Простой метод получения / доступа предотвращает векторизацию — ошибка gcc?
Рассмотрим эту минимальную реализацию фиксированной vector<int>:
constexpr std::size_t capacity = 1000;
struct vec
{
int values[capacity];
std::size_t _size = 0;
std::size_t size() const noexcept
{
return _size;
}
void push(int x)
{
values[size()] = x;
++_size;
}
};
Учитывая следующий тестовый пример:
vec v;
for(std::size_t i{0}; i != capacity; ++i)
{
v.push(i);
}
asm volatile("" : : "g"(&v) : "memory");
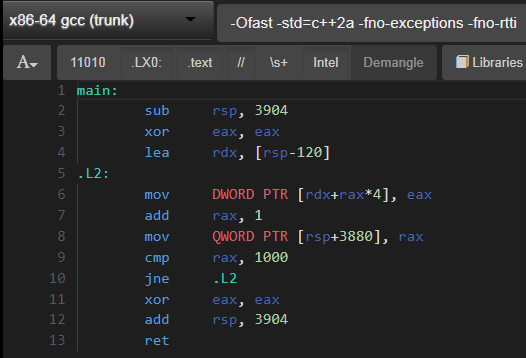
Компилятор производит не векторизованную сборку: живой пример на godbolt.org
Если я сделаю любой из следующих изменений …
-
values[size()]->values[_size] -
добавлять
__attribute__((always_inline))вsize()
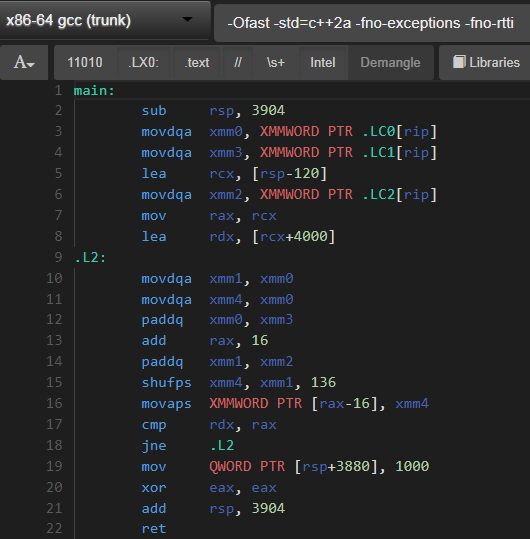
…затем компилятор создает векторизованную сборку: живой пример на godbolt.org
Это ошибка GCC? Или есть причина, почему простой метод доступа, такой как size() будет предотвращать автоматическую векторизацию, если always_inline явно добавлено?
Решение
Цикл в вашем примере векторизовано для GCC < 7,1, а также не векторизовано для GCC> = 7.1. Так что, похоже, здесь есть некоторые изменения в поведении.
Мы можем посмотреть на отчет по оптимизации компилятора добавляя -fopt-info-vec-all в командной строке:
Для GCC 7.3:
<source>:24:29: note: === vect_pattern_recog ===
<source>:24:29: note: === vect_analyze_data_ref_accesses ===
<source>:24:29: note: not vectorized: complicated access pattern.
<source>:24:29: note: bad data access.
<source>:21:5: note: vectorized 0 loops in function.
Для GCC 6.3:
<source>:24:29: note: === vect_pattern_recog ===
<source>:24:29: note: === vect_analyze_data_ref_accesses ===
<source>:24:29: note: === vect_mark_stmts_to_be_vectorized ===
[...]
<source>:24:29: note: LOOP VECTORIZED
<source>:21:5: note: vectorized 1 loops in function.
Таким образом, GCC 7.x решает не векторизовать цикл из-за сложной схемы доступа, которая может быть (в этой точке) не встроенной size() функция. Принудительное встраивание или выполнение вручную исправляет это. GCC 6.x, кажется, делает это сам по себе. Тем не менее, сборка выглядит size() в конечном итоге был встроен в обоих случаях, но, возможно, только после шага векторизации в GCC 7.x (это я догадываюсь).
Я задавался вопросом, почему вы положили asm volatile(...) строка в конце — возможно, чтобы компилятор не выбрасывал весь цикл, потому что он не имеет видимого эффекта в этом тестовом примере. Если мы просто вернуть последний элемент v вместо, мы можем достичь того же, не вызывая каких-либо возможных побочных эффектов на модель памяти для v,
return v.values[capacity - 1];
Теперь код векторизован с GCC 7.x, как это уже было с GCC 6.x:
<source>:24:29: note: === vect_pattern_recog ===
<source>:24:29: note: === vect_analyze_data_ref_accesses ===
<source>:24:29: note: === vect_mark_stmts_to_be_vectorized ===
[...]
<source>:24:29: note: LOOP VECTORIZED
<source>:21:5: note: vectorized 1 loops in function.
Так что же заключение Вот?
- что-то изменилось с GCC 7.1
- лучшее предположение: побочный эффект
asm volatileпортит встраиваниеsize()предотвращение векторизации
Является ли это ошибкой — может быть в 6.x или 7.x в зависимости от того, какое поведение желательно для asm volatile() конструкция — это вопрос для разработчиков GCC.
Также: попробуйте добавить -mavx2 или же -mavx512f -mavx512cd (или же -march=native и т.д.) в командную строку, в зависимости от вашего оборудования, чтобы получить векторизацию за пределами 128-бит xmmт.е. ymm а также zmm, регистрируется.
Другие решения
Я мог бы сузить проблему.
С двойной или одинарной точностью и флагами оптимизации -std = c ++ 11 -Ofast -march = native:
Clang с версией> = 5.0.0 создает инструкции перемещения AVX с регистрами zmm
Gcc с 4,9 <= Версия <= 6.3 создает инструкции перемещения AVX с регистрами zmm
Gcc с версией> = 7.1.0 создает инструкции перемещения AVX с регистрами xmm
Попробуйте это: https://godbolt.org/g/NXgF4g