STL Что такое произвольный доступ и последовательный доступ?
Так что мне любопытно узнать, что такое произвольный доступ?
Я искал немного, и не мог найти много. Теперь у меня есть понимание, что «блоки» в контейнере расположены случайным образом (как видно Вот). Произвольный доступ означает, что я могу получить доступ к каждому блоку контейнера независимо от того, в какой позиции (поэтому я могу прочитать то, что он говорит в позиции 5, не пройдя все блоки до этого), в то время как при последовательном доступе мне нужно пройти 1-й, 2-й, 3-й и 4-й, чтобы добраться до 5-го блока.
Я прав? Или если нет, то кто-то может объяснить мне, что такое произвольный доступ и последовательный доступ?
Решение
Последовательный доступ означает, что стоимость доступа к 5-му элементу в 5 раз превышает стоимость доступа к первому элементу или, по крайней мере, увеличение стоимости связано с положением элементов в наборе. Это связано с тем, что для доступа к 5-му элементу набора сначала необходимо выполнить операцию, чтобы найти 1-й, 2-й, 3-й и 4-й элементы, поэтому для доступа к 5-му элементу требуется 5 операций.
Произвольный доступ означает, что доступ к любому элементу в наборе имеет ту же стоимость, что и любой другой элемент в наборе. Поиск 5-го элемента множества — это всего лишь одна операция.
Таким образом, доступ к случайному элементу в структуре данных произвольного доступа будет стоить O (1), тогда как доступ к случайному элементу в последовательной структуре данных будет стоить O (n / 2) -> O (n). , N / 2 исходит из того, что если вы хотите получить доступ к случайному элементу в наборе 100 раз, средняя позиция этого элемента будет примерно на половине пути от набора. Таким образом, для набора из n элементов получается n / 2 (который в больших обозначениях O может быть просто приближен к n).
Что-то, что вы могли бы найти классным:
Хеш-карты являются примером структуры данных, которая реализует произвольный доступ. Круто отметить, что при столкновении хэшей в хэш-карте два сопоставленных элемента хранятся в последовательном связанном списке в этом сегменте на хэш-карте. Таким образом, это означает, что если у вас есть 100% коллизий для хэш-карты, вы фактически получаете последовательное хранилище.
Вот изображение hashmap, иллюстрирующее то, что я описываю:
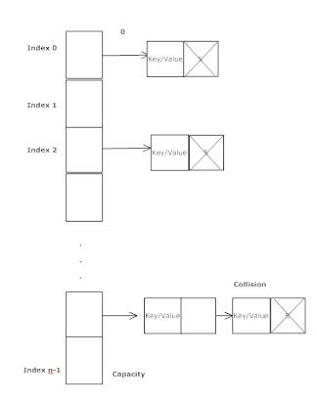
Это означает, что наихудший сценарий для хэш-карты — это фактически O (n) для доступа к элементу, то же самое, что средний случай для последовательного хранения или, если быть более точным, нахождение элемента в хэш-карте равно Ω (n), O (1). ) и Θ (1). Где Ω — наихудший случай, Θ — лучший случай, а O — средний случай.
Так:
Последовательный доступ: Нахождение случайного элемента в наборе из n элементов — это Ω (n), O (n / 2) и Θ (1), которое для очень больших чисел становится Ω (n), O (n) и Θ (1) ,
Произвольный доступ: Нахождение случайного элемента в наборе из n элементов — это Ω (n / 2), O (1) и Θ (1), которое для очень больших чисел становится Ω (n), O (1) и Θ (1)
Преимущество произвольного доступа заключается в том, что он обеспечивает более высокую производительность для доступа к элементам, однако структуры данных с последовательным хранением обеспечивают преимущества в других областях.
Второе редактирование для @ sumsar1812:
Я хочу предвосхитить это так, как я понимаю преимущества / варианты использования последовательного хранения, но я не настолько уверен в своем понимании преимуществ последовательных контейнеров, как в своем ответе выше. Поэтому, пожалуйста, поправьте меня, если я ошибаюсь.
Последовательное хранение полезно, потому что данные фактически будут храниться последовательно в памяти.
На самом деле вы можете получить доступ к следующему члену последовательно сохраненного набора данных, сместив указатель на предыдущий элемент этого набора на количество байтов, необходимое для хранения одного элемента этого типа.
Таким образом, поскольку для хранения со знаком int требуется 8 байт, если у вас есть фиксированный массив целых чисел с указателем на первое целое число:
int someInts[5];
someInts[1] = 5;
someInts — указатель, указывающий на первый элемент этого массива. Добавление 1 к этому указателю просто смещает туда, куда он указывает в памяти, на 8 байт.
(someInts+1)* //returns 5
Это означает, что если вам нужно получить доступ к каждому элементу в вашей структуре данных в определенном порядке, это будет происходить намного быстрее, поскольку каждый поиск последовательного хранилища просто добавляет постоянное значение к указателю.
Для хранилища с произвольным доступом нет гарантии, что каждый элемент хранится даже рядом с другими элементами. Это означает, что каждый поиск будет дороже, чем просто добавление постоянной суммы.
Контейнеры хранения с произвольным доступом все еще могут имитировать то, что представляется упорядоченным списком элементов, с помощью итератора. Однако до тех пор, пока вы разрешите поиск элементов с произвольным доступом, не будет никакой гарантии, что эти элементы будут последовательно храниться в памяти. Это означает, что, хотя контейнер может демонстрировать поведение как контейнера с произвольным доступом, так и последовательного контейнера, он не будет демонстрировать преимущества последовательного контейнера.
Таким образом, если порядок элементов в вашем контейнере должен быть осмысленным, или вы планируете выполнять итерации и работать с каждым элементом в наборе данных, тогда вы можете воспользоваться последовательным контейнером.
По правде говоря, он все еще становится немного сложнее, потому что связанный список, который является последовательным контейнером, фактически не хранит последовательно в памяти, в то время как вектор, другой последовательный контейнер, делает это. Вот хорошая статья, которая лучше, чем я, объясняет варианты использования для каждого конкретного контейнера.
Другие решения
В этом есть два основных аспекта, и неясно, какой из этих двух вопросов более актуален для вашего вопроса. Одним из таких аспектов является доступ к содержимому контейнера STL через итераторы, где эти итераторы разрешают либо произвольный доступ, либо прямой (последовательный) доступ. Другой аспект заключается в доступе к контейнеру или даже к самой памяти в случайном или последовательном порядке.
Итераторы — произвольный доступ против последовательного доступа
Чтобы начать с итераторов, возьмем два примера: std::vector<T> а также std::list<T>, Вектор хранит массив значений, тогда как список хранит связанный список значений. Первый хранится последовательно в памяти, и это обеспечивает произвольный произвольный доступ: вычисление местоположения любого элемента происходит так же быстро, как вычисление местоположения следующего элемента. Таким образом, последовательное хранение дает вам эффективный произвольный доступ, а итератор итератор произвольного доступа.
Напротив, список выполняет отдельное распределение для каждого узла, и каждый узел знает только, где находятся его соседи. Таким образом, вычисление местоположения случайного не соседнего узла не может быть выполнено напрямую. Любая попытка сделать это должна пройти через все промежуточные узлы, и поэтому алгоритмы, которые пытаются пропустить узлы, могут работать плохо. Непоследовательное хранение дает рандомизированные местоположения и, таким образом, только эффективный последовательный доступ. Таким образом, итератор, который предоставляет список, является двунаправленный итератор, один из нескольких разных последовательных итераторов.
Память — произвольный доступ против последовательного доступа
Однако есть еще одна морщина в вашем вопросе. Части итератора обращаются только к обходу контейнера. Тем не менее, под этим ЦП будет обращаться к самой памяти по определенному шаблону. В то время как на высоком уровне ЦП способен адресовать любой случайный адрес без дополнительных затрат на вычисление его местоположения (это похоже на большой вектор), на практике чтение памяти включает в себя кеширование и множество тонкостей, которые делают доступ к различным частям памяти разным времени.
Например, как только вы начинаете работать с довольно большим набором данных, даже если вы работаете с вектором, более эффективно обращаться ко всем элементам в последовательном порядке, чем к всем элементам в некотором случайном порядке. В отличие от списка не делает это возможным. Поскольку узлы списка даже не обязательно расположены в последовательных ячейках памяти, даже последовательный доступ к элементам списка может не считывать память последовательно и может быть более дорогим из-за этого.
Сами термины не подразумевают никаких характеристик производительности, как говорит @echochamber. Термины относятся только к способу доступа.
«Произвольный доступ» относится к доступу к элементам в контейнере в произвольном порядке. std::vector пример контейнера C ++, который отлично подходит для произвольного доступа std::stack пример контейнера C ++, который даже не разрешает произвольный доступ
«Последовательный доступ» относится к доступу к элементам по порядку. Это относится только к заказанным контейнерам. Например, некоторые контейнеры оптимизированы для последовательного доступа, а не произвольного доступа. std::list,
Вот некоторый код, чтобы показать разницу:
// random access. picking elements out, regardless of ordering or sequencing.
// The important factor is that we are selecting items by some kind of
// index.
auto a = some_container[25];
auto b = some_container[1];
auto c = some_container["hi"];
// sequential access. Here, there is no need for an index.
// This implies that the container has a concept of ordering, where an
// element has neighbors
for(container_type::iterator it = some_container.begin();
it != some_container.end();
++ it)
{
auto d = *it;
}