Python — конвертировать ndarray, сохраненный в двоичный файл, созданный с помощью cPickle, в cv :: Mat в переполнении стека
у меня есть NumPy ndarray держа numpy.float64 данные хранятся в файле в двоичном формате с использованием cPickle-х dump() метод.
from cPickle import dump, HIGHEST_PROTOCOL
with open(filePath, 'wb') as f:
dump(numpyArray, f, protocol=HIGHEST_PROTOCOL)
На момент написания этой статьи HIGHEST_PROTOCOL использует cPickle’s версия протокола 2 но, похоже, не так много документации о том, как именно работает этот протокол.
Что я пытаюсь сделать, это прочитать этот файл и создать cv::Mat объект (посмотреть здесь) с данными, что оказывается довольно сложно сделать.
На данный момент, я надеюсь, что все заработает как можно быстрее, и я не слишком беспокоюсь о производительности, объеме памяти и эффективности. Однако эти факторы могут стать важными позже.
Таким образом, мой вопрос заключается в том, как проще всего преобразовать данные в этом файле в cv::Mat объект? Если вы думаете, что самый простой способ не обязательно самый эффективный, я бы тоже хотел услышать ваши мысли по этому поводу. Обратите внимание, что я открыт для использования другого формата хранения, возможно, просто текстового файла, если это облегчит взаимодействие между Python и C ++.
Я должен хранить numpy массив на диск, потому что мне нужно иметь возможность открывать и читать этот файл на мобильном устройстве (iOS и Android), и использование сетевого вызова для получения данных на самом деле не находится на столе в данный момент.
Решение
Pickle, вероятно, не удобный способ переноса данных на языки, отличные от Python.
На самом деле, я бы сказал, что Pickle совсем не подходит для хранения данных, так как:
- Нужен питон
- Он может не работать, если он был сохранен с использованием более поздней версии Python, чем та, которую вы используете
- Это небезопасно, если вы не доверяете источнику данных
Нельзя сказать, что он не имеет его использования: он удобен для таких вещей, как кэш, личные сценарии или передача данных между процессами.
Другие могут не согласиться с этим мнением.
Так что вы могли бы использовать? Вот несколько идей:
- Бинарный формат, используя
tofile, Это, вероятно, способ пойти на скорость и размер, и не очень сложно нагрузка. - Файл CSV, возможно сжатый (для 1D / 2D массивов). Ты можешь использовать
savetxt, - JSON, возможно сжатый, с
tolist()а такжеdumps, Это будет медленно и приведет к большим файлам, но будет переносимым и будет работать для любого измерения и даже для неравных длин строк / столбцов. - Если вы можете использовать панд, он поддерживает много форматов.
Еще немного просто для удовольствия:
- Сохраните двумерный массив маленьких целых чисел как изображение в градациях серого без потерь. Или с большим усилием используйте 3 цвета и альфа-канал для хранения плавающего массива одинарной точности.
- Использовать (Фортан) неформатированные данные (питон, С) который на самом деле довольно эффективно использует пространство, но страдает от многих проблем переносимости.
- Как b64 (b85 для дополнительных точек) закодированная строка. Вполне переносимо (b64 в любом случае), если вы знаете расположение матрицы, и, вероятно, меньше, чем обычный текст (например, csv).
РЕДАКТИРОВАТЬ: вот эталон для разных методов:
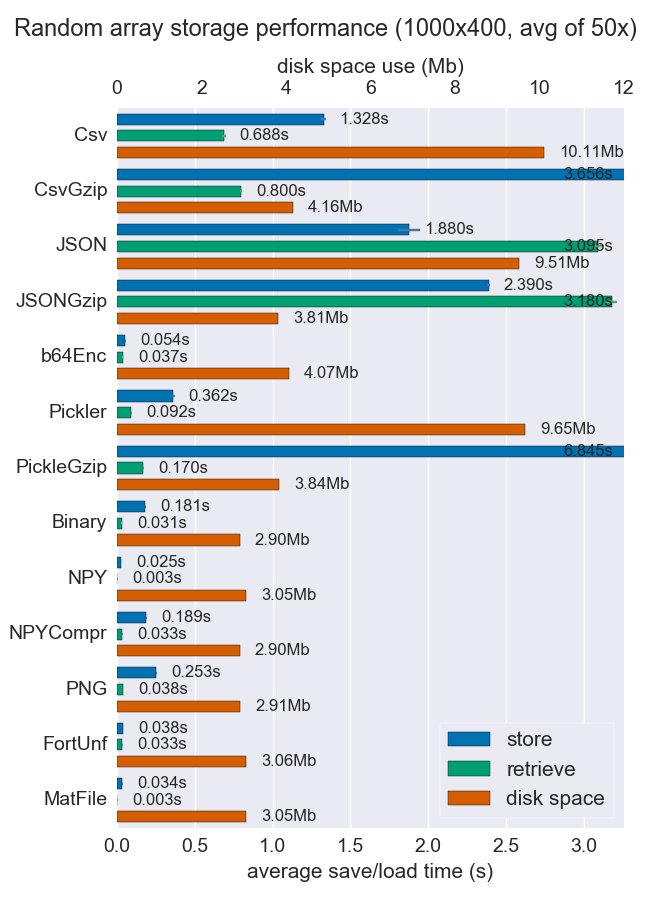
Другие решения