Как определить кодировку MacRoman в PHP?
РНР mb_detect_encoding() не понимает MacRoman кодирование. Мое приложение позволяет пользователям загружать данные в формате CSV, и мне нужно преобразовать их в UTF8, потому что пользователи не разбираются в технологиях. Я никогда не смогу заставить их всех понять, как это сделать, и контролировать их кодирование.
Это то, что я делаю:
$encoding_detection_order = array('UTF-8', 'UTF-7', 'ASCII', 'ISO-8859-1', 'EUC-JP', 'SJIS', 'eucJP-win', 'SJIS-win', 'JIS', 'ISO-2022-JP', );
$encoding = mb_detect_encoding($value, $detection_order, true);
$converted_value = iconv($encoding, 'UTF-8//TRANSLIT', $value);
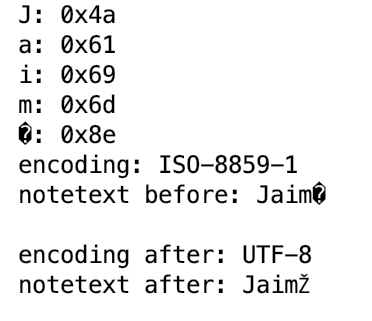
Это прекрасно работает в большинстве ситуаций, но если мой пользователь находится на Mac, и они сохраняют CSV в MacRoman кодирования, то приведенный выше код будет обычно неправильно определять текст как ISO-8859-1 что вызывает iconv() производить плохой вывод.
Например, ударение-е в Jaimé имеет шестнадцатеричное значение 0x8e в MacRoman, В ISO-8859-1, 0x8e персонаж Ž и поэтому, когда я преобразую его в utf8, я просто получаю версию utf8 Ž когда я должен получить é,
Мне нужно уметь динамически дифференцировать MacRoman из других кодировок, чтобы я преобразовал его правильно.
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …