Увеличено количество кешей при векторизации кода
Я векторизовал скалярное произведение между 2 векторами с SSE 4.2 и AVX 2, как вы можете видеть ниже. Код был скомпилирован с GCC 4.8.4 с флагом оптимизации -O2. Как и ожидалось, производительность улучшилась с обоими (и AVX 2 быстрее, чем с SSE 4.2), но когда я профилировал код с PAPI, я обнаружил, что общее количество пропусков (в основном L1 и L2) значительно увеличилось:
Без векторизации:
PAPI_L1_TCM: 784,112,091
PAPI_L2_TCM: 195,315,365
PAPI_L3_TCM: 79,362
С SSE 4.2:
PAPI_L1_TCM: 1,024,234,171
PAPI_L2_TCM: 311,541,918
PAPI_L3_TCM: 68,842
С AVX 2:
PAPI_L1_TCM: 2,719,959,741
PAPI_L2_TCM: 1,459,375,105
PAPI_L3_TCM: 108,140
Может ли быть что-то не так с моим кодом или это нормальное поведение?
Код AVX 2:
double vec_dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
const int loopBound = n-3;
__m256d vsum, vecPi, vecCi, vecQCi;
vsum = _mm256_set1_pd(0);
double * const pA = vecs.x+start_a ;
double * const pB = vecs.x+start_b ;
for( ; i<loopBound ;i+=4){
vecPi = _mm256_loadu_pd(&(pA)[i]);
vecCi = _mm256_loadu_pd(&(pB)[i]);
vecQCi = _mm256_mul_pd(vecPi,vecCi);
vsum = _mm256_add_pd(vsum,vecQCi);
}
vsum = _mm256_hadd_pd(vsum, vsum);
dot = ((double*)&vsum)[0] + ((double*)&vsum)[2];
for( ; i<n; i++)
dot += pA[i] * pB[i];
return dot;
}
Код SSE 4.2:
double vec_dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
const int loopBound = n-1;
__m128d vsum, vecPi, vecCi, vecQCi;
vsum = _mm_set1_pd(0);
double * const pA = vecs.x+start_a ;
double * const pB = vecs.x+start_b ;
for( ; i<loopBound ;i+=2){
vecPi = _mm_load_pd(&(pA)[i]);
vecCi = _mm_load_pd(&(pB)[i]);
vecQCi = _mm_mul_pd(vecPi,vecCi);
vsum = _mm_add_pd(vsum,vecQCi);
}
vsum = _mm_hadd_pd(vsum, vsum);
_mm_storeh_pd(&dot, vsum);
for( ; i<n; i++)
dot += pA[i] * pB[i];
return dot;
}
Не векторизованный код:
double dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
for (i = 0; i < n; ++i)
{
dot += vecs.x[start_a+i] * vecs.x[start_b+i];
}
return dot;
}
Редактировать: сборка не векторизованного кода:
0x000000000040f9e0 <+0>: mov (%rcx),%r8d
0x000000000040f9e3 <+3>: test %r8d,%r8d
0x000000000040f9e6 <+6>: jle 0x40fa1d <dotProduct(vec const&, unsigned int const&, unsigned int const&, int const&)+61>
0x000000000040f9e8 <+8>: mov (%rsi),%eax
0x000000000040f9ea <+10>: mov (%rdi),%rcx
0x000000000040f9ed <+13>: mov (%rdx),%edi
0x000000000040f9ef <+15>: vxorpd %xmm0,%xmm0,%xmm0
0x000000000040f9f3 <+19>: add %eax,%r8d
0x000000000040f9f6 <+22>: sub %eax,%edi
0x000000000040f9f8 <+24>: nopl 0x0(%rax,%rax,1)
0x000000000040fa00 <+32>: mov %eax,%esi
0x000000000040fa02 <+34>: lea (%rdi,%rax,1),%edx
0x000000000040fa05 <+37>: add $0x1,%eax
0x000000000040fa08 <+40>: vmovsd (%rcx,%rsi,8),%xmm1
0x000000000040fa0d <+45>: cmp %r8d,%eax
0x000000000040fa10 <+48>: vmulsd (%rcx,%rdx,8),%xmm1,%xmm1
0x000000000040fa15 <+53>: vaddsd %xmm1,%xmm0,%xmm0
0x000000000040fa19 <+57>: jne 0x40fa00 <dotProduct(vec const&, unsigned int const&, unsigned int const&, int const&)+32>
0x000000000040fa1b <+59>: repz retq
0x000000000040fa1d <+61>: vxorpd %xmm0,%xmm0,%xmm0
0x000000000040fa21 <+65>: retq
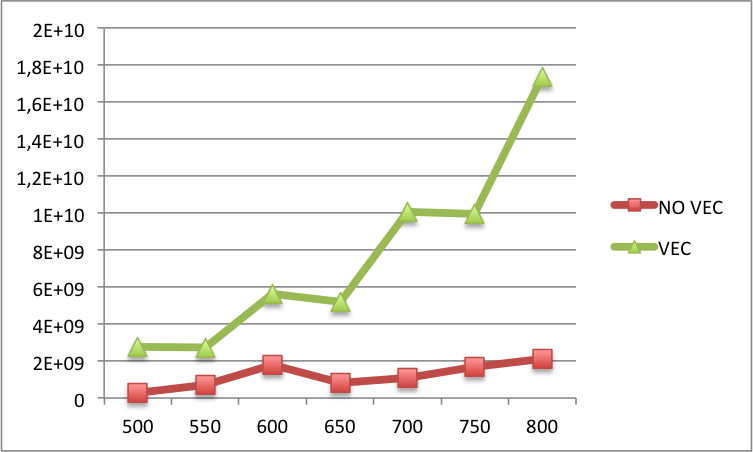
Edit2: ниже вы можете найти сравнение пропусков кэша L1 между векторизованным и не векторизованным кодом для больших N (N на x-метке и промахов L1 на y-метке). В основном, для больших N еще больше промахов в векторизованной версии, чем в не векторизованной версии.
Решение
Ростислав прав, что компилятор выполняет автоматическую векторизацию, и из документации GCC по -O2:
«-O2 Оптимизируйте еще больше. GCC выполняет почти все поддерживаемые оптимизации, которые не требуют компромисса со скоростью пространства». (Отсюда: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html)
GCC с флагом -O2 пытается создать наиболее эффективный код, не отдавая предпочтения ни размеру кода, ни скорости.
Таким образом, с точки зрения циклов ЦП, авто-векторизованный код -O2 потребует наименьшего количества ватт для запуска, но не будет самым быстрым или наименьшим кодом. Это лучший случай для кода, который выполняется на мобильных устройствах и в многопользовательских системах, и они, как правило, являются предпочтительным использованием C ++. Если вам нужна абсолютная максимальная скорость независимо от того, сколько ватт он использует, попробуйте -O3 или -Ofast, если ваша версия GCC поддерживает их, или используйте оптимизированные для рук более быстрые решения.
Причиной этого, вероятно, является сочетание двух факторов.
Во-первых, более быстрый код генерирует больше запросов к памяти / кэшу за то же время, что подчеркивает алгоритмы прогнозирования перед выборкой. Кэш L1 не очень большой, обычно 1–3 МБ, и используется всеми запущенными процессами на этом ядре ЦП, поэтому ядро ЦП не может выполнять предварительную выборку, пока ранее предварительно выбранный блок больше не используется. Если код работает быстрее, для предварительной выборки между блоками остается меньше времени, а в коде, эффективно транслирующем линии, будет происходить больше промахов кэша до полной остановки ядра ЦП до завершения ожидающих выборок.
И, во-вторых, современные операционные системы обычно разделяют однопоточные процессы между несколькими ядрами, динамически регулируя сродство потоков, чтобы использовать дополнительный кэш для нескольких ядер, даже если он не может выполнять какой-либо код параллельно — например, Заполните кэш ядра 0 своими данными, а затем запустите его, заполняя кэш ядра 1, затем запустите ядро 1, одновременно заполняя кэш ядра 0, циклически перебирая, пока не завершите. Этот псевдопараллельность улучшает общую скорость однопоточных процессов и должна значительно уменьшить количество кеш-ошибок, но может быть выполнена только в очень специфических обстоятельствах … особых обстоятельствах, для которых хорошие компиляторы будут генерировать код всякий раз, когда это возможно.
Другие решения
Как вы можете видеть в некоторых комментариях, ошибки в кеше происходят из-за увеличения производительности.
Например, с недавними процессорами вы сможете выполнять 2 AVX2 add или mul в каждом цикле, так что 512 бит в каждом цикле. Время, необходимое для загрузки данных, будет выше, так как для этого потребуется несколько строк кэша.
Кроме того, в зависимости от того, как настроена ваша система, гиперпоточности, аффинности и т. Д., Ваш планировщик может одновременно выполнять другие действия, загрязняя кэш-память другими потоками / процессами.
Последнее, что нужно. Процессоры теперь достаточно эффективны, чтобы распознавать простые шаблоны как шаблоны с очень маленькими циклами, а затем автоматически использовать предварительную выборку после нескольких итераций. В любом случае этого будет недостаточно для решения проблемы размера кэша.
Попробуйте разные размеры для N, вы должны увидеть интересные результаты.
Кроме того, сначала выровняйте данные и убедитесь, что если вы используете 2 переменные, они не разделяют одну и ту же строку кэша.