Реализация скип-граммы в тензорном потоке / моделях — субсэмплирование часто встречающихся слов
Я имею в виду некоторые эксперименты, связанные с моделью скипграмм. Поэтому я начал изучать и модифицировать оптимизированную реализацию в tensorflow / модели хранилище в tutorials/embedding/word2vec_kernels.cc, Внезапно я оказался над той частью, где делается выборка корпуса.
Согласно статье Томаша Миколова (https://arxiv.org/abs/1310.4546, уравнение 5), слово должно быть хранится с вероятностью
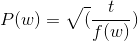
где t обозначает пороговый параметр (согласно бумаге, выбранной как 10^-5), а также f(w) частота слова w,
но код в word2vec_kernels.cc является следующее:
float keep_prob = (std::sqrt(word_freq / (subsample_ * corpus_size_)) + 1) *
(subsample_ * corpus_size_) / word_freq;
которые могут быть преобразованы в ранее представленные обозначения как
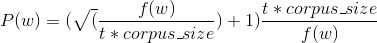
Какова мотивация этого изменения? Это просто моделировать «какое-то отношение» к размеру корпуса в этой формуле? Или это какая-то трансформация оригинальной формулы? Был ли он выбран опытным путем?
редактировать: ссылка на упомянутый файл на github
https://github.com/tensorflow/models/blob/master/tutorials/embedding/word2vec_kernels.cc
Решение
Хорошо, так что я думаю, что без corpus_sizeграфик выглядит примерно так же, как исходная формула. Размер корпуса добавляет отношение к размеру корпуса к формуле, а также «она работает с большими числами», поэтому мы можем вычислить вероятность сброса / сохранения без нормализации частоты слова для правильного распределения.
Другие решения
Других решений пока нет …