file_get_contents из html explode, запись в ячейку электронной таблицы
То, чего я пытаюсь добиться, — это выгрузить определенный контент из источника URL через file_get_contents (), затем взорвать () разметку вокруг того места, где этот контент живет, возвращая только контент в формате HTML, а затем записывая его в единый ячейки электронной таблицы или CSV. Полегче, подумал я.
Вот что у меня есть:
<?php
//My .html
$url = 'http://spiderlearning.com/demo/ALG_SA_U1_L1.html';
//Get content
$content = file_get_contents($url);
//Get content sections
$lesson_name = explode( '<section id="nameField" class="editable" contenteditable="false">' , $content);
$section_title1 = explode( '<a onclick="goToByScroll(\'obj0\')" href="#">' , $content);
$challenge_q = explode( '<section id="redactor_content" class="editable" contenteditable="false">' , $content);
//Write content
$write1 = explode("</section>" , $lesson_name[1]);
$write2 = explode("</a>" , $section_title1[1]);
$write3 = explode("</section>" , $challenge_q[1]);
//Into arrays
$line1 = array($write1[0],$write2[0],$write3[0]);
$list = array($line1);
//Open .csv
$file = fopen("data/data.csv", "w");
//Write as line, delimitate with ";"
foreach ($list as $line) fputcsv($file, $line, ';');
//Close
fclose($file);
?>
Который возвращает:
То, что я ищу, это:
CSV:
Unit 1 Lesson 1; 1. Challenge Questions; <p><img src="https://s3-eu-west-1.amazonaws.com/teacher-uploads.fishtree.com/SpiderLearning/1428953716a42b06b9-1ce1-4594-badd-4ab8c9b65ac0.jpeg" alt="" rel="float: left; width: 171px; height: 113.697826086957px; margin: 0px 10px 10px 0px;" style="float: left; width: 171px; height: 113.697826086957px; margin: 0px 10px 10px 0px;"></p><p>Before you begin this lesson, let's see what you already know about the topic. Take a moment to complete the three Challenge Questions that follow.</p>
Мне кажется, что проблема заключается в возврате каретки в отформатированном контенте. Он также собирает круглые скобки вокруг возвращаемого контента, но я не уверен, откуда. Есть ли способ избежать этого? В прошлом я собирал аналогичные функции без каких-либо проблем, но это мой первый файл file_get_contents () в CSV, и через пару недель я наконец-то с этим справился.
Решение
Сначала, чтобы избавиться от разрывов строки, сделайте это:
foreach ($list as $line) fputcsv($file, preg_replace( "/\r|\n/", "", $line), ';');
Было бы лучше оставить те разделители полей, которые введены fputcsv. Причина в том, что любая точка с запятой внутри одного из полей будет разбивать ваш CSV над CSV, который вы хотите, выглядит так:
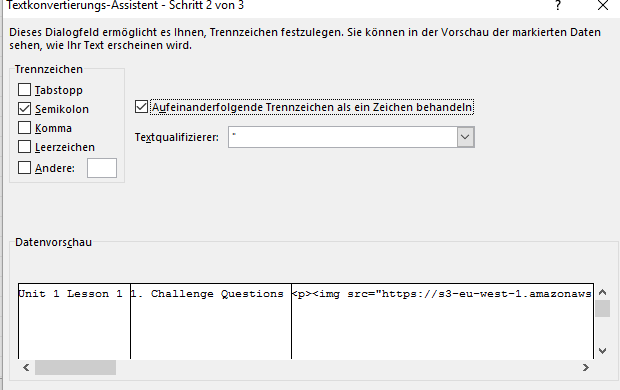
"Unit 1 Lesson 1";"1. Challenge Questions";"<p><img src=""https://s3-eu-west-1.amazonaws.com/teacher-uploads.fishtree.com/SpiderLearning/1428953716a42b06b9-1ce1-4594-badd-4ab8c9b65ac0.jpeg"" alt="""" rel=""float: left; width: 171px; height: 113.697826086957px; margin: 0px 10px 10px 0px;"" style=""float: left; width: 171px; height: 113.697826086957px; margin: 0px 10px 10px 0px;""></p><p>Before you begin this lesson, let's see what you already know about the topic. Take a moment to complete the three Challenge Questions that follow.</p>"Но вы не можете напрямую открыть это в Excel в большинстве случаев (где-то есть глобальная настройка). Вам необходимо импортировать эти данные, а затем установить следующие вещи:
Другие решения
Вот альтернативное решение, основанное на PHP-классе DOMDocument:
$url = 'http://spiderlearning.com/demo/ALG_SA_U1_L1.html';
// Load HTML via DOMDocument class
$doc = new DOMDocument();
libxml_use_internal_errors(true);
$doc->loadHTMLFile($url);
// Extract the elements of interest
$xpath = new DOMXPath($doc);
$list = [
[
"lesson" => $doc->getElementById('nameField')->textContent,
"section" => $xpath->query("//div[@class='activitySelect']//a")[0]->textContent,
"challenge" => innerHTML($doc->getElementById('redactor_content'))
]
];
// Write CSV (unchanged code)
$file = fopen("php://output", "w");
foreach ($list as $line) fputcsv($file, $line, ';');
fclose($file);
// Utility function
function innerHTML($node) {
return implode(array_map([$node->ownerDocument,"saveHTML"],
iterator_to_array($node->childNodes)));
}