python — OpenCV: используйте findHomography () и warpPerspective, чтобы выровнять большее изображение по меньшему
Моя цель состоит в том, чтобы
- Нарисуйте отсканированное изображение так, чтобы его текст идеально помещался поверх текста исходного изображения. (вычитание изображений приведет к удалению текста)
- предотвратить потерю информации на изображении
Я использую функции SURF для подачи функции findHomography. Затем я использую функцию warpPerspective для преобразования отсканированного изображения. Полученное изображение почти идеально подходит к исходному изображению.
Однако отсканированное изображение имеет по углам содержимое, которое теряется после преобразования, поскольку текст на отсканированном изображении меньше и его необходимо увеличить.
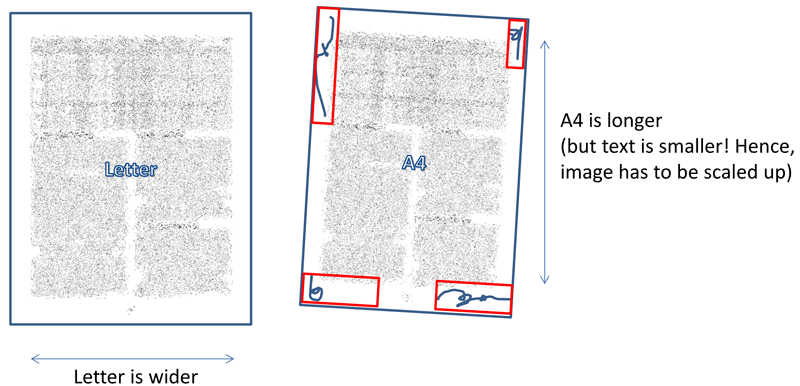
Вытеснение изображения с текстом немного меньшего размера

Информация на границах изображения обрезается
Чтобы избежать потери информации, я конвертирую изображение в RGBA и устанавливаю параметр borderValue в warpPerspective так, чтобы любой добавленный фон имел прозрачный цвет. Я удаляю прозрачные пиксели после преобразования снова. Эта процедура работает, но кажется крайне неэффективной.
- Вопрос: я ищу пример рабочего кода (C ++ или Python), который показывает, как сделать это более эффективно.

Изображение было перекошено, а содержимое сохранено. Однако текст двух картинок больше не накладывается друг на друга

Положение текста отключено, поскольку деформированное изображение имеет размер, отличный от ожидаемого деформации
После преобразования изображения проблема заключается в том, что два изображения больше не выравниваются, потому что размеры преобразованного изображения отличаются от ожидаемых методом warpPerspective.
- Вопрос: Как я могу выровнять два изображения? Было бы замечательно, если бы был способ сделать это уже в предыдущем шаге. Опять же, пример рабочего кода был бы очень полезен.
Вот код, который у меня есть до сих пор. Он выравнивает изображение, сохраняя его содержимое, однако текст больше не находится поверх исходного текста.
import math
import cv2
import numpy as npclass Deskewer:
def __init__(self, hessianTreshold = 5000):
self.__hessianThresh = hessianTreshold
self.imgOrigGray, self.imgSkewed, self.imgSkewedGray = None, None, None
def start(self, imgOrig, imgSkewed):
self.imgOrigGray = cv2.cvtColor(imgOrig, cv2.COLOR_BGR2GRAY)
self.imgSkewed = imgSkewed # final transformation will be performed on color image
self.imgSkewedGray = cv2.cvtColor(imgSkewed, cv2.COLOR_BGR2GRAY) # prior calculation is faster on gray
kp1, des1, kp2, des2 = self.__detectFeatures()
goodMatches = self.__flannMatch(des1, des2)
MIN_MATCH_COUNT = 10
M = None
if len(goodMatches) > MIN_MATCH_COUNT:
M, _ = self.__findHomography(kp1, kp2, goodMatches)
else:
print("Not enough matches are found - %d/%d" % (len(goodMatches), MIN_MATCH_COUNT))
return
return self.__deskew(M)def __detectFeatures(self):
surf = cv2.xfeatures2d.SURF_create(self.__hessianThresh)
kp1, des1 = surf.detectAndCompute(self.imgOrigGray, None)
kp2, des2 = surf.detectAndCompute(self.imgSkewedGray, None)
return kp1, des1, kp2, des2
def __flannMatch(self, des1, des2):
global matches
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
return good
def __findHomography(self, kp1, kp2, goodMatches):
src_pts = np.float32([kp1[m.queryIdx].pt for m in goodMatches
]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in goodMatches
]).reshape(-1, 1, 2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
i = matchesMask.index(1)
# TODO: This is a matching point before the warpPerspective call. How can I calculate this point AFTER the call?
print("POINTS: object(", src_pts[i][0][1], ",", src_pts[i][0][0], ") - scene(", dst_pts[i][0][1], ",", dst_pts[i][0][0], ")")
return M, mask
def getComponents(self, M):
# ((translationx, translationy), rotation, (scalex, scaley), shear)
a = M[0, 0]
b = M[0, 1]
c = M[0, 2]
d = M[1, 0]
e = M[1, 1]
f = M[1, 2]
p = math.sqrt(a * a + b * b)
r = (a * e - b * d) / (p)
q = (a * d + b * e) / (a * e - b * d)
translation = (c, f)
scale = (p, r) # p = x-Axis, r = y-Axis
shear = q
theta = math.atan2(b, a)
degrees = math.atan2(b, a) * 180 / math.pi
return (translation, theta, degrees, scale, shear)
def __deskew(self, M):
# this info might come in handy here for calculating the dsize of warpPerspective?
translation, theta, degrees, scale, shear = self.getComponents(M)
# Alpha channel allows me to set unique feature to pixels that are created during warpPerspective
imSkewedAlpha = cv2.cvtColor(self.imgSkewed, cv2.COLOR_BGR2BGRA)
# These sizes have been randomly choosen to make sure that all the contents fit in the new canvas
height = 5000
width = 5000
shift = -500
M2 = np.array([[1, 0, shift],
[0, 1, shift],
[0, 0, 1]])
M3 = np.dot(M, M2)
# TODO: How can I calculate the dsize argument?
# Newly created pixels are set to transparent
im_out = cv2.warpPerspective(imSkewedAlpha, M3,
(height, width), flags=cv2.WARP_INVERSE_MAP, borderMode=cv2.BORDER_CONSTANT, borderValue=(255, 0, 0, 0))
# http://codereview.stackexchange.com/a/132933
# Mask of non-black pixels (assuming image has a single channel).
mask = im_out[:, :, 3] == 255
# Coordinates of non-black pixels.
coords = np.argwhere(mask)
# Bounding box of non-black pixels.
x0, y0 = coords.min(axis=0)
x1, y1 = coords.max(axis=0) + 1 # slices are exclusive at the top
# Get the contents of the bounding box.
cropped = im_out[x0:x1, y0:y1]
# TODO: The warped image needs to align nicely on the original image
return cropped
origImg = cv2.imread("Letter.png")
skewedImg = cv2.imread("A4.png")
deskewed = Deskewer().start(origImg, skewedImg)
cv2.imshow("Original", origImg)
cv2.imshow("Deskewed", deskewed)
cv2.waitKey(0)


Исходное и перекошенное изображение (с дополнительным контентом) для тестирования
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …