JavaScript — file_get_contents () чтение кусков становится медленнее со временем
Я делаю несколько тестов для локального хранения больших файлов с помощью IndexedDb API и использую PHP с JSON (и AJAX на стороне Javascript) для получения данных файла.
На самом деле я пытаюсь получить несколько видео и для этого использую следующий код PHP:
$content_ar['content'] = base64_encode(file_get_contents("../video_src.mp4", false, NULL, $bytes_from, $package_size)));
return json_encode($content_ar);
я знаю base64_encode доставит на 1/3 больше информации, чем оригинал, но сейчас это не проблема, так как я знаю, как извлечь двоичные данные, не теряя их в пути.
Как вы видете, Я указываю, с какого байта он должен начинаться читать и сколько из них я хочу получить. Итак, со своей стороны JS, я знаю, сколько файлов я уже сохранил и Я прошу сценарий, чтобы вытащить меня из actual_size в actual_size + $package_size байтов.
Что я уже вижу, так это то, что скрипты, кажется, работают медленнее с течением времени и в зависимости от размера файла. Я пытаюсь понять, что там происходит.
Я читал, что file_get_contents () хранит содержимое файла в памяти, поэтому с большими файлами это может быть проблемой (поэтому я читаю его порциями).
Но с большими файлами (и временем) это становится медленнее, возможно ли, что он все еще хранит весь файл в памяти, а затем доставляет мне кусок, которому я это говорю? Как он загружает все, а затем возвращает часть, которую я требую?
Или это просто хранить все до $bytes_from + $package_size (вот почему со временем он замедляется, а увеличивается)?
Если что-то из перечисленного выше, есть ли способ заставить его работать более эффективно и повысить производительность? Может быть, я должен сделать некоторые операции до или после, чтобы очистить ресурсы памяти?
РЕДАКТИРОВАТЬ:
Я сделал снимок экрана, показывающий разницу (в мс) момента, когда я выполняю вызов, чтобы получить нужные мне байты файла, и подходящий момент, когда я получаю ответ AJAX (до того, как я что-то сделаю с полученными данными, поэтому Javascript не влияет на производительность). Вот:
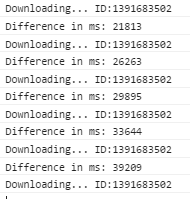
Как видите, оно увеличивается с каждым звонком.
Я думаю, что проблема в том, сколько времени он тратит на получение начального байта, который мне нужен. Он не загружает весь файл в память, но работает медленно до тех пор, пока не будет прочитан первый байт, поэтому, поскольку он увеличивает начальную точку, это занимает больше времени.
РЕДАКТИРОВАТЬ 2:
Может ли это быть как-то связано с тем фактом, что я кодирую содержимое J64 в формате JSON? Я делал некоторые тесты производительности, и я видел эту настройку $content_ar['content'] = strlen(base64_encode(file...)) это делается за гораздо меньшее время (когда, теоретически, он выполняет ту же работу).
Однако, если это так, Я до сих пор не могу понять, почему это увеличивает медлительность среди времени. Работа по кодированию одинаковой длины байтов должно занять столько же времени, не так ли?
Спасибо большое за вашу помощь!
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …