5-кратная перекрестная проверка дает обратную кривую обучения в SVM
Я смотрю на цифровую классификацию (Devanagari OCR). Я тренирую данные по модели PECL SVM в php. Чтобы построить кривую обучения, я начал тестировать устойчивость SVM к 5-кратной перекрестной проверке. Я получил результат, как показано ниже —
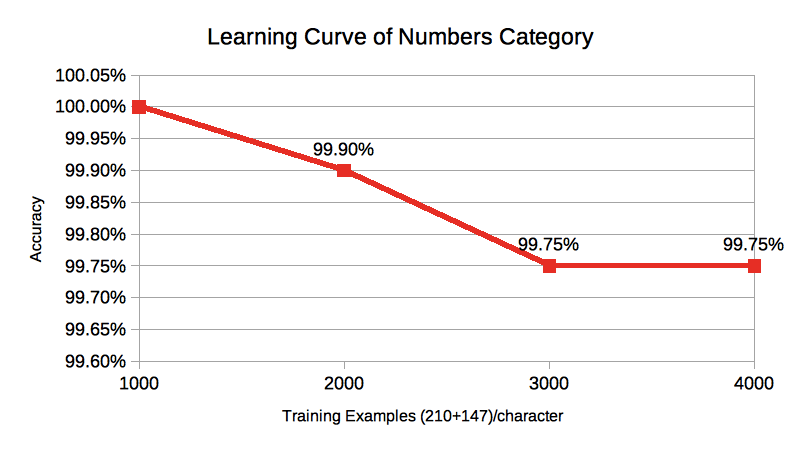
При наличии меньшего количества наборов данных это дает высокую точность, но при увеличении размера набора данных точность постепенно снижается. Я знаю, что SVM хорошо работает в меньшем количестве наборов данных. Но мой руководитель проекта не удовлетворен этим. Я искал по интернету, тогда я не нашел ничего о такой проблеме. Есть ли проблема в моей модели (SVM с ядром RBF, предоставленным PECL SVM)? или это Нормально как свойство SVM. Классификация нового изображения по модели идеальна.
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …