Данные UTF8, сохраненные из подключения Latin1, как проверить, в порядке ли мои данные?
Latin1 Connection вместо UTF8
Недавно я получил сообщения от тех, кто использует мой веб-сайт, что они не могут создавать контент на китайском или арабском языке. Это побудило меня попробовать создать контент на моем сайте с использованием китайских символов, и я заметил, что данные, хранящиеся для этих символов, представляют собой знак вопроса ?,
Из других вопросов и статей я понял, что прочитал Я, вероятно, в «аде набор символов».
Кажется, что я подключался к базе данных, используя Entity Framework, используя Latin1 соединение, так как это по умолчанию для MySQL, но столбцы в моей базе данных UTF8,
Как мои данные закодированы?
Из того, что я прочитал о процессе, я думаю, что данные в моей базе данных UTF8 данные из браузера, закодированные как Latin1 во время передачи в базу данных, которая затем снова кодируется как UTF8 непосредственно перед тем, как он будет сохранен в базе данных.
Я использовал скрипт PHP, чтобы определить, правильно ли поступают данные при настройке подключения UTF8 — и когда я выбираю данные из своей базы данных, это не похоже на разницу.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
</head>
<body>
<?php
//
// Make the connection to the database
//
$link = mysqli_connect('localhost','root', '', 'mydatabase');
if (!$link) {
die('Could not connect to MySQL: ' . mysql_error());
}
// Set connection character set to UTF8
$link->set_charset('utf8');
echo '<p>Connection OK</p>';
//
// Request the string from the database
//
$result = $link->query("SELECT questiontext FROM question WHERE id = 101");
$row = $result->fetch_assoc();
// Display the data
echo "Result: " . $row['questiontext'] . '<br/>';
mysqli_close($link);
?>
</body>
</html>
- Если я запрашиваю строку, которая выглядит как [A-Z 0-9] символов, используя
UTF8подключение к существующим данным, используя этот скрипт PHP, он отображается на экране так же, как и надLatin1соединение при использовании Entity Framework, я не могу сказать разницу. Там нет появиться быть любой проблемой с данными. - Если я запрашиваю строку китайских символов, которые, по-видимому, были введены в базу данных в виде вопросительных знаков, она отображается в виде вопросительных знаков при получении через
UTF8подключение.
Я ожидал, что когда я подключился к базе данных, используя UTF8 связи, что данные будут отображаться как мусор, как я ранее использовал Latin1 связь — но это не так.
Я использовал Entity Framework для опроса переменных MySql, которые использовались для соединения до и после добавления CharSet=utf8; к моей строке подключения. Надеюсь, может дать вам представление о том, как связь было устанавливаются раньше и как сейчас:
Подключение до:
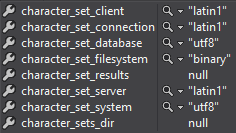
Обновлена связь с набором строк подключения:
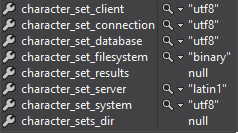
Как я могу определить, что данные в базе данных закодированы неправильно, являются ли они данными Latin1, закодированными как UTF8, чтобы я мог решить, могу ли я просто изменить строку подключения, чтобы использовать UTF8, и все будет работать нормально?
Обновить
Я экспериментировал, переключая тип соединения между UTF8 а также Latin1 и это мои выводы …
Если я установлю тип подключения latin1 и вывод символов, я получаю что-то вроде этого:
Tu es dans un le d serte
HEX (bin2hex): 54752065732064616e7320756e6520 й 6c652064 e9 7365727465203a
Если я установлю свое подключение к utf8:
Tu es dans une île déserte
HEX (bin2hex): 54752065732064616e7320756e6520 c3ae 6c652064 c3a9 7365727465203a
(жирным шрифтом и пробелом добавил Рик Джеймс)
При использовании соединения UTF8 никаких хитроумных символов нет вообще — только когда я устанавливаю тип соединения на latin1, Это наводит меня на мысль, что кодирование моих данных в порядке, предположительно, это просто UTF8.
Из этого я могу только расшифровать, что Entity Framework все время связывался по соединению UTF8, но я не знаю, как я могу подтвердить, что данные хранятся правильно.
Решение
Для китайцев, Вы должны указать MySQL использовать utf8mb4, а не только utf8.
При попытке использовать utf8 / utf8mb4, если вы видите Вопросительные знаки (обычные, а не черные бриллианты) (? шестнадцатеричный 3F),
- Сохраняемые байты не кодируются как utf8. Почини это.
- Столбец в базе данных
CHARACTER SET utf8mb4, Почини это. - Кроме того, проверьте, что соединение во время чтения — utf8mb4.
新浪新闻 является кракозябры за 新浪新闻
При попытке использовать utf8 / utf8mb4, если вы видите Mojibake, проверьте следующее.
Это обсуждение также относится к Двойное кодирование, что не обязательно видно.
- Сохраняемые байты должны быть в кодировке utf8.
- Соединение когда
INSERTingа такжеSELECTingтекст должен указывать utf8mb4. (set_charset) - Столбец должен быть объявлен
CHARACTER SET utf8mb4, (Проверить сSHOW CREATE TABLE.) - HTML должен начинаться с
<meta charset=UTF-8>, (Вы сделали это.)
к проверить, делать SELECT col, HEX(col) FROM ..., Если шестнадцатеричный вывод для 新 является E696B0, тогда это правильно закодировано с utf8 / utf8mb4. Если вы получаете C3A6E28093C2B0, это «двойной кодировки». Обычно если гекс начинается с E или F, он, вероятно, правильно закодирован. Кроме того, гекс для одного иероглифа во всех случаях будет иметь длину 6 или 8. Ссылка.
Другие решения
попробуйте использовать это:
// Показать данные
эхо «Результат:». utf8_encode ($ строки [ ‘questiontext’]) . ‘
«;
😉
APPLICATION-> MySQL: select HEX('中国')
mysql-> Применение: select UNHEX('E4B8ADE59BBD')
Вы можете использовать функцию MySQL