Сравнительный вызов функции шаблона variadic
Я использовал Quick Bench (см. Ссылку ниже), чтобы измерить производительность между декодированием буфера с вызовом функции с аргументами шаблона variadic и декодированием того же буфера с вызовом функции без расширения пакета variadic.
Любая идея о том, как сделать реализацию с переменной скоростью наравне с другой реализацией?
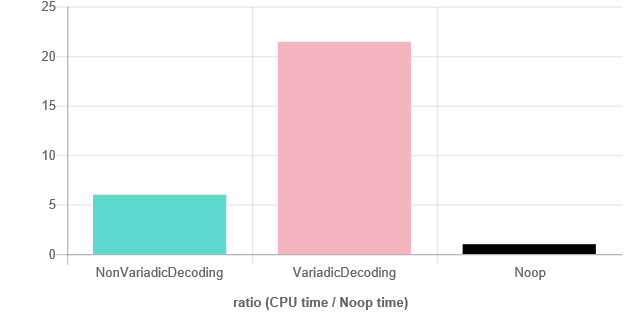
Результатом теста является соотношение (время процессора / время цикла). Тест работает на пуле машин AWS, нагрузка которых неизвестна. Цель состоит в том, чтобы дать достаточно хорошее сравнение между двумя фрагментами кода, работающими в одинаковых условиях. Процессорное время для функции невариантного шаблона составляло 5,9, а для реализации с переменным числом 21,3. Компилятор: Clang 5.0 с уровнем оптимизации O3.
#include <cstdint>
#include <cstring>
#include <string>
#include <type_traits>
namespace core { namespace decoder
{
class LittleEndian
{
public:
LittleEndian(const LittleEndian&) = delete;
LittleEndian& operator=(const LittleEndian&) = delete;
public:
constexpr LittleEndian(const std::uint8_t* buffer, size_t size) noexcept
: m_buffer(buffer),
m_size(size)
{}
constexpr bool decodeU8(
size_t& offset, std::uint8_t& decodedValue) const noexcept
{
if (offset >= m_size)
return false;
decodedValue = m_buffer[offset];
offset += sizeof(std::uint8_t);
return true;
}
constexpr bool decodeU16(
size_t& offset, std::uint16_t& decodedValue) const noexcept
{
if (offset + sizeof(std::uint16_t) > m_size)
return false;
const uint8_t b0 = m_buffer[offset], b1 = m_buffer[offset + 1];
decodedValue = (b0 << 0) | (b1 << 8);
offset += sizeof(std::uint16_t);
return true;
}
constexpr bool decodeU32(
size_t& offset, std::uint32_t& decodedValue) const noexcept
{
if (offset + sizeof(std::uint32_t) > m_size)
return false;
const uint8_t b0 = m_buffer[offset], b1 = m_buffer[offset + 1], b2 = m_buffer[offset + 2], b3 = m_buffer[offset + 3];
decodedValue = (b0 << 0) | (b1 << 8) | (b2 << 16) | (b3 << 24);
offset += sizeof(std::uint32_t);
return true;
}
constexpr bool decodeU64(
size_t& offset, std::uint64_t& decodedValue) const noexcept
{
if (offset + sizeof(std::uint64_t) > m_size)
return false;
const uint8_t b0 = m_buffer[offset], b1 = m_buffer[offset + 1],
b2 = m_buffer[offset + 2], b3 = m_buffer[offset + 3],
b4 = m_buffer[offset + 4], b5 = m_buffer[offset + 5],
b6 = m_buffer[offset + 6], b7 = m_buffer[offset + 7];
decodedValue = (static_cast<std::uint64_t>(b0) << 0) |
(static_cast<std::uint64_t>(b1) << 8) |
(static_cast<std::uint64_t>(b2) << 16) |
(static_cast<std::uint64_t>(b3) << 24) |
(static_cast<std::uint64_t>(b4) << 32) |
(static_cast<std::uint64_t>(b5) << 40) |
(static_cast<std::uint64_t>(b6) << 48) |
(static_cast<std::uint64_t>(b7) << 56);
offset += sizeof(std::uint64_t);
return true;
}
private:
const std::uint8_t* m_buffer;
const size_t m_size;
};
template<typename EndianDecoderT>
class ByteDecoder
{
public:
ByteDecoder(const ByteDecoder&) = delete;
ByteDecoder& operator=(const ByteDecoder&) = delete;
public:
constexpr ByteDecoder(const std::uint8_t* buffer, size_t size)
: m_buffer(buffer),
m_size(size),
m_endianDecoder(buffer, size)
{}
template<typename ...Args>
constexpr bool decode(size_t offset, Args&... args) const noexcept
{
bool success = true;
using expand_type = int[];
expand_type
{
([&success] (auto result) noexcept
{
success = (!success || !result) ? false : true;
} (decodeValue(offset, args)), 0)...
};
return success;
}
template<typename T>
constexpr bool decode(size_t offset, T& decodedValue) const noexcept
{
return decodeValue(offset, decodedValue);
}
private:
template<typename T>
constexpr bool decodeValue(
size_t &offset, T& decodedValue) const noexcept
{
if constexpr (std::is_same< std::decay_t<T>, std::uint8_t>::value)
return m_endianDecoder.decodeU8(offset, decodedValue);
if constexpr (std::is_same< std::decay_t<T>, std::uint16_t>::value)
return m_endianDecoder.decodeU16(offset, decodedValue);
if constexpr (std::is_same< std::decay_t<T>, std::uint32_t>::value)
return m_endianDecoder.decodeU32(offset, decodedValue);
if constexpr (std::is_same< std::decay_t<T>, std::uint64_t>::value)
return m_endianDecoder.decodeU64(offset, decodedValue);
if constexpr (std::is_same<char *, typename std::decay<T>::type>::value ||
std::is_same<char const *, typename std::decay<T>::type>::value)
return decodeCHR(offset, decodedValue);
return false;
}
template<size_t SIZE>
constexpr bool decodeCHR(
size_t &offset, char (&buffer)[SIZE]) const noexcept
{
if (offset + SIZE > m_size)
return false;
memset(&buffer[0], 0x00, sizeof(char) * SIZE);
memcpy(&buffer[0], &m_buffer[offset], sizeof(char) * (std::min)(SIZE, std::extent<decltype(buffer)>::value - 1));
offset += SIZE;
return true;
}
private:
const std::uint8_t* m_buffer;
const size_t m_size;
EndianDecoderT m_endianDecoder;
};
}} // namespace core::decoder
static void NonVariadicDecoding(benchmark::State& state) {
// Code inside this loop is measured repeatedly
constexpr std::uint8_t littleEndian[] = { 0x0D, 0x0C, 0x84, 0x03, 0x00, 0x00, 'H', 'e', 'l', 'l', 'o', '\0', 0x84, 0x03, 0x84, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };
core::decoder::ByteDecoder<core::decoder::LittleEndian> decoder(littleEndian, sizeof(littleEndian));for (auto _ : state) {
size_t offset = 0;
struct DecodedValue
{
std::uint16_t v1_U16;
std::uint32_t v2_U32;
char v3_CHR[6];
std::uint16_t v4_U16;
std::uint64_t v5_U64;
};
DecodedValue dv;
decoder.decode(offset, dv.v1_U16);
offset += sizeof(dv.v1_U16);
decoder.decode(offset, dv.v2_U32);
offset += sizeof(dv.v2_U32);
decoder.decode(offset, dv.v3_CHR);
offset += sizeof(dv.v3_CHR);
decoder.decode(offset, dv.v4_U16);
offset += sizeof(dv.v4_U16);
decoder.decode(offset, dv.v5_U64);
benchmark::DoNotOptimize(dv);
}
}
// Register the function as a benchmark
BENCHMARK(NonVariadicDecoding);
static void VariadicDecoding(benchmark::State& state) {
// Code before the loop is not measured
constexpr std::uint8_t littleEndian[] = { 0x0D, 0x0C, 0x84, 0x03, 0x00, 0x00, 'H', 'e', 'l', 'l', 'o', '\0', 0x84, 0x03, 0x84, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };
core::decoder::ByteDecoder<core::decoder::LittleEndian> decoder(littleEndian, sizeof(littleEndian));
for (auto _ : state) {
struct DecodedValue
{
std::uint16_t v1_U16;
std::uint32_t v2_U32;
char v3_CHR[6];
std::uint16_t v4_U16;
std::uint64_t v5_U64;
};
DecodedValue dv;
decoder.decode(0, dv.v1_U16, dv.v2_U32, dv.v3_CHR, dv.v4_U16, dv.v5_U64);
benchmark::DoNotOptimize(dv);
}
}
BENCHMARK(VariadicDecoding);
Решение
Если у вас есть рекурсивные вызовы вашей вариационной реализации и вы используете идеальную переадресацию, то вы можете добиться лучшей производительности:
template <typename Type>
constexpr bool decode_impl(size_t offset, Type&& value) const noexcept
{
return decodeValue(offset, std::forward<Type>(value));
}
template <typename First, typename Second, typename... Other>
constexpr bool decode_impl(size_t offset, First&& first, Second&& second, Other&&... others) const noexcept
{
return decode_impl(offset, std::forward<First>(first)) && decode_impl(offset, std::forward<Second>(second), std::forward<Other>(others)...);
}
template<typename ...Args>
constexpr bool decode(size_t offset, Args&&... args) const noexcept
{
return decode_impl(offset, std::forward<Args>(args)...);
}
Другие решения
Других решений пока нет …