Вывод KCachegrind для оптимизированных и неоптимизированных сборок
я бегу valgrind --tool=callgrind ./executable на исполняемый файл, сгенерированный с помощью следующего кода:
#include <cstdlib>
#include <stdio.h>
using namespace std;
class XYZ{
public:
int Count() const {return count;}
void Count(int val){count = val;}
private:
int count;
};
int main() {
XYZ xyz;
xyz.Count(10000);
int sum = 0;
for(int i = 0; i < xyz.Count(); i++){
//My interest is to see how the compiler optimizes the xyz.Count() call
sum += i;
}
printf("Sum is %d\n", sum);
return 0;
}
Я делаю debug построить со следующими параметрами: -fPIC -fno-strict-aliasing -fexceptions -g -std=c++14, release build со следующими параметрами: -fPIC -fno-strict-aliasing -fexceptions -g -O2 -std=c++14,
Запуск valgrind создает два файла дампа. Когда эти файлы (один файл для исполняемого файла отладки, другой для исполняемого файла выпуска) просматриваются в KCachegrind, сборка отладки понятна, как показано ниже:
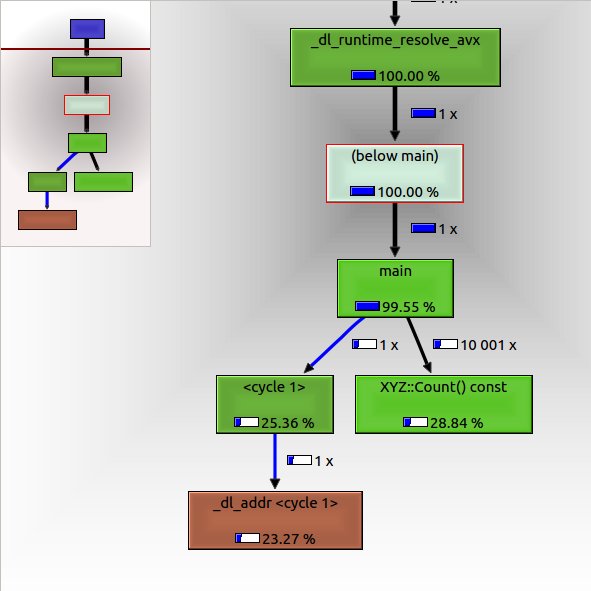
Как и ожидалось, функция XYZ::Count() const называется 10001 раз. Однако оптимизированную сборку релиза гораздо сложнее расшифровать, и неясно, сколько раз эта функция вызывается вообще. Я знаю, что вызов функции может быть inlined, Но как можно выяснить, что это был факт? Вызов для сборки релиза показан ниже:
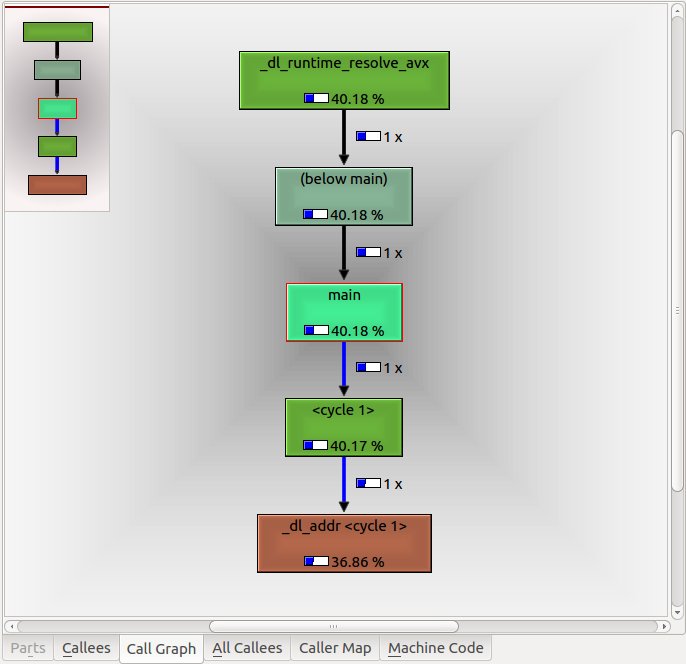
Кажется, нет никаких признаков функции XYZ::Count() const вообще из main(),
Мои вопросы:
(1) Не глядя на код на ассемблере, сгенерированный сборками отладки / выпуска, и используя KCachegrind, как можно определить, сколько раз определенная функция (в этом случае XYZ::Count() const) называется? В приведенном выше графике вызовов сборки выпуска эта функция не вызывается ни разу.
(2) Есть ли способ понять граф вызовов и другие детали, предоставленные KCachegrind для выпуска / оптимизированных сборок? Я уже посмотрел руководство KCachegrind, доступное на https://docs.kde.org/trunk5/en/kdesdk/kcachegrind/kcachegrind.pdf, но мне было интересно, есть ли полезные хакерские правила, которые следует искать в сборках релиза.
Решение
Вывод valgrind легко понять: как говорят valgrind + kcachegrind, эта функция вообще не была вызвана в сборке релиза.
Вопрос в том, что вы имеете в виду под названием? Если функция встроена, она все еще «вызывается»? На самом деле ситуация сложнее, как кажется на первый взгляд, и ваш пример не так уж тривиален.
Было Count() встроенный в релизную сборку? Конечно, вроде. Преобразование кода во время оптимизации часто весьма примечательно, как в вашем случае — и лучший способ оценить это посмотреть на результат ассемблер (здесь для лязга):
main: # @main
pushq %rax
leaq .L.str(%rip), %rdi
movl $49995000, %esi # imm = 0x2FADCF8
xorl %eax, %eax
callq printf@PLT
xorl %eax, %eax
popq %rcx
retq
.L.str:
.asciz "Sum is %d\n"Вы можете видеть, что main вообще не выполняет цикл for, а просто печатает результат (49995000), который вычисляется во время оптимизации, поскольку число итераций известно во время компиляции.
Так было Count() встраиваемый? Да, где-то на первых этапах оптимизации, но потом код стал чем-то совершенно другим — там, где нет места Count() был встроен в финальный ассемблер.
Так что же происходит, когда мы «скрываем» количество итераций от компилятора? Например. передать его через командную строку:
...
int main(int argc, char* argv[]) {
XYZ xyz;
xyz.Count(atoi(argv[1]));
...
В результате ассемблер, мы все еще не сталкиваемся с циклом for, потому что оптимизатор может выяснить, что вызов Count() не имеет побочных эффектов и оптимизирует все это:
main: # @main
pushq %rbx
movq 8(%rsi), %rdi
xorl %ebx, %ebx
xorl %esi, %esi
movl $10, %edx
callq strtol@PLT
testl %eax, %eax
jle .LBB0_2
leal -1(%rax), %ecx
leal -2(%rax), %edx
imulq %rcx, %rdx
shrq %rdx
leal -1(%rax,%rdx), %ebx
.LBB0_2:
leaq .L.str(%rip), %rdi
xorl %eax, %eax
movl %ebx, %esi
callq printf@PLT
xorl %eax, %eax
popq %rbx
retq
.L.str:
.asciz "Sum is %d\n"Оптимизатор придумал формулу (n-1)*(n-2)/2 на сумму i=0..n-1!
Давайте теперь скрыть определение Count() в отдельном блоке перевода class.cppоптимизатор не может увидеть его определение:
class XYZ{
public:
int Count() const;//definition in separate translation unit
...
Теперь мы получаем наш цикл for и вызов Count() в каждой итерации самая важная часть ассемблер является:
.L6:
addl %ebx, %ebp
addl $1, %ebx
.L3:
movq %r12, %rdi
call XYZ::Count() const@PLT
cmpl %eax, %ebx
jl .L6
Результат Count() (в %rax) сравнивается с текущим счетчиком (в %ebx) на каждом шаге итерации. Теперь, если мы запустим его с Valgrind, мы увидим в списке вызываемых, что XYZ::Count() назывался 10001 раз.
Однако для современных цепочек инструментов недостаточно увидеть ассемблер единичных блоков перевода — есть вещь, которая называется link-time-optimization, Мы можем использовать это, строя где-то по этим направлениям:
gcc -fPIC -g -O2 -flto -o class.o -c class.cpp
gcc -fPIC -g -O2 -flto -o test.o -c test.cpp
gcc -g -O2 -flto -o test_r class.o test.o
И, запустив получившийся исполняемый файл с помощью valgrind, мы еще раз видим, что Count() не был вызван!
Однако, глядя на машинный код (здесь я использовал gcc, моя clang-установка, похоже, имеет проблемы с lto):
00000000004004a0 <main>:
4004a0: 48 83 ec 08 sub $0x8,%rsp
4004a4: 48 8b 7e 08 mov 0x8(%rsi),%rdi
4004a8: ba 0a 00 00 00 mov $0xa,%edx
4004ad: 31 f6 xor %esi,%esi
4004af: e8 bc ff ff ff callq 400470 <strtol@plt>
4004b4: 85 c0 test %eax,%eax
4004b6: 7e 2b jle 4004e3 <main+0x43>
4004b8: 89 c1 mov %eax,%ecx
4004ba: 31 d2 xor %edx,%edx
4004bc: 31 c0 xor %eax,%eax
4004be: 66 90 xchg %ax,%ax
4004c0: 01 c2 add %eax,%edx
4004c2: 83 c0 01 add $0x1,%eax
4004c5: 39 c8 cmp %ecx,%eax
4004c7: 75 f7 jne 4004c0 <main+0x20>
4004c9: 48 8d 35 a4 01 00 00 lea 0x1a4(%rip),%rsi # 400674 <_IO_stdin_used+0x4>
4004d0: bf 01 00 00 00 mov $0x1,%edi
4004d5: 31 c0 xor %eax,%eax
4004d7: e8 a4 ff ff ff callq 400480 <__printf_chk@plt>
4004dc: 31 c0 xor %eax,%eax
4004de: 48 83 c4 08 add $0x8,%rsp
4004e2: c3 retq
4004e3: 31 d2 xor %edx,%edx
4004e5: eb e2 jmp 4004c9 <main+0x29>
4004e7: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
Мы можем видеть, что вызов функции Count() был встроен, но — все еще есть цикл for (я думаю, это вещь gcc vs clang).
Но что вас больше всего интересует: функция Count() вызывается только один раз — его значение сохраняется в регистре %ecx и цикл на самом деле только:
4004c0: 01 c2 add %eax,%edx
4004c2: 83 c0 01 add $0x1,%eax
4004c5: 39 c8 cmp %ecx,%eax
4004c7: 75 f7 jne 4004c0 <main+0x20>
Это все, что вы также можете увидеть с помощью Kcachegrid, если valgrind запускается с опцией `—dump-instr = yes.
Другие решения
найдите в файле callgrind.out XYZ :: Count (), чтобы узнать, записал ли valgrind какие-либо события для этой функции.
grep "XYZ::Count()" callgrind.out | more
если вы найдете имя функции в файле callgrind, важно знать, что kcachegrind скрывает функции с небольшим весом.
см. ответы по адресу: Заставить callgrind показывать все вызовы функций в графе вызовов kcachegrind