javascript — объединение нескольких регулярных выражений
У меня есть строка, которую мне нужно изменить с помощью регулярных выражений. Так что перепробовал много разных вещей, и вот как близко я подошел.
Ниже приведено несколько примеров того, какой может быть строка и каким должен быть результат:
case A: "Schoenen US 30 / " should become -> "30"case B: "Dames US 30 / " should become -> "US 30"case C: "Dames US w30 / " should become -> "US 30"case D: "Heren US w30 / L34" should become -> "US 30 / 34"case E: "Dames US L / " should become -> "US L"Итак, что мне нужно сделать, это:
1. сопоставьте части: «Schoenen US», «Dames» и «Heren» (включая конечный пробел).
2. сопоставьте любые «w», «W», «l» и «L» в строке (необходимо удалить)
3. сопоставлять «/» только в конце строки (если она существует)
Итак, что я придумал:
case A: "/\b(Dames[ ]|dames[ ]|Heren[ ]|heren[ ]|Schoenen US[ ]|[WwLl]).([0-9][0-9]).(\/ )/g" with substitution "$2"case B & C: "/\b(Dames[ ]|dames[ ]|Heren[ ]|heren[ ]|Schoenen US[ ]|[WwLl]| \/ )/g" with empty substitution
case D: "/\b(Dames[ ]|dames[ ]|Heren[ ]|heren[ ]|Schoenen US[ ]|[WwLl])/g" with empty substitution
case E: No idea how to do this
Эти регулярные выражения делают то, что я хочу (за исключением случая E ofcourse). Но проблема в том, что я могу использовать только одно регулярное выражение, поэтому мне как-то нужно объединить все 4 из них.
Я начинающий, когда дело доходит до регулярных выражений, так что если кто-то может указать мне правильное направление, было бы здорово.
Решение
Попробуйте объединить все случаи в один шаблон как можно ближе
function tr(str) {
return str.replace(/(?:Schoenen US |\w+ (US ))(?:[wW]?(\d+ \/ )[lL]?(\d+)|[wW]?(\d+) \/ |([lL]) \/)\s*$/, "$1$2$3$4$5");
}
console.log(tr("Schoenen US 30 / ")); // 30
console.log(tr("Dames US 30 / ")); // US 30;
console.log(tr("Dames US w30 / ")); //US 30
console.log(tr("Heren es US w30 / L34")); // US 30 / 34
console.log(tr("Dames US L / ")); // US L
Надеюсь, что это поможет вам понять регулярные выражения
Другие решения
Вы можете комбинировать регулярные выражения, как это.
var a = 'something';
var b = '[a-z0-9]+';
var c = 'endwiththis$';
var regex = new RegExp(a+b+c) // /something[a-z0-9]+endwiththis$/Другой пример…
var part1 = '^\\d{1,3}\\s[a-z]+';
var part2 = '\\s .*(?=[m-s]+)';
var part3 = '.something$'
var combined = new RegExp(part1 ,part2,part3)Исходя из ваших требований, я придумаю решение, которое соответствует всему, что должно оставаться в группах захвата, и соответствует всем остальным, но не захватывает, поэтому замена представляет собой более или менее сумму всех захваченных групп (некоторые из них могут и будут пусто). Я предполагаю, что у вас есть строки, которые должны быть преобразованы в целом, и что вам не нужно слишком много заботиться, чтобы их проверить.
Наконец, шаблон регулярного выражения:
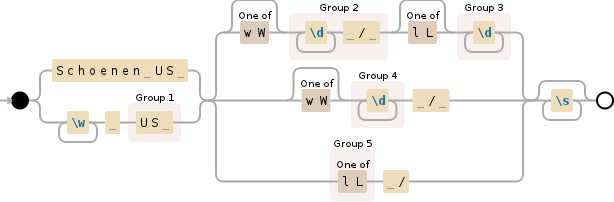
/^(?:dames|heren|schoenen us)\s+([a-z]*\s*)(?:([a-z]+)[\s/]*$|\D*(\d+)(?:[\s/]*$|(\s+\/\s+)\D*(\d+).*$))/i
И заменить:
$1$2$3$4$5
Я использовал нечувствительность к регистру, чтобы сделать его немного короче, если, тем не менее, вы должны были позаботиться о dAmEs и обрабатывать это иначе, чем dames, вам придется удалить iМодификатор и использование [Dd]ames,
Вы можете найти демо Вот
я использовал gmМодификатор, чтобы показать несколько примеров, вам не нужно их использовать.