Запись Unicode в файл в переполнении стека
У меня проблема с записью юникода в файл на C ++. Я хочу написать в файл с моим собственным расширением несколько смайликов, которые вы можете получить, набрав ALT + NUMPAD (2). Я могу отобразить его на CMD, сделав символ и присвоив ему значение ‘\ 2’, и оно отобразит смайлик, но не запишет его в файл.
Вот фрагмент кода для моей программы:
ofstream myfile;
myfile.open("C:\Users\My Username\test.exampleCodeFile");
myfile << "\2";
myfile.close();
Он будет записывать в файл, но не будет отображать то, что я хочу. Я бы показал вам, что он отображает, но StackOverflow не позволяет мне отображать персонажа. Заранее спасибо.
Решение
ALT + NUMPAD2 — это не то же самое, что ASCII-символ 2, который записывает ваш код в файл. ALT-коды — это то, как DOS обрабатывает не-ASCII-символы. Символ, который CMD.COM отображает для ALT + NUMPAD2, фактически является кодовой точкой Unicode U + 263B «BLACK SMILING FACE». Будучи символом Unicode, лучше всего кодировать файл с использованием UTF-8 или UTF-16, например:
ofstream myfile;
myfile.open("C:\\Users\My Username\\test.txt");
myfile << "\xEF\xBB\xBF"; // UTF-8 BOM
myfile << "\xE2\x98\xBB"; // U+263B
myfile.close();
.
ofstream myfile;
myfile.open("C:\\Users\\My Username\\test.txt");
myfile << "\xFF\xFE"; // UTF-16 BOM
myfile << "\x3B\x26"; // U+263B
myfile.close();
Оба подхода показывают смайлик в блокноте (при условии, что вы используете шрифт, который поддерживает смайлики), так как он сначала читает спецификацию, а затем декодирует код Unicode соответствующим образом, основываясь на этом.
Другие решения
Вы должны использовать Unicode, чтобы указать символы, которые вы хотите отобразить. Символ, представленный байтом 02h в консоли переводится кодовая страница 437 (cp437) символу Юникод U+263B, Использование исходного файла, сохраненного в UTF-8 с BOM, упрощает использование Unicode, поскольку вы можете вставлять или вводить нужные символы, не прибегая к escape-кодам Unicode.
Для файлового потока поток должен быть настроен для UTF-8. Есть несколько способов сделать это, и это зависит от компилятора, но с использованием Visual Studio 2012, исходного кода, сохраненного в UTF-8 с BOM, и небольшого количества Googling:
#include <locale>
#include <codecvt>
#include <fstream>
#include <iostream>
#include <io.h>
#include <fcntl.h>
using namespace std;
int main()
{
const std::locale utf8_locale = std::locale(std::locale(), new std::codecvt_utf8<wchar_t>());
wofstream f(L"sample.txt");
f.imbue(utf8_locale);
f << L"\u263b我是美国人。我叫马克。" << endl;
_setmode(_fileno(stdout),_O_U16TEXT);
wcout << L"\u263b我是美国人。我叫马克。" << endl;
}
Содержание sample.txt как видно в блокноте:
☻我是美国人。我叫马克。
Шестнадцатеричный дамп (правильный UTF-8):
E68891E698AFE7BE8EE59BBDE4BABAE38082E68891E58FABE9A9ACE5858BE380820D0A
Вывод на консоль вырезан и вставлен здесь. Визуальное отображение было для каждого китайского иероглифа без правильного шрифта, но символы отображались правильно, вставленные в SO или Блокнот.
☻我是美国人。我叫马克。
Вы используете полную противоположность Unicode. Консоль работает с 8-битной кодовой страницей, по умолчанию на западных машинах кодовая страница 437. Который совпадает с набором символов старого ПЗУ символов IBM PC и является кодовой страницей, ожидаемой большинством устаревших программ для DOS. Первый набор кодов символов, коды от 0 до 8, выглядит следующим образом:
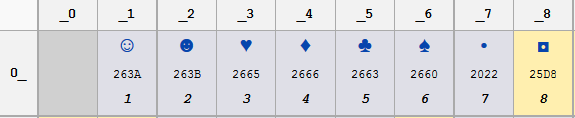
Обратите внимание на смайлик для кода 0x02, который вы видели на своей консоли. Вы можете увидеть остальные глифы в этом Статья в википедии. Неприятная проблема с 8-битными кодировками символов в том, что их так много. Блокнот читает ваш файл с разные кодовая страница По умолчанию это Windows-1252 на машинах в Западной Европе и Америке. На этой странице нет символов для управляющих кодов, поэтому вы не видели смайлика в Блокноте.
Работа с кодовыми страницами — главная головная боль. Вот почему Unicode был изобретен.
Переключение консоли на кодовую страницу Unicode возможно. Однако это должна быть все еще 8-битная кодировка, еще одно устаревшее решение консольных программ, поддерживающих перенаправление вывода. Что делает правильный выбор UTF-8. Вы можете переключиться с самой консоли, набрав chcp 65001 перед запуском вашей программы. Или вы можете сделать это в своем коде, позвоните SetConsoleOutputCP(CP_UTF8);,
Еще одна неприятная деталь, о которой вам нужно позаботиться, также необходимо изменить шрифт, используемый для консоли. Шрифтом по умолчанию является TERMINAL, унаследованный шрифт, который был разработан для отображения глифов IBM PC, но не знает бинов о Unicode. Используйте системное меню для переключения (нажмите Alt + Пробел, Свойства), выбирать не так много, но Консоль или Консоль Lucinda подходят.
Теперь вы можете отобразить Unicode, это совсем другая история, которую представил Реми.