python — производительность типов xtensor против NumPy для простого сокращения
Я пытался xtensor-питон и начал с написания очень простой функции суммы, после использования настройка печенья и включение SIMD-функций с xsimd.
inline double sum_pytensor(xt::pytensor<double, 1> &m)
{
return xt::sum(m)();
}
inline double sum_pyarray(xt::pyarray<double> &m)
{
return xt::sum(m)();
}
Используемый setup.py чтобы построить мой модуль Python, а затем протестировал функцию суммирования на массивах NumPy, построенных из np.random.randn разных размеров, по сравнению с np.sum,
import timeit
def time_each(func_names, sizes):
setup = f'''
import numpy; import xtensor_basics
arr = numpy.random.randn({sizes})
'''
tim = lambda func: min(timeit.Timer(f'{func}(arr)',
setup=setup).repeat(7, 100))
return [tim(func) for func in func_names]
from functools import partial
sizes = [10 ** i for i in range(9)]
funcs = ['numpy.sum',
'xtensor_basics.sum_pyarray',
'xtensor_basics.sum_pytensor']
sum_timer = partial(time_each, funcs)
times = list(map(sum_timer, sizes))
Этот (возможно, некорректный) тест показал, что производительность xtensor для этой базовой функции ухудшилась для больших массивов по сравнению с NumPy.
numpy.sum xtensor_basics.sum_pyarray xtensor_basics.sum_pytensor
1 0.000268 0.000039 0.000039
10 0.000258 0.000040 0.000039
100 0.000247 0.000048 0.000049
1000 0.000288 0.000167 0.000164
10000 0.000568 0.001353 0.001341
100000 0.003087 0.013033 0.013038
1000000 0.045171 0.132150 0.132174
10000000 0.434112 1.313274 1.313434
100000000 4.180580 13.129517 13.129058
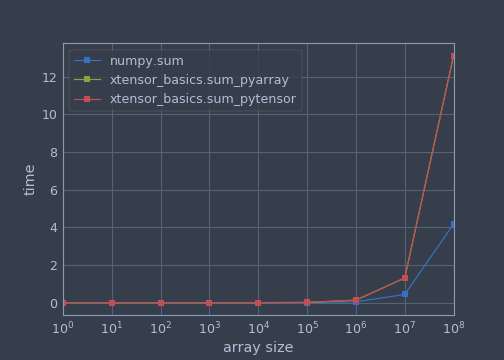
Есть идеи, почему я это вижу? Я предполагаю, что это то, что NumPy использует, чего не делает xtensor (пока), но я не был уверен, что это может быть для такого простого сокращения. Я вырыл xmath.hpp но не видел ничего очевидного, и ничего подобного не упоминается в документации.
Версии
numpy 1.13.3
openblas 0.2.20
python 3.6.3
xtensor 0.12.1
xtensor-python 0.14.0
Решение
вау это совпадение! Я работаю над этим ускорением!
Сумма xtensor — это ленивая операция, и она не использует наиболее производительный порядок итераций для (авто) векторизации. Тем не менее, мы просто добавили evaluation_strategy параметр для сокращения (и предстоящих накоплений), который позволяет выбирать между immediate а также lazy сокращения.
Немедленные сокращения выполняют сокращение немедленно (и не лениво) и могут использовать порядок итераций, оптимизированный для векторизованных сокращений.
Вы можете найти эту функцию в этом PR: https://github.com/QuantStack/xtensor/pull/550
В моих тестах это должно быть по крайней мере так же быстро или быстрее, чем просто.
Я надеюсь объединить это сегодня.
Btw. Пожалуйста, не стесняйтесь заходить на наш канал Gitter и размещать ссылку на вопрос, нам нужно лучше контролировать StackOverflow: https://gitter.im/QuantStack/Lobby
Другие решения
Других решений пока нет …