Самый быстрый способ передачи данных вершин в GPU в OpenGL / CUDA
Я должен загрузить только конкретные элементы (более тысячи) массива вершин на каждом кадре —
или весь регион между первым и последним измененным значением, однако это довольно неэффективно, поскольку есть вероятность повторной загрузки всего массива, в любом случае будет загружено много неизмененных значений.
Вопрос также состоит в том, какие самые быстрые способы загрузки данных вершин в графический процессор.
Есть несколько способов сделать это:
glBufferData() / glBufferSubData() // Standard upload to buffer
glBufferData() // glBufferData with double buffer
glMapBuffer() // Mapping video memory
cudaMemcpy() // CUDA memcopy from host to device vertex buffer
Какой будет самым быстрым? Я особенно обеспокоен образом CUDA и это отличие от стандартных методов OpenGL. Это быстрее, чем glBufferData () или glMapBuffer ()?
Решение
Скорость копирования одних и тех же данных с хоста на устройство должна быть одинаковой независимо от того, какой API копирования вы используете.
Однако размер копируемого блока данных имеет большое значение. Вот тест, показывающий взаимосвязь между размером данных и скоростью копирования с использованием CUDA. cudaMemcpy(),
CUDA — насколько медленнее идет передача по PCI-E?
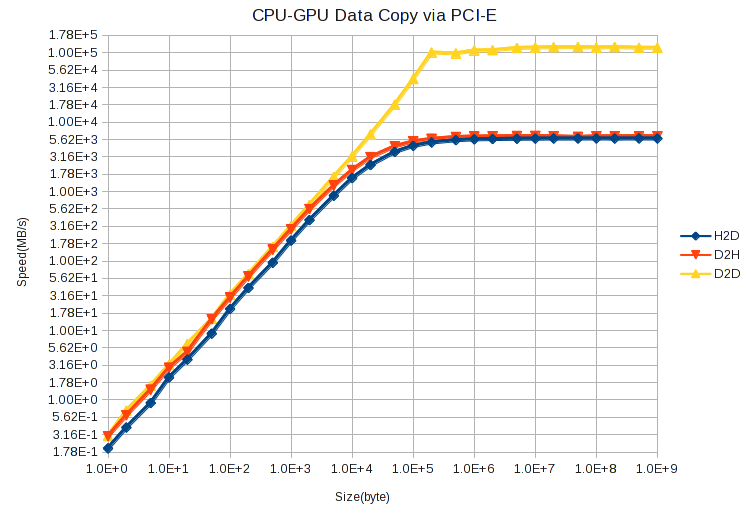
Вы можете просто оценить среднюю скорость по приведенному выше рисунку, если знаете количество API копирования, которое вы будете вызывать, и размер данных каждой копии.
Когда размер элемента небольшой, а количество элементов большое, копирование только измененных элементов по отдельности с хоста на устройство путем тысячелетнего вызова API копирования — определенно не очень хорошая идея.
Другие решения
Других решений пока нет …