Повышение точности прямой линии / сегментация корешков книг через OpenCV и переполнение стека
Я пытаюсь сделать сегментацию, основанную на корешках книги. У меня были проблемы в течение достаточно долгого времени. Два изображения ниже являются примером неудачной сегментации с использованием Hough Lines. Я пытаюсь провести черту между всеми книгами.
Я также попробовал HoughLineP, который на самом деле дает худшие результаты. Я попытался настроить все параметры как HoughLine, так и HoughLineP. Но я не могу улучшить скорость обнаружения. или даже ухудшить неправильное обнаружение.
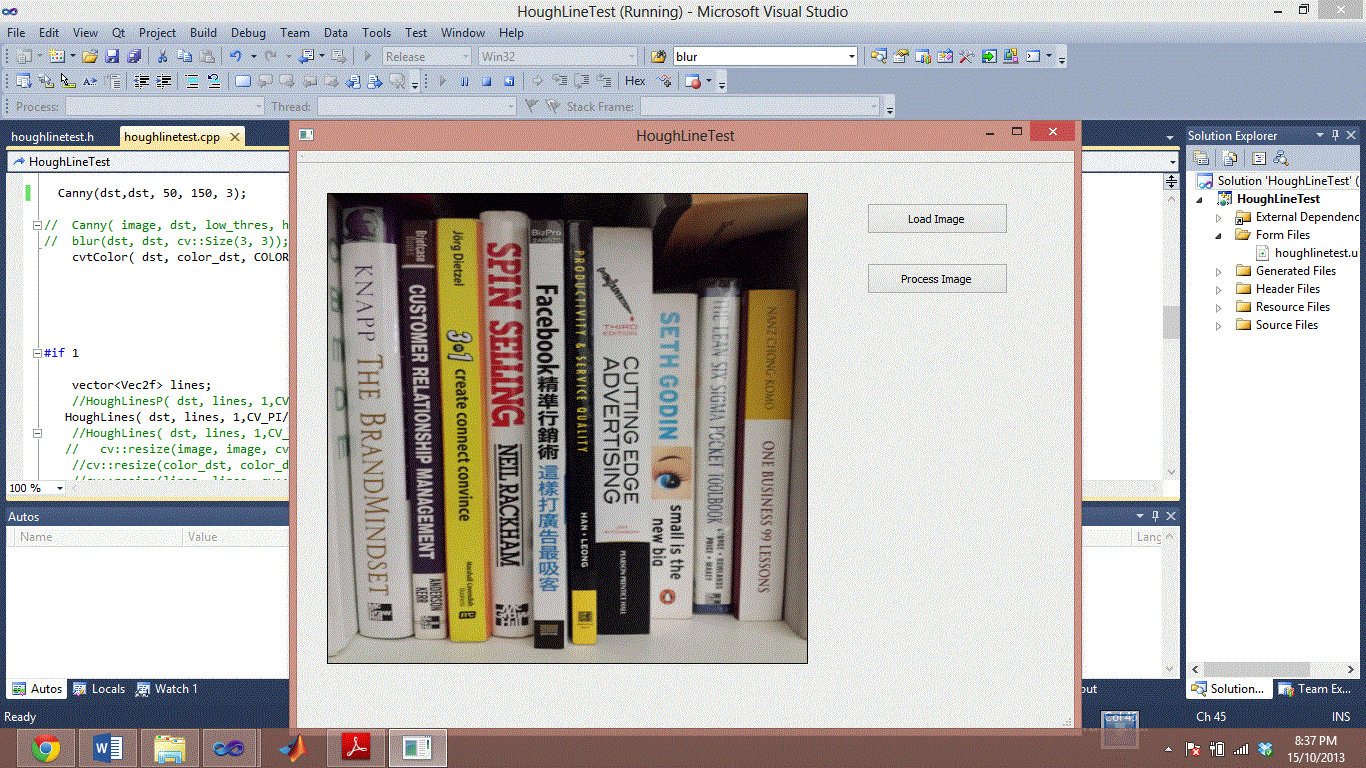
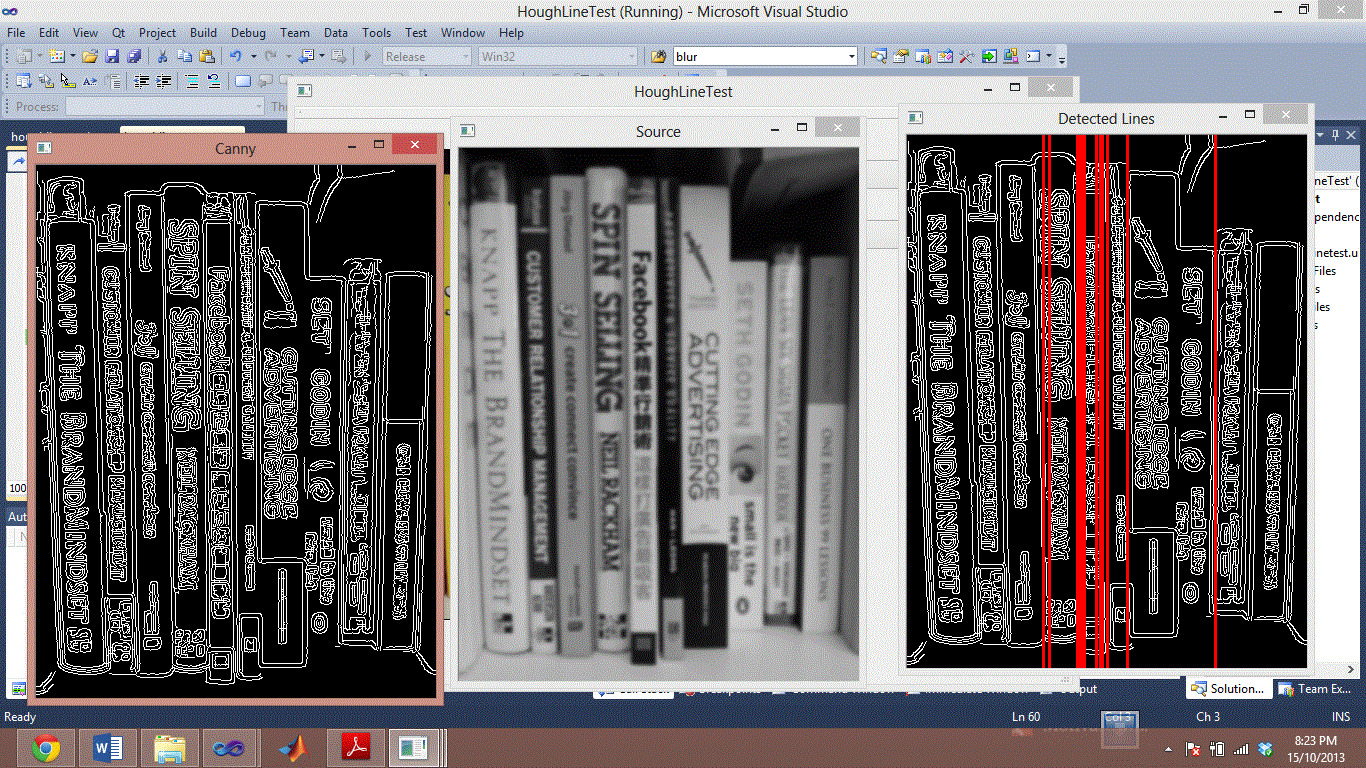
Я хотел бы спросить, есть ли у кого-нибудь какие-либо идеи, как сегментировать книгу шипами? Я пробовал методы предварительной обработки, но он объединяет корешки книг одного цвета, я думал о том, чтобы попытаться найти черные линии в середине книги, поскольку она обычно немного темнее, но если вы посмотрите на книгу Сета Година и передовой рекламы, я не вижу никакой пропасти между ними.
Обнаружение прямоугольника тоже не будет хорошо работать, учитывая, что некоторые корешки книг имеют 2 разных цвета, образуя собственный маленький прямоугольник, например, передовую рекламную книгу. Я также попытался найти контуры, которые также не дали хорошего результата.
Последняя программа, которую я ищу, — это подсчет количества книг. но для этого прежде всего мне нужна чистая и успешная сегментация.
У кого-нибудь есть другие методы, которые я могу попробовать? Буду очень признателен за все отзывы, комментарии и ответы. Я застрял в этом уже больше месяца. Благодарю.
Решение
Если вы можете предположить, что ваши позвоночники всегда будут выровнены по вертикали на изображении, имеет смысл использовать фильтр обнаружения краев, который обнаруживает только вертикальные линии. Это уменьшит шум от деталей на самих позвоночниках (названия и т. Д.) И даст преобразованию Хафа больше шансов на успех.
Можно использовать такой сверточный фильтр:
-1 0 1
-1 0 1
-1 0 1
Другие решения
Я лучше прокомментирую, чем отвечу, но …
Убедитесь, что вынули край, найденный после обнаружения каждого, и повторите обнаружение края.
Также вы можете осмотреть пики на предмет их относительной силы и повторять только тогда, когда их сложнее выбрать.
В последнее время я делаю обнаружение краев нелинейным способом, находя градиент во всех восьми направлениях и принимая максимальное из них в качестве вывода для каждого пикселя. Затем повторяя для каждого цвета, когда его цветная картинка. Это легко в Matlab, но я не знаком с Visual Studio.
Повеселись!