В чем разница между использованием явных заборов и std :: atomic?
Предполагая, что выравниваемые нагрузки и хранилища указателя на целевой платформе естественно атомарны, в чем разница между этим:
// Case 1: Dumb pointer, manual fence
int* ptr;
// ...
std::atomic_thread_fence(std::memory_order_release);
ptr = new int(-4);
этот:
// Case 2: atomic var, automatic fence
std::atomic<int*> ptr;
// ...
ptr.store(new int(-4), std::memory_order_release);
и это:
// Case 3: atomic var, manual fence
std::atomic<int*> ptr;
// ...
std::atomic_thread_fence(std::memory_order_release);
ptr.store(new int(-4), std::memory_order_relaxed);
У меня сложилось впечатление, что все они были эквивалентны, однако Relacy обнаруживает гонку данных в
первый случай (только):
struct test_relacy_behaviour : public rl::test_suite<test_relacy_behaviour, 2>
{
rl::var<std::string*> ptr;
rl::var<int> data;
void before()
{
ptr($) = nullptr;
rl::atomic_thread_fence(rl::memory_order_seq_cst);
}
void thread(unsigned int id)
{
if (id == 0) {
std::string* p = new std::string("Hello");
data($) = 42;
rl::atomic_thread_fence(rl::memory_order_release);
ptr($) = p;
}
else {
std::string* p2 = ptr($); // <-- Test fails here after the first thread completely finishes executing (no contention)
rl::atomic_thread_fence(rl::memory_order_acquire);
RL_ASSERT(!p2 || *p2 == "Hello" && data($) == 42);
}
}
void after()
{
delete ptr($);
}
};
Я связался с автором Relacy, чтобы узнать, было ли это ожидаемым поведением; он говорит, что в моем тестовом случае действительно есть гонка данных.
Тем не менее, я не могу определить это; может кто-нибудь указать мне, что это за гонка?
Самое главное, каковы различия между этими тремя случаями?
Обновить: Мне пришло в голову, что Relacy может просто жаловаться на валентность (или, скорее, его отсутствие) переменной, доступ к которой осуществляется через потоки … в конце концов, он не знает, что я намереваться использовать этот код только на платформах, где выравниваемый целочисленный / указательный доступ является естественным атомарным.
Еще одно обновление: Джефф Прешинг написал отличный пост в блоге объясняя разницу между явными заборами и встроенными («заборы» против «операций»). Случаи 2 и 3, по-видимому, не эквивалентны! (Во всяком случае, при определенных тонких обстоятельствах.)
Решение
Я считаю, что в коде есть гонка. Случай 1 и случай 2 не эквивалентны.
29,8 [atomics.fences]
-2- Забор синхронизируется с забором В если существуют атомарные операции Икс а также Y, оба работают на каком-то атомном объекте M, такой, что последовательность перед Икс, Икс модифицирует M, Y последовательность перед В, а также Y читает значение, написанное Икс или значение, записанное любым побочным эффектом в гипотетической последовательности выпуска Икс возглавил бы, если бы это была операция освобождения.
В случае 1 ваш защитный ограждение не синхронизируется с вашим защитным ограждением, потому что ptr это не атомарный объект, а хранилище и груз на ptr не атомарные операции.
Случай 2 и случай 3 эквивалентны (на самом деле, не совсем, см. комментарии и ответ LWimsey), так как ptr является атомарным объектом, а хранилище — атомарной операцией. (Параграфы 3 и 4 [atomic.fences] описывают, как забор синхронизируется с атомарной операцией и наоборот.)
Семантика ограждений определяется только по отношению к атомным объектам и атомным операциям. Является ли ваша целевая платформа и ваша реализация более строгими гарантиями (такими как обработка любого типа указателя как атомарного объекта), в лучшем случае определяется реализацией.
Нотабене как для случая 2, так и для случая 3 операция получения на ptr может произойти до магазина, и поэтому будет читать мусор из неинициализированных atomic<int*>, Простое использование операций захвата и выпуска (или ограждений) не гарантирует, что хранилище произойдет до загрузки, а только гарантирует, что если нагрузка считывает сохраненное значение, затем код корректно синхронизируется.
Другие решения
Несколько соответствующих ссылок:
- проект стандарта C ++ 11 (PDF, см. Пункты 1, 29 и 30);
- Hans-J. Обзор параллельной работы Boehm в C ++;
- McKenney, Boehm и Crowl о параллелизме в C ++;
- Замечания GCC по развитию параллелизма в C ++;
- примечания ядра Linux о параллелизме;
- связанный вопрос с ответами здесь на Stackoverflow;
- другой связанный вопрос с ответами;
- Cppmem, песочница для экспериментов с параллелизмом;
- Страница справки Cppmem;
- Вращение, инструмент для анализа логической согласованности параллельных систем;
- обзор барьеров памяти с аппаратной точки зрения (PDF).
Некоторые из вышеперечисленных могут заинтересовать вас и других читателей.
Несмотря на то, что различные ответы охватывают кусочки того, что представляет собой потенциальная проблема, и / или предоставляют полезную информацию, ни один ответ не описывает правильно проблемы, возможные для всех трех случаев.
Чтобы синхронизировать операции с памятью между потоками, для определения порядка используются барьеры освобождения и получения.
На диаграмме операции памяти A в потоке 1 не могут перемещаться через (односторонний) барьер освобождения (независимо от того, является ли это операцией освобождения в атомарном хранилище,
или отдельно стоящее ограждение с последующим расслабленным магазином атома). Следовательно, операции с памятью A гарантированно выполняются до атомарного хранилища.
То же самое касается операций с памятью B в потоке 2, которые не могут перемещаться вверх через барьер получения; следовательно, атомная нагрузка происходит перед операциями памяти B.
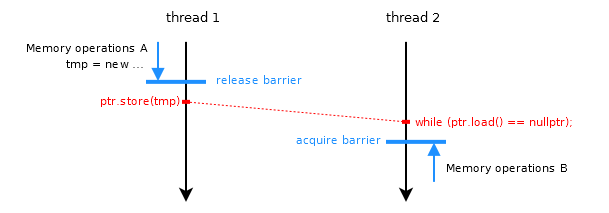
Атомный ptr сам обеспечивает упорядочение между потоками на основе гарантии того, что у него один порядок изменения. Как только поток 2 увидит значение для ptr,
Гарантируется, что сохранение (и, следовательно, операции с памятью A) произошло до загрузки. Поскольку загрузка гарантированно произойдет до операций памяти B,
правила транзитивности гласят, что операции с памятью A выполняются до того, как B завершится, а синхронизация завершена.
С этим, давайте посмотрим на ваши 3 случая.
Случай 1 сломан так как ptr, не атомарный тип, модифицируется в разных потоках. Это классический пример гонки данных, и он вызывает неопределенное поведение.
Случай 2 правильный. В качестве аргумента, целочисленное распределение с new чередуется перед операцией освобождения. Это эквивалентно:
// Case 2: atomic var, automatic fence
std::atomic<int*> ptr;
// ...
int *tmp = new int(-4);
ptr.store(tmp, std::memory_order_release);
Случай 3 сломан, хотя и тонким способом. Проблема в том, что хотя ptr задание правильно упорядочено после отдельного забора,
целочисленное распределение (new) также упорядочивается после ограждения, вызывая скачок данных в целочисленной ячейке памяти.
код эквивалентен:
// Case 3: atomic var, manual fence
std::atomic<int*> ptr;
// ...
std::atomic_thread_fence(std::memory_order_release);
int *tmp = new int(-4);
ptr.store(tmp, std::memory_order_relaxed);
Если вы сопоставите это с диаграммой выше, new оператор должен быть частью операций с памятью A. Будучи упорядоченным ниже границы освобождения,
гарантии упорядочения больше не выполняются, и целочисленное распределение может фактически быть переупорядочено с помощью операций памяти B в потоке 2.
Следовательно, load() в потоке 2 может вернуть мусор или вызвать другое неопределенное поведение.
Память, поддерживающая атомарную переменную, может быть когда-либо использована только для атомарного содержимого. Однако простая переменная, такая как ptr в случае 1, — это другая история. Как только компилятор имеет право писать в него, он может записать в него что угодно, даже значение временного значения, когда у вас заканчиваются регистры.
Помните, ваш пример патологически чист. Приведем чуть более сложный пример:
std::string* p = new std::string("Hello");
data($) = 42;
rl::atomic_thread_fence(rl::memory_order_release);
std::string* p2 = new std::string("Bye");
ptr($) = p;
для компилятора совершенно законно выбрать повторное использование вашего указателя
std::string* p = new std::string("Hello");
data($) = 42;
rl::atomic_thread_fence(rl::memory_order_release);
ptr($) = new std::string("Bye");
std::string* p2 = ptr($);
ptr($) = p;
Зачем это так? Я не знаю, возможно, какой-то экзотический прием, чтобы сохранить строку кэша или что-то в этом роде. Дело в том, что, так как ptr не является атомарным в случае 1, существует случай гонки между записью в строке ‘ptr ($) = p’ и чтением в ‘std :: string * p2 = ptr ($)’, приводя к неопределенному поведению. В этом простом тестовом примере компилятор может не использовать это право, и это может быть безопасно, но в более сложных случаях компилятор имеет право злоупотреблять ptr, как ему угодно, и Relacy это ловит.
Моя любимая статья на эту тему: http://software.intel.com/en-us/blogs/2013/01/06/benign-data-races-what-could-possibly-go-wrong
Гонка в первом примере происходит между публикацией указателя и материалом, на который он указывает. Причина в том, что у вас есть создание и инициализация указателя после забор (= на той же стороне, что и указатель публикации):
int* ptr; //noop
std::atomic_thread_fence(std::memory_order_release); //fence between noop and interesting stuff
ptr = new int(-4); //object creation, initalization, and publication
Если мы предположим, что доступ ЦП к правильно выровненным указателям является атомарным, код можно исправить, написав это:
int* ptr; //noop
int* newPtr = new int(-4); //object creation & initalization
std::atomic_thread_fence(std::memory_order_release); //fence between initialization and publication
ptr = newPtr; //publication
Обратите внимание, что даже при том, что это может хорошо работать на многих машинах, в стандарте C ++ нет абсолютно никакой гарантии атомарности последней строки. Так лучше использовать atomic<> переменные на первом месте.