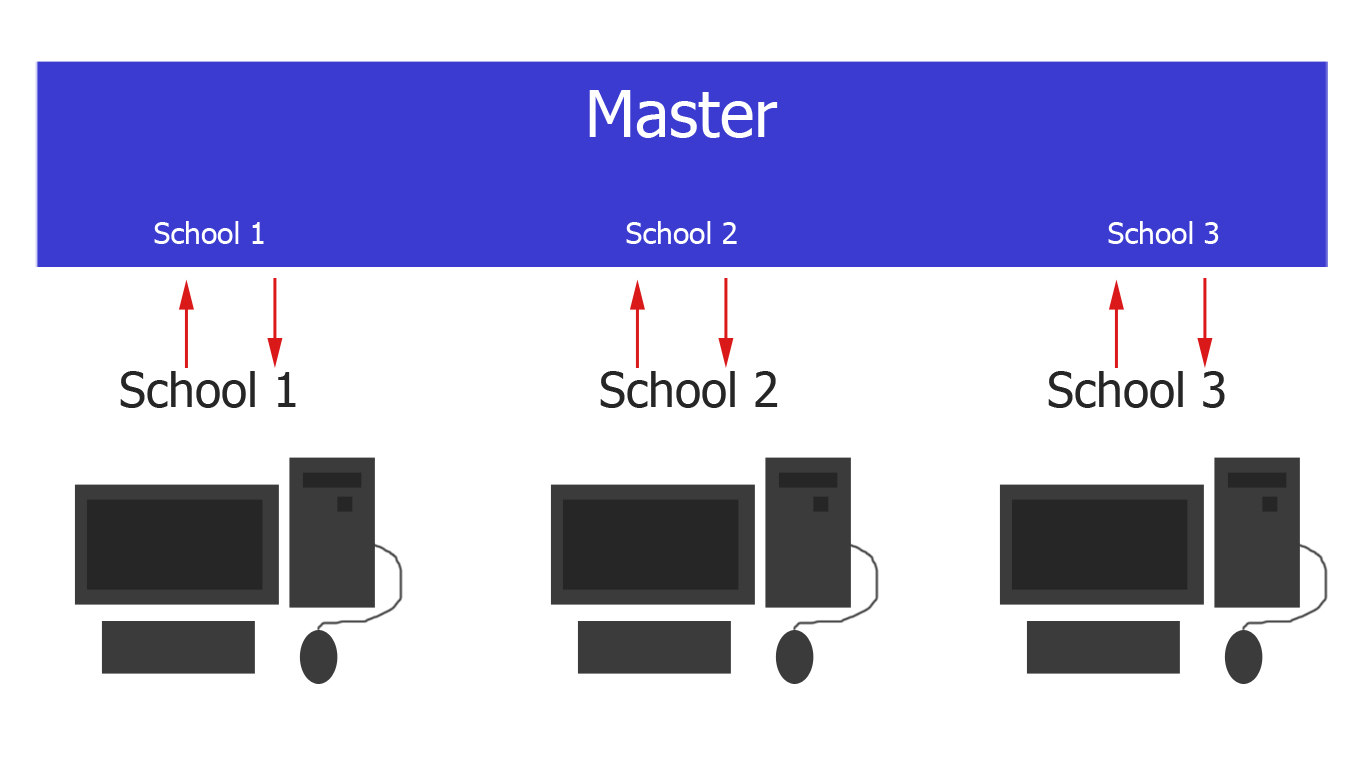
Копирование главной базы данных на разные подчиненные
У меня есть основная база данных, которая будет облачным сервером, который состоит из разных школ.
Тип панели инструментов, в которой указаны детали каждой школы. Можете редактировать свою информацию и другие данные.
Теперь эти школы развернуты в соответствующих школах, которые будут локальным сервером.
Тип панели мониторинга, который может редактировать только определенную школу, развернутую на локальном сервере. Можете редактировать свою информацию и другие данные.
Теперь я хочу синхронизировать cloud to local server в соответствующей школе, если что-то изменилось. Это также касается local to cloud server,
Примечание: если вы когда-либо пробовали Evernote, он может редактировать информацию заметок на любом устройстве, которое вы используете, и при этом иметь возможность
синхронизировать, когда у вас есть Интернет или вручную нажмите синхронизировать.Когда на локальном сервере нет подключения к интернету и редактируются некоторые данные в школе. Когда Интернет подключен, данные с локального и облачного сервера должны быть синхронизированы.
Это логика, которую я преследую.
Кто-нибудь пролил бы свет на меня, с чего начать? Я не мог придумать никакого решения, которое бы подходило моей проблеме.
Я также думаю об использовании php для цикла foreach по всей таблице и данным, которые соответствуют текущей дате и времени. Но я знаю, что это было бы так плохо.
Отредактировано: Я удалил ссылки / посты других вопросов SO по этому вопросу.
Колышки приложения, которые я нашел,
- Evernote
- Todoist
Серверы:
- Локальный сервер: Windows 10 (развернут в школах)
- Облачный сервер: вероятно, какой-то выделенный хостинг, который использует
phpmyadmin
Не для того, чтобы быть разборчивым, но, надеюсь, ответом будет то, что вы говорите с новичком, чтобы освоить процесс обработки базы данных. У меня нет опыта для этого.
Решение
Когда мы делали это, мы бы:
- Убедитесь, что в каждой таблице, которую мы хотим синхронизировать, есть столбцы даты и времени для Created; Модифицированный; & Удаленные. У них также будет логический столбец isDeleted (поэтому вместо того, чтобы физически удалять записи, мы помечаем его как true и игнорируем в запросах). Это означает, что мы можем запросить любые записи, которые были удалены с определенного времени, и вернуть массив этих удаленных идентификаторов.
- В каждой БД (Master и Slave) создайте таблицу, в которой хранится дата последней успешной синхронизации. В мастере эта таблица хранит несколько записей: по 1 для каждой школы, но в ведомом устройстве ей просто нужна 1 запись — в последний раз, когда она синхронизировалась с мастером.
В вашем случае очень часто каждый из рабов будет:
-
Вызовите веб-сервис (URL) мастера, скажем, под названием «helloMaster». Он передал бы название школы (или некоторый конкретный идентификатор), в последний раз, когда они успешно синхронизировались с мастером, детали аутентификации (для безопасности) и ожидал ответа от мастера о том, имел ли мастер какие-либо обновления для школы с этой даты и времени предоставлена. На самом деле суть здесь просто в том, чтобы найти подтверждение, что мастер доступен и слушает (т. Е. Интернет все еще работает).
-
Затем ведомый будет вызывать другой веб-сервис, скажем, с именем «sendUpdates». Это снова передало бы название школы, последняя успешная синхронизация (плюс данные аутентификации безопасности) & три массива для любых добавленных, обновленных и удаленных записей с момента последней синхронизации. Мастер просто подтверждает получение. Если квитанция была подтверждена, то подчиненное устройство переходит к шагу 3, в противном случае ведомое устройство снова попытается выполнить шаг 1 после некоторой паузы. Так что теперь у Мастера есть обновления от раба. Примечание: мастер должен решить, как объединить любые записи, если есть конфликты с его ожидающими ведомыми обновлениями.
-
Затем ведомое устройство вызывает веб-сервис, скажем, «getUpdates». Он передает название школы, последнюю успешную синхронизацию, данные аутентификации безопасности, & мастер затем возвращает ему три массива для любых добавленных, обновленных и удаленных записей, которые он имеет, которые, как ожидается, будут применять подчиненные к своей базе данных.
-
Наконец, когда ведомое устройство пытается обновить свои записи, оно уведомляет мастера об успехе / неудаче через другой веб-сервис, скажем, «updateStatus». В случае успеха мастер вернет новую дату синхронизации для ведомого, который будет храниться (это будет точно соответствовать дате, которую мастер хранит в своей таблице). Если это не удается, то ошибка регистрируется в мастере, и мы возвращаемся к шагу 1 после паузы.
Я упустил некоторые детали обработки ошибок, получения точного времени на всех устройствах (могут быть задействованы разные часовые пояса) и некоторых других мелочах, но в этом суть.
Я могу внести уточнения, подумав об этом больше (или другие могут отредактировать мой пост).
Надеюсь, это поможет по крайней мере.
Другие решения
Я предложу вам воспользоваться Тривиальным Решением, которое, по моему мнению:
- Создайте SQLlite или любую базу данных (MySQL или ваш выбор) на локальном сервере
- Сохраняйте постоянно работающий поток, который будет пинговать (совершать вызов API) вашу базу данных Master каждые 5 минут (зависит от того, какая задержка принята)
- С помощью этой темы вы можете определить, подключены ли вы к Интернету или нет.
-
Если подключен к интернету
a) Отправлять локальные изменения с запросом на главный сервер, этот главный сервер является сервером приложений, который будет способен обновлять изменения локальных компьютеров в школе (вы получили эти изменения посредством вызова API) в главную базу данных после определенных проверок в соответствии с к использованию вашего приложения.
b) Получать обновленные изменения от сервера после вызова API, эти изменения обрабатываются после разрешения конфликтов (например, если данные на школьном сервере были обновлены раньше, чем данные, обновленные в основной базе данных, и такую, которую вы примете в соответствии с вашими требованиями).
-
Если вы не подключены к Интернету, сохраняйте изменения в локальной базе данных и отражайте эти изменения в приложении, которое работает в школе, но когда вы подключаетесь, перенесите эти изменения на главный сервер и вытяните фактические изменения, которые применимы с главного сервера.
Это сложно сделать самостоятельно, но если масштаб невелик, я бы предпочел реализовать собственные API для приложений баз данных, которые будут подключаться таким образом.
Лучшим решением будет использование Google Firebase, базы данных в реальном времени, которая асинхронно обновляется при любых изменениях на любом компьютере, но может стоить дороже, если она действительно не требуется. Но да, это действительно даст вам возможности редактирования в реальном времени типа Evernote для ваших систем баз данных.
Это не проблема, которая может быть решена путем репликации базы данных.
Вообще говоря, репликация базы данных может работать в одном из двух режимов:
-
Репликация Master / Slave, которую использует MySQL. В этом режиме все записи должны быть направлены на один «главный» сервер, и все базы данных реплик получают поток изменений от главного.
Это не соответствует вашим потребностям, так как записи могут быть сделаны только мастеру. (Изменение одной из реплик напрямую приведет к тому, что она будет постоянно не синхронизирована с мастером.)
-
Репликация на основе кворума, которая используется некоторыми более новыми базами данных. Все реплики базы данных соединяются друг с другом. Поскольку по крайней мере половина всех реплик подключена (то есть кластер достиг «кворума»), записи могут быть сделаны в любую из активных баз данных и будут распространяться на все другие базы данных. База данных, которая не подключена, будет обновлена, когда она присоединится к кворуму.
Это также не соответствует вашим потребностям, так как отключенная реплика не может быть записана в. Хуже того, более половины всех реплик, отключенных от мастера, предотвратят запись оставшихся баз данных в любую из них!
Что вам нужно, это какое-то решение для синхронизации данных. Любое решение потребует некоторой логики — которую вам придется написать! — разрешать конфликты. (Например, если запись изменяется в базе данных master, когда локальная реплика школы отключена, и там же изменяется и та же запись, вам потребуется какой-то способ примирить эти различия.)
Не нужно никаких сложных настроек или API. MySQL позволяет легко реплицировать вашу базу данных. MySQL обеспечит правильную и своевременную репликацию и всякий раз, когда будет доступен интернет. (и это тоже быстро)
Есть:
- Ведущий-ведомый: Ведущий редактирует ведомые чтения или, другими словами, одностороннюю синхронизацию от ведущего к ведомому.
- Мастер — Мастер: Мастер1 редактирует, мастер2 читает и редактирует, или, другими словами, двустороннюю синхронизацию. Оба сервера будут выдвигать и извлекать обновления.
Предполагая, что ваш облачный сервер имеет схему для каждой школы, и каждая схема доступна по своему имени пользователя и паролю. т.е. db_school1, db_school2
Теперь у вас есть возможность реплицировать только выбранную схему базы данных из вашего облака на локальный мастер. В вашем случае школа будет только местным мастером «сделать копию db_school1»
в случае, если вы хотите реплицировать только определенную таблицу, MySQL также имеет эту опцию «replicate-do-table»
Реальный процесс репликации очень прост, но может быть очень глубоким, когда у вас разные сценарии.
Несколько вещей, которые вы хотите записать, идентификаторы сервера, различные значения автоинкремента на каждом сервере, чтобы избежать конфликтов с новыми записями. Т.е. Master1 генерирует записи по нечетному номеру, Master 2 по четным числам, поэтому не будет повторяющихся проблем первичного ключа. Предупреждение о сбое сервера / мониторинг, пропуск ошибок
Я не уверен, что вы используете Linux или Windows, я написал простое приложение на c #, которое проверяет, не копирует ли какой-либо мастер или не останавливается по какой-либо причине, и отправляет электронную почту. мониторинг имеет решающее значение!
Вот несколько ссылок для мастер-репликации:
https://www.howtoforge.com/mysql_master_master_replication
https://www.digitalocean.com/community/tutorials/how-to-set-up-mysql-master-master-replication
Также стоит прочитать эту оптимизированную информацию о репликации на уровне таблиц:
https://dba.stackexchange.com/questions/37015/how-can-i-replicate-some-tables-without-transferring-the-entire-log
надеюсь это поможет.
Редактировать:
Оригинальная версия этого ответа предложена MongoDB; но с дальнейшим чтением MongoDB не так надежен с хитрыми интернет-соединениями. CouchDB предназначен для автономных документов, а это то, что вам нужно, хотя получить гонг сложнее, чем MongoDB, к сожалению.
Оригинал:
Я бы предложил не использовать MySQL, а развернуть хранилище документов, предназначенное для репликации, например CouchDB — если вы не идете на коммерческие службы кластеризации MySQL.
Будучи любителем мощи MySQL, мне трудно предложить вам использовать что-то другое, но в этом случае вам действительно следует.
Вот почему —
Проблемы с использованием репликации MySQL
Почему MySQL имел хорошую репликацию (и это, скорее всего, то, что вы должны использовать, если вы синхронизируете базу данных MySQL — как рекомендовано другими), есть некоторые вещи, на которые следует обратить внимание.
- Столкновения с «уникальным ключом» вызовут сильную головную боль; большинство
вероятная причина этого — «автоматическое увеличение» идентификаторов, которые являются общими в
MySQL-приложения (не используйте их для синхронизации, если нет
четкие отношения «чтение + запись» -> «только для чтения», которых нет
в твоем случае.) - Первичные ключи должны генерироваться каждым сервером, но уникальными для всех серверов. Возможно, добавив сочетание идентификатора сервера и уникального идентификатора для этого сервера (Server1_1, Server1_2, Server1_3 и т. Д. Не будут конфликтовать с Server2_1)
- Синхронизация MySQL поддерживает только в пути, если вы не посмотрите на их решения для кластеризации (https://www.mysql.com/products/cluster/).
Проблемы делают это «вручную» с отметкой времени записи.
Другой ответ рекомендует вести учет «Время обновлено». В то время как я сделал этот подход, есть некоторые большие ошибки, чтобы быть осторожным.
- Конфликты «уникального ключа» (как упоминалось выше; те же проблемы — не используйте их, кроме первичных ключей, и генерируйте первичные ключи, уникальные для сервера)
- Несколько обновлений на нескольких серверах должны быть точно синхронизированы по времени
и столкновения обрабатываются в соответствии с правилами. Это может быть головной болью. - Что происходит, когда обновления поступают не по порядку; какие поля были обновлены, а какие нет? Возможно, вам не нужно обновлять всю запись, но как вы узнали?
- Если необходимо, попробуйте одно из коммерческих решений, как указано в ответах. https://serverfault.com/questions/58829/how-to-keep-multiple-read-write-db-servers-in-sync а также https://community.spiceworks.com/topic/352125-how-to-synchronize-multiple-mysql-servers а также Стратегия синхронизации базы данных из нескольких мест в центральную базу данных и наоборот (и т. д. — Google для более)
Проблемы делают это «вручную» с журналированием.
Журналирование ведет отдельный учет того, что изменилось и когда. «База данных X, таблица Y, поле Z была обновлена до значения A в момент времени B» или «в таблицу A была добавлена новая запись с этими деталями […]». Это позволяет вам лучше контролировать, что обновлять.
- если вы посмотрите на методы синхронизации базы данных, это на самом деле то, что происходит в фоновом режиме; в случае MySQL он ведет двоичный журнал обновлений
- вы только когда-либо делитесь журналом, а не оригинальной записью.
- Когда другой сервер получает запись в журнале, он имеет гораздо более полную картину того, что произошло до / после, и может воспроизводить обновления и гарантирует, что вы получите правильные данные.
- проблемы возникают, когда журналирование / база данных выходят из Sync (MySQL на самом деле боль, когда это происходит!). У вас должен быть готовый к обновлению сценарий «обновления», который находится вне журналирования, который синхронизирует БД с мастером.
- Это сложно. Так…
Решение: использование хранилища документов, предназначенного для репликации, например, MongoDB
Имея все это в виду, почему бы не использовать хранилище документов, которое уже все это делает для вас? CouchDB имеет поддержку и обрабатывает все журналирование и синхронизацию (http://docs.couchdb.org/en/master/replication/protocol.html).
Есть и другие, но я верю, что у вас будет меньше проблем и ошибок, чем с другими решениями.
Мастер-мастер репликации в MySQL может быть выполнен без нарушения ключа при использовании auto_increment. Вот ссылка, которая объясняет, как.
Если у вас есть таблицы без первичных ключей, я не уверен, что произойдет (я всегда включаю первичные ключи auto_increment в таблицы)
http://brendanschwartz.com/post/12702901390/mysql-master-master-replication
Auto-increment-offset и auto-increment-increment влияют на значения auto_increment, как показано в примерах конфигурации из статьи …
server_id = 1
log_bin = /var/log/mysql/mysql-bin.log
log_bin_index = /var/log/mysql/mysql-bin.log.index
relay_log = /var/log/mysql/mysql-relay-bin
relay_log_index = /var/log/mysql/mysql-relay-bin.index
expire_logs_days = 10
max_binlog_size = 100M
log_slave_updates = 1
auto-increment-increment = 2
auto-increment-offset = 1
server_id = 2
log_bin = /var/log/mysql/mysql-bin.log
log_bin_index = /var/log/mysql/mysql-bin.log.index
relay_log = /var/log/mysql/mysql-relay-bin
relay_log_index = /var/log/mysql/mysql-relay-bin.index
expire_logs_days = 10
max_binlog_size = 100M
log_slave_updates = 1
auto-increment-increment = 2
auto-increment-offset = 2