Векторизованное извлечение определенного массива шорт из массива, а также вставка в новый массив
У меня есть массив шорт, где я хочу, чтобы получить половину значений и поместить их в новый массив, который в два раза меньше. Я хочу получить определенные значения в этом типе шаблона, где каждый блок 128 бит (8 шорт). Это единственный шаблон, который я буду использовать, это не обязательно должен быть «любой общий шаблон»!
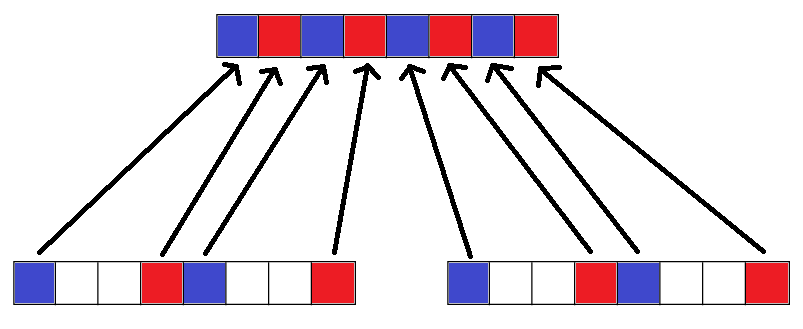
Значения в белом отбрасываются. Размеры моего массива всегда будут степенью 2. Вот смутное представление об этом, невекторизованное:
unsigned short size = 1 << 8;
unsigned short* data = new unsigned short[size];
...
unsigned short* newdata = new unsigned short[size >>= 1];
unsigned int* uintdata = (unsigned int*) data;
unsigned int* uintnewdata = (unsigned int*) newdata;
for (unsigned short uintsize = size >> 1, i = 0; i < uintsize; ++i)
{
uintnewdata[i] = (uintdata[i * 2] & 0xFFFF0000) | (uintdata[(i * 2) + 1] & 0x0000FFFF);
}
Я начал с чего-то вроде этого:
static const __m128i startmask128 = _mm_setr_epi32(0xFFFF0000, 0x00000000, 0xFFFF0000, 0x00000000);
static const __m128i endmask128 = _mm_setr_epi32(0x00000000, 0x0000FFFF, 0x00000000, 0x0000FFFF);
__m128i* data128 = (__m128i*) data;
__m128i* newdata128 = (__m128i*) newdata;
и я могу выполнять итеративно _mm_and_si128 с масками, чтобы получить значения, которые я ищу, объединить с _mm_or_si128и поместите результаты в newdata128[i], Тем не менее, я не знаю, как «сжать» вещи вместе и удалить значения в белом. И, кажется, если бы я мог это сделать, мне бы вообще не понадобились маски.
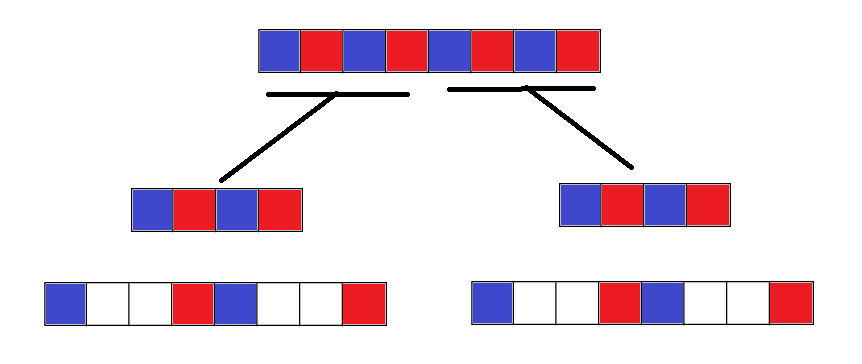
Как это можно сделать?
В любом случае, в конце концов, я также захочу сделать противоположное этой операции, создать новый массив в два раза больше и распределить в нем текущие значения.
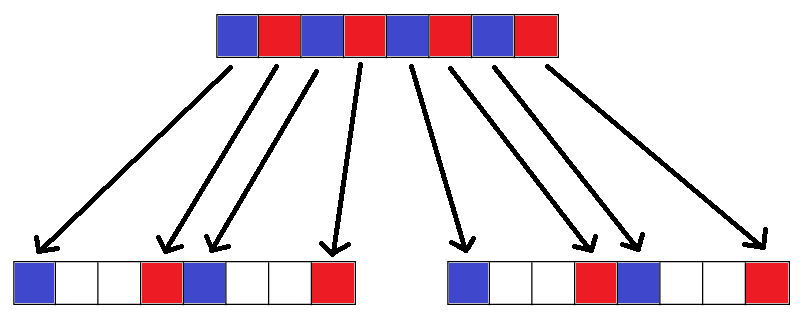
У меня также будут новые значения для вставки в белые блоки, которые я должен был бы вычислять с каждой парой шорт в исходных данных, итеративно. Это вычисление не будет векторизованным, но вставка результирующих значений должна быть. Как я могу «разложить» мои текущие значения в новый массив, и как лучше всего вставить мои вычисленные значения? Должен ли я вычислять их все для каждой 128-битной итерации и помещать их в их собственный временный блок (64-битный или 128-битный?), А затем делать что-то для массового ввода? Или они должны быть направлены прямо в мою цель __m128i, как кажется, стоимость должна быть эквивалентна введению в темп? Если так, как это можно сделать, не испортив мои другие ценности?
Я бы предпочел использовать операции SSE2 максимально для этого.
Решение
Вот схема, которую вы можете попробовать:
- Используйте инструкцию чередования (
_mm_unpackhi/lo_epi16) с регистром, содержащим ноль, чтобы «разложить» ваши 16-битные значения. Теперь у вас будет два регистра в видеB_R_B_R_, - Сдвиг вправо, создавая
_B_R_B_R - И R из первой версии
B___B___ - И Б из второй версии
___R___R - ИЛИ вместе
B__RB__R
В другом направлении используйте _mm_packs_epi32 в конце после установки его с помощью shift / и / или.
Каждое направление должно быть 10 инструкций SSE (не считая настройки констант, нулей и масок AND, а также загрузки / сохранения).
Другие решения
Других решений пока нет …