Как улучшить производительность запросов (используя результаты команды объяснения, например)
Итак, я в настоящее время запускаю этот запрос. Однако при запуске вне phpmyadmin это вызывает ошибку тайм-аута 504. Я думаю, что это связано с тем, насколько эффективно количество строк возвращается или обращается к запросу.
Я не очень опытен с MySQL, и это было лучшее, что я мог сделать:
SELECT
s.surveyId,
q.cat,
SUM((sac.answer_id*q.weight))/SUM(q.weight) AS score,
user.division_id,
user.unit_id,
user.department_id,
user.team_id,
division.division_name,
unit.unit_name,
dpt.department_name,
team.team_name
FROM survey_answers_cache sac
JOIN surveys s ON s.surveyId = sac.surveyid
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
JOIN cluster c ON sc.cluster_id = c.cluster_id
JOIN user ON user.user_id = sac.user_id
JOIN questions q ON q.question_id = sac.question_id
JOIN division ON division.division_id = user.division_id
LEFT JOIN unit ON unit.unit_id = user.unit_id
LEFT JOIN department dpt ON dpt.department_id = user.department_id
LEFT JOIN team ON team.team_id = user.team_id
WHERE c.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
GROUP BY user.team_id, s.surveyId, q.cat
ORDER BY s.surveyId, user.team_id, q.cat ASC
Проблема, которую я получаю с этим запросом, состоит в том, что, когда я получаю правильный результат, он выполняется быстро (скажем, + -500 мс), но когда в результате получается вдвое больше строк, это занимает более 5 минут, а затем вызывает таймаут 504.
Другая проблема заключается в том, что я не создавал эту базу данных сам, поэтому я не устанавливал индексы самостоятельно. Я думаю об их улучшении, и поэтому я использовал команду объяснения:
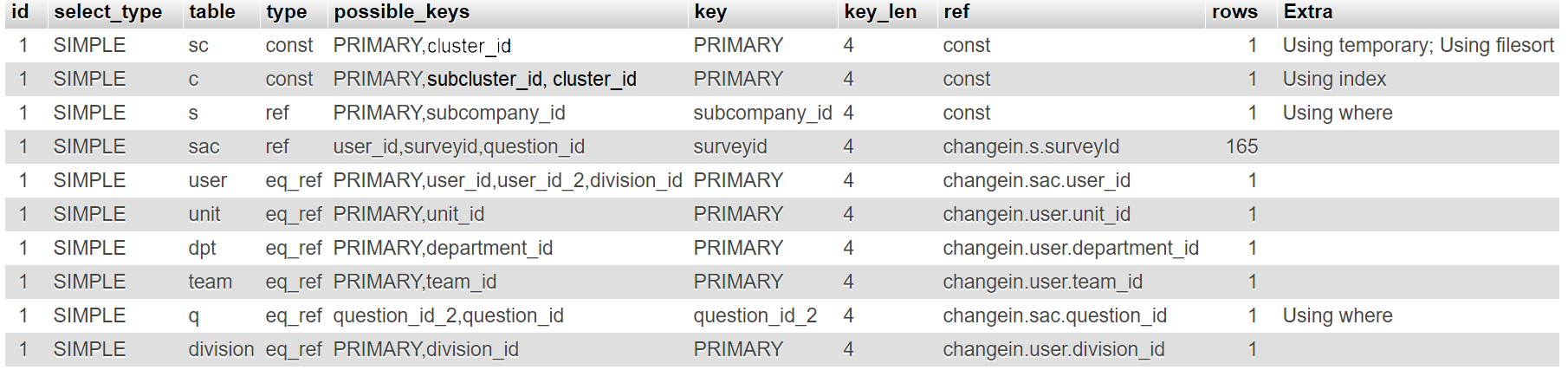
Я вижу много первичных ключей и пару двойных индексов, но я не уверен, сильно ли это повлияет на производительность.
РЕДАКТИРОВАТЬ: Этот кусок кода занимает все время выполнения:
$start_time = microtime(true);
$stmt = $conn->query($query); //query is simply the query above.
while ($row = $stmt->fetch_assoc()){
$resultSurveys["scores"][] = $row;
}
$stmt->close();
$end_time = microtime(true);
$duration = $end_time - $start_time; //value typically the execution time #reallyHigh...
Итак, мой вопрос: Можно ли (значительно?) Улучшить производительность запроса, изменив ключи базы данных, или я должен разделить свой запрос на несколько небольших запросов?
Любая помощь очень ценится!
Постскриптум Если вы считаете, что в моем вопросе чего-то не хватает, не просто понизьте голос, а напишите комментарий ниже или предложите изменить, и я постараюсь добавить необходимую информацию!
Решение
Результат EXPLAIN показывает признаки проблемы
Использование временных файлов, использование файловой сортировки: для сортировки ORDER BY необходимо создать временные таблицы.
На 3-й строке для пользовательской таблицы type это все, key а также ref NULL: означает, что для получения результатов необходимо каждый раз сканировать всю таблицу.
Предложения:
- добавить индексы для user.cluster_id и все поля, включенные в предложения ORDER BY и GROUP by. Имейте в виду, что пользовательская таблица, кажется, находится под
changeinбаза данных (кросс-запрос базы данных). - Добавить индексы для пользовательских столбцов, участвующих в JOIN.
- Добавить индекс в s.survey_id
- Если возможно, сохраняйте одинаковую последовательность для предложений GROUP BY и ORDER BY
- Согласно принял ответ на этот вопрос переместите JOIN на пользовательской таблице на первую позицию в очереди соединения.
- Внимательно прочитайте это официальная документация. Вам может потребоваться оптимизировать конфигурацию сервера.
PS: оптимизация запросов — это искусство, требующее терпения и кропотливой работы. Никакой серебряной пули для этого.
Добро пожаловать в изобразительное искусство оптимизации MySQL!
Другие решения
Вы можете попробовать что-то вроде этого (хотя это не практично для меня, чтобы проверить это)
SELECT
sac.surveyId,
q.cat,
SUM((sac.answer_id*q.weight))/SUM(q.weight) AS score,
user.division_id,
user.unit_id,
user.department_id,
user.team_id,
division.division_name,
unit.unit_name,
dpt.department_name,
team.team_name
FROM survey_answers_cache sac
JOIN
(
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
) AS v ON v.surveyid = sac.surveyid
JOIN user ON user.user_id = sac.user_id
JOIN questions q ON q.question_id = sac.question_id
JOIN division ON division.division_id = user.division_id
LEFT JOIN unit ON unit.unit_id = user.unit_id
LEFT JOIN department dpt ON dpt.department_id = user.department_id
LEFT JOIN team ON team.team_id = user.team_id
GROUP BY user.team_id, v.surveyId, q.cat
ORDER BY v.surveyId, user.team_id, q.cat ASC
Надеюсь, я ничего не испортила.
В любом случае, идея заключается в том, что во внутреннем запросе вы выбираете только те строки, которые вам нужны, в зависимости от вашего условия where. Это создаст меньшую таблицу tmp, так как она тянет только 2 поля на оба целых.
Затем во внешнем запросе вы присоединяетесь к таблицам, из которых вы фактически извлекаете остальные данные, порядок и группу. Таким образом, вы сортируете и группируете по меньшему набору данных. И ваше предложение where может работать самым оптимальным образом.
Возможно, вам даже удастся опустить некоторые из этих таблиц в качестве единственного извлечения данных из нескольких из них, но не видя полной схемы и ее взаимосвязи, трудно сказать.
Но, вообще говоря, эта часть (подзапрос)
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
Это то, что напрямую зависит от вашего предложения WHERE. Посмотрите, чтобы мы могли оптимизировать эту часть, а затем использовать ее для объединения остальных данных, которые вам нужны.
Пример удаления таблиц можно легко вывести из приведенного выше, рассмотрим это
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
WHERE
sc.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
c Таблица cluster никогда не используется для извлечения данных, только для где. Так не
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=?
Так же, как или эквивалентно
WHERE
sc.cluster_id=?
И поэтому мы можем полностью устранить это соединение.
Я думаю, что проблема происходит, когда вы добавляете это:
JOIN user ON user.cluster_id = sc.subcluster_id
JOIN survey_answers_cache sac ON (sac.surveyId = s.surveyId AND sac.user_id = user.user_id)
дополнительное условие sac.user_id = user.user_id может быть легко непоследовательным.
Можете ли вы попробовать сделать второе соединение с таблицей пользователей?
оплаченный Вы можете добавить «SHOW CREATE TABLE»