SFML-потоки не работают параллельно
Я пытаюсь понять, как работают потоки и мьютексы, но сейчас я сталкиваюсь с некоторой путаницей, я взял следующий код из официальных учебных пособий по SFML 1.6:
#include <SFML/System.hpp>
#include <iostream>
void ThreadFunction(void* UserData)
{
// Print something...
for (int i = 0; i < 10; ++i)
std::cout << "I'm the thread number 1" << std::endl;
}
int main()
{
// Create a thread with our function
sf::Thread Thread(&ThreadFunction);
// Start it !
Thread.Launch();
// Print something...
for (int i = 0; i < 10; ++i)
std::cout << "I'm the main thread" << std::endl;
return EXIT_SUCCESS;
}
И это сказал
Таким образом, текст из обеих тем будет отображаться одновременно.
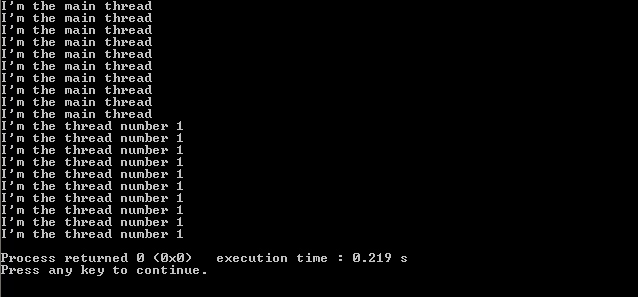
Однако этого не происходит, сначала выполняется первый поток, затем второй поток, разве они не должны запускаться одновременно? Я использую Codeblocks IDE в Windows XP с пакетом обновления 3 (SP3) под управлением SFML 1.6. Я делаю что-то не так, или я неправильно понял, как они работают? С моей точки зрения, потоки должны выполняться одновременно, поэтому на выходе должно быть что-то вроде
«текст из темы 1
текст из темы 2
текст из темы 1
и так далее»
Решение
… разве они не должны бежать одновременно?
Ну, это зависит.
Если у вас есть два или более ядер, они может запустить одновременно.
Даже если у вас есть доступное оборудование, ваша ОС сама решает, как планировать ваши потоки: хотите ли вы поощрять ваша операционная система для чередования обоих потоков (вы не можете форсировать это без дополнительной работы), попробуйте добавить sleep или же nanosleep или же yield вызовы ваших циклов (точные примитивы будут зависеть от вашей платформы).
Если это поможет вам создать интуитивное представление о том, как и почему ядро будет принимать решения о планировании, обратите внимание, что большинство архитектур ЦП сохраняют значительное количество состояний (таблицы прогнозирования ветвлений, кэши данных и инструкций), которые действительно хороши для оптимизации одного потока выполнение.
Поэтому, как правило, более эффективно позволить заданному потоку работать на данном ядре как можно дольше, чтобы минимизировать количество переключаемых контекстов, которых можно избежать, пропусков кэша и неправильных предсказаний.
В настоящее время, временная привязка часто используется как своего рода компромисс между лучшими пропускная способность для каждого отдельного процесса, и лучший задержка или реагирование на внешние события. Поток может блокировать (ожидая внешнего события, такого как пользовательский ввод или ввод-вывод устройства, потому что он явно синхронизируется с другим потоком, или явно спит или дает), в этом случае другой поток будет запланирован, в то время как первый не может делать успехи, но в противном случае он будет обычно работать до тех пор, пока ядро не прекратит его в конце выделенного временного интервала.
Когда родительский поток создает дочерний поток, я не хотел бы догадываться, что является «более горячим» в текущем ядре, поэтому разумным значением по умолчанию является разрешение родителю завершить свой временной интервал (если он не блокируется).
Дочерний поток, вероятно, сразу запускается, но если он не опережает родительский поток, то не очевидно, почему он должен немедленно опередить поток на другом ядре. В конце концов, он все еще находится в том же процессе, что и родительский поток, и разделяет ту же память, карты адресов и другие ресурсы: если не используется другое ядро полностью в простое, лучшее место для планирования дочернего процесса — это, вероятно, то же ядро, что и его родительский, потому что есть хороший шанс, что родительский ресурс хранит эти общие ресурсы в кеше.
Итак, причина, по которой ваши потоки не чередуются, вероятно ни выполняется для значительной доли временного интервала до завершения процесса, и при этом не блокирует ввод-вывод и не выдает явно (stdout не блокирует этот объем данных, так как он легко буферизуется).
Другие решения
Других решений пока нет …