Выбор начальных параметров для алгоритма Левенберга-Марквардта на нейронной сети
В настоящее время я работаю над проектом, в котором используется ANN. Для алгоритма обучения я выбрал LMA, поскольку он довольно быстрый и универсальный, и я прочитал статью, в которой предлагается, что это лучший алгоритм обучения для нашего варианта использования. Однако после его написания меня стало беспокоить, поскольку SSE (сумма квадратов ошибок, деленных на 2) уменьшалась только с 2,05 до 1,00 при простой задаче XOR с использованием сети с 2 входами, 1 скрытого слоя с 2 узлами и 1 выход. Я подумал, что где-то допустил ошибку в программировании, однако, когда я попытался изменить начальное значение PRNG, SSE внезапно приблизился к 2.63e-09. Однако это было еще более смущающим по сравнению с возможной ошибкой программирования, так как я не ожидал, что производительность алгоритма так сильно пострадает от случайной случайности для такой простой задачи.
PRNG генерирует смещения и веса в соответствии с бимодальным распределением с модами 0,8 и -0,8, и распределение вероятностей падает близко к 0 около 0, так что, надеюсь, я не должен повредить алгоритм с самого начала с очень маленькими параметрами, но есть ли какие-либо другие советы для создания хороших начальных значений? Я использую tanh для моей сигмовидной функции, если это имеет значение. Я думаю, что, возможно, использование значений с большей величиной может иметь значение, но я в равной степени обеспокоен тем, что также может иметь пагубные последствия.
Я знаю, что LMA сходится только к локальному минимуму, но, конечно, с тем, насколько широко он используется, есть какой-то способ избежать этих проблем. Мне просто не повезло с моим начальным значением? Должен ли я просто повторять тренировку с новым начальным значением каждый раз, когда он застревает? Должен ли я смотреть в сторону другого алгоритма обучения полностью?
ANN будет сначала проходить предварительную подготовку по некоторым историческим данным, а затем регулярно обновляться новыми данными, поэтому, хотя я, вероятно, могу позволить повторить обучение несколько раз, если это необходимо, существует практическое ограничение на то, сколько начальных значений можно попробовать. Кроме того, хотя в этом первоначальном тесте было только 9 параметров, в конечном итоге мы будем иметь дело с почти 10000 и, возможно, более чем одним скрытым слоем. Мой инстинкт заключается в том, что это усугубит проблему с локальными минимумами, но возможно ли, что увеличение размера проблемы может быть полезным?
Решение
TL; DR
Проблема заключалась в том, что моя сетевая конфигурация была слишком маленькой, чтобы справиться со сложностью XOR. Использование [2,3,1] привело к немедленным улучшениям, а [2,4,1] стало еще лучше. Другие логические таблицы не нуждались в такой большой сети.
Прогресс!
Хорошо, я думаю, что добился определенного прогресса и нашел источник проблемы. Я обучил набор из 100 случайных сетей XOR, используя размеры слоев [2,2,1], а затем построил обратный кумулятивный график числа сетей, которые достигли данного SSE после до 1000 эпох (остановка рано после падения SSE). ниже 1е-8).
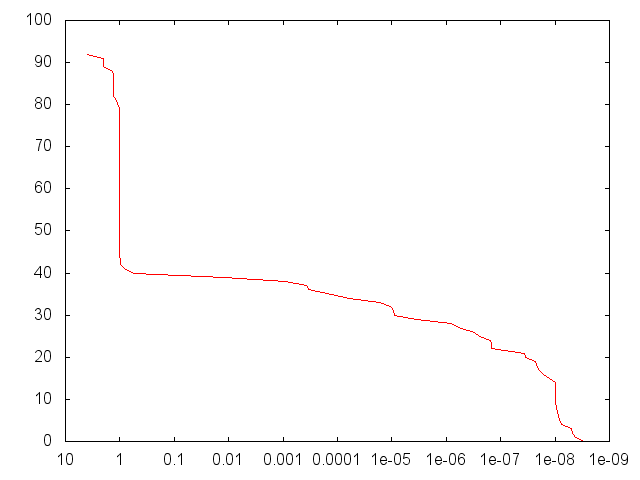
Это был график, который я получил для (XOR b). 8% сетей были повреждены значениями NAN (я предполагаю, что это как-то связано с библиотекой разложения и матрицы, которую я использую, но я отвлекся). Что беспокоит, так это то, что из 92 действительных образцов сетей только 43% достигли SSE ниже ~ 1. Более высокие образцы имели тенденцию давать еще худшие результаты. IIRC, для размера выборки 1000 (с меньшим количеством эпох) я обнаружил, что только 4% опустились ниже 1. Более поздний тест, снова использовавший 1000 эпох для выборки 1000, дал более респектабельные 47%. Тем не менее, это было неприемлемо для меня, и это очень расстраивало, так как те, кто достиг уровня ниже 1, имели очень хорошие результаты, обычно достигая по крайней мере 1e-6 или даже лучше.
Во всяком случае, недавно мы написали несколько привязок Python и внедрили еще несколько тестовых сетей, ожидая увидеть похожие результаты. Удивительно, однако, что эти тесты работали почти идеально, более 90% имели тенденцию делать лучше, чем 1e-6:
А И Б
[2,2,1] Конфигурация слоя.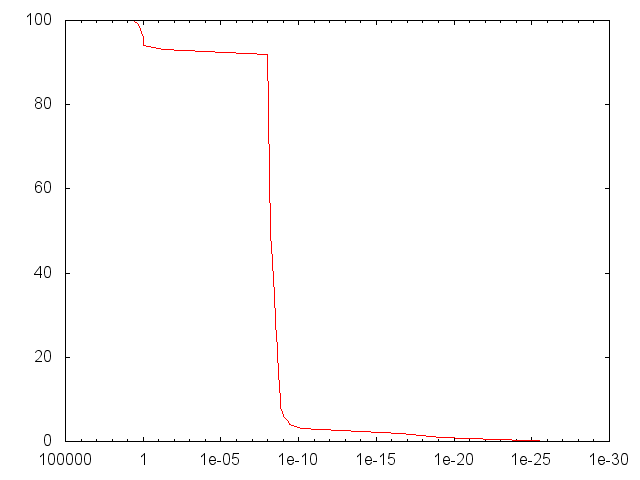
ИЛИ б
[2,2,1] Конфигурация слоя.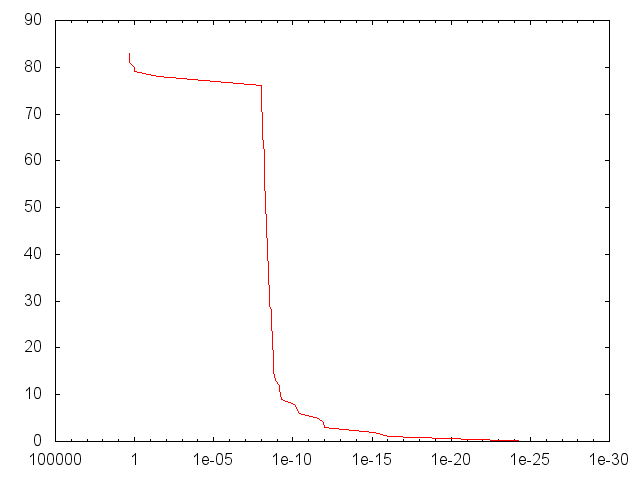
ИЛИ (б И в)
[3,4,1] Конфигурация слоя (3 входа: a, b, c).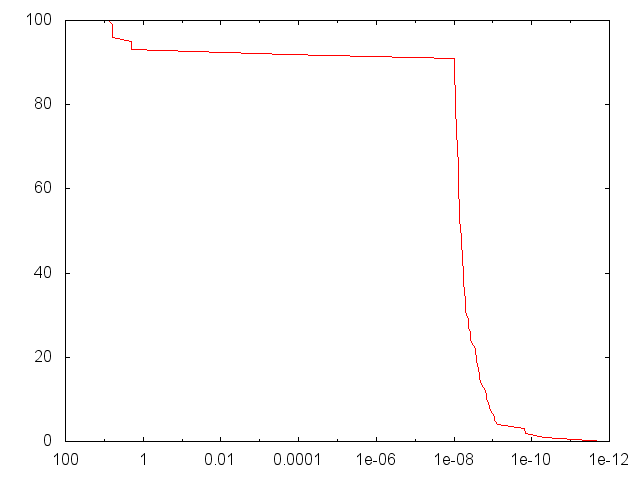
Очевидно, что-то было не так с сетью XOR, в частности, и у меня просто не получилось выбрать XOR для моей первой тестовой задачи. Читая другие вопросы по SO, кажется, что сети XOR плохо смоделированы в небольших сетях и невозможны в [2,2,1] сетях без предубеждений. У меня были предубеждения, но этого явно было недостаточно. Наконец, благодаря этим подсказкам я смог приблизить сеть XOR к другим проблемам. Просто добавив еще 1 скрытый узел и используя конфигурацию слоя [2,3,1], я смог увеличить долю выборок, достигших 1e-6, до более 70%:
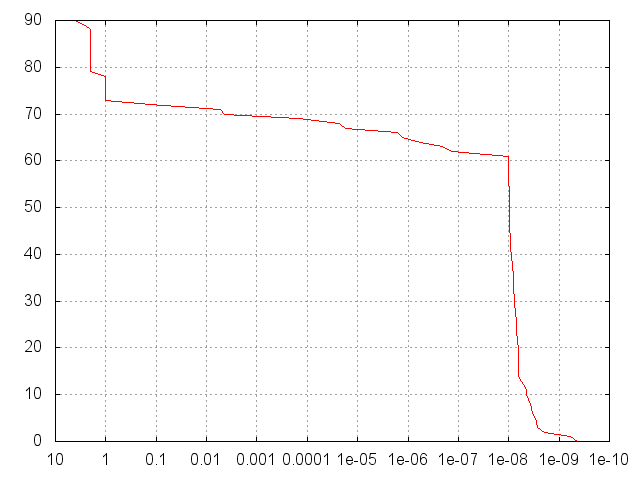
Использование [2,4,1] подняло его до 85%:
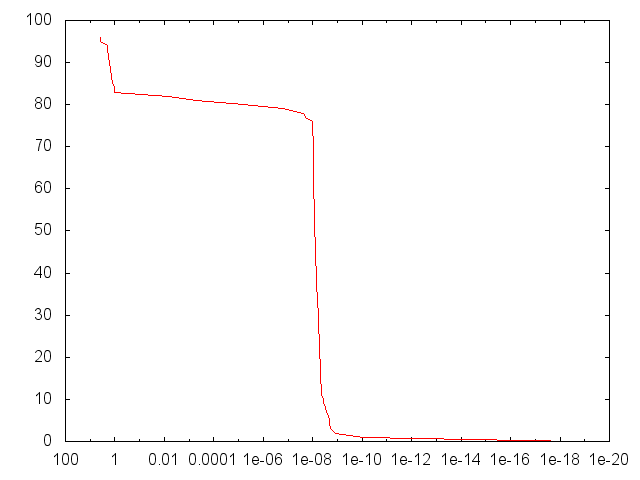
Ясно, что моя проблема заключалась в том, что размер моей сети просто не был достаточно большим, чтобы справляться со сложностью сети XOR, и я предлагаю всем, кто тестирует свои нейронные сети с проблемой 2-битного XOR, помнить об этом!
Спасибо за то, что поделились со мной этим длинным постом, и приносим извинения за чрезмерное использование изображений. Я надеюсь, что это спасает людей в подобной ситуации от многих головных болей!
Дополнительная информация, связанная с вопросом
Во время моего исследования я узнал немало, и поэтому я хотел бы затронуть еще несколько вопросов об использовании LMA, которые могут представлять интерес.
Во-первых, распределение, похоже, не имеет значения, если это случайное распределение. Я попробовал бимодальное распределение, упомянутое в вопросе, равномерное распределение между 0 и 1, гауссиан, гауссиан со средним 0,5 и SD 0,5, даже треугольное распределение, и все они дали очень похожие результаты. Я придерживаюсь бимодального однако, поскольку это кажется самым естественным ИМХО.
Во-вторых, ясно, что даже для простых проблем, с которыми я столкнулся здесь, необходимо повторное обучение. В то время как ~ 90% выборок дали достойный SSE, остальные 10% показывают, что вам всегда нужно предвидеть необходимость повторять тренировку с новым набором случайных весов несколько раз, по крайней мере, пока вы не получите желаемый SSE, но, возможно, фиксированное количество раз, чтобы выбрать лучшее из вашего образца.
Наконец, мои тесты привели меня к убеждению, что LMA действительно настолько эффективен и универсален, как заявлено, и теперь я гораздо увереннее использую его. Мне все еще нужно проверить его на более крупных проблемах (я рассматриваю MNIST), но я надеюсь, что он останется таким же эффективным для этих более крупных проблем и сетей.
Другие решения
Других решений пока нет …