После записи в двоичный файл и открытия его с помощью различных программ, почему результаты не так, как ожидалось?
В основном я пытаюсь записать в двоичный файл, чтобы при его открытии в текстовом редакторе отображались все символы ASCII. Я заметил, что это работает с блокнотом, но не работает с блокнотом ++ или открытым офисом и дает странные результаты. Зачем?
#include <fstream>
using namespace std;
int main () {
ofstream file ("file.bin", ios::binary);
for(int num = 0; num < 128; num++)
file.write (reinterpret_cast<const char *>(&num), sizeof(num));
file.close ();
return 0;
}
Поэтому я ожидаю, что файл при открытии в текстовом редакторе будет примерно воспроизводить этот график ASCII. Когда я открываю его с помощью блокнота, я получаю это
! " # $ % & ' ( ) * + , - . / 01 2 3 4 5 6 7 8 9:; < =>? @ A B
C D E F G H I J K L M N O P Q R S T
U V W X Y Z [\] ^ _ `a b c d e f
g h i j k l m n o p q r s t u v w x
y z {| } ~
Когда я открываю его с помощью блокнота ++, я получаю это
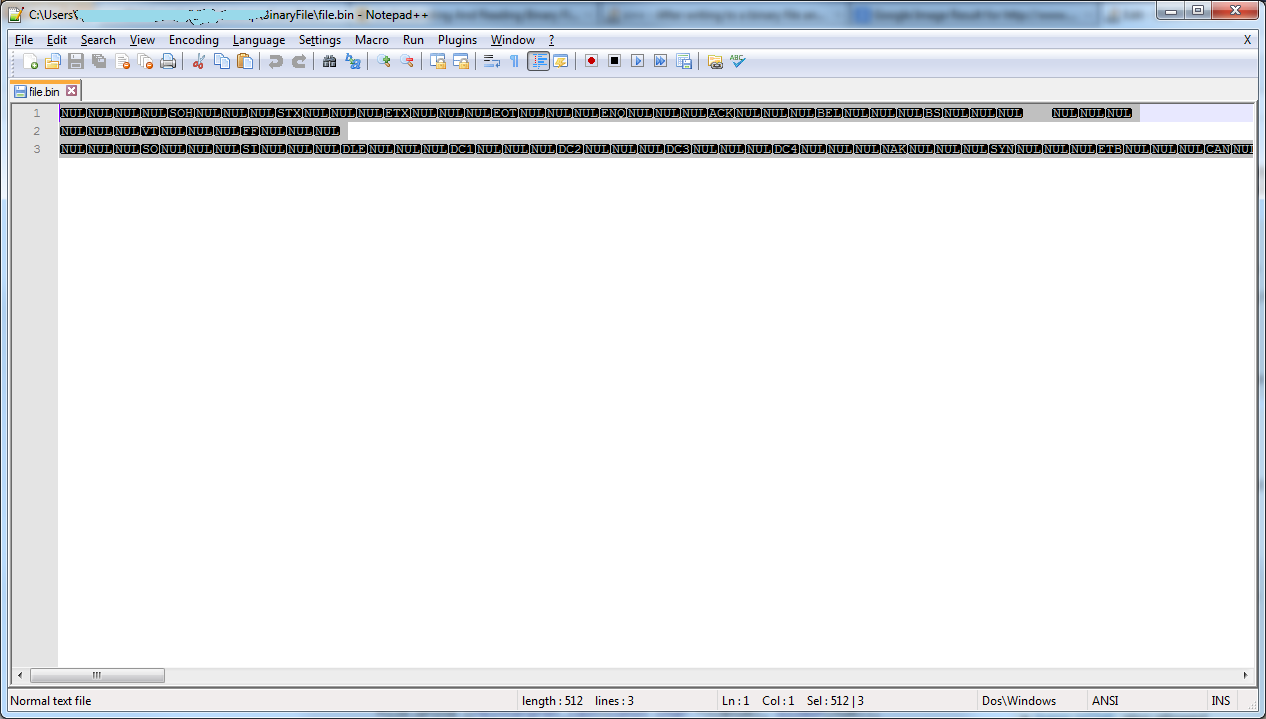
Когда я открываю его с помощью OpenOffice.org Writer, я выбираю вариант по умолчанию, который открывается с помощью «Western Europe (Windows 1252 / WinLatin 1)», и получаю кучу ###, Это имеет отношение к байтовому порядку-маркеру?
Я пытался изменить программу для использования file.write (reinterpret_cast<const char *>(&num), sizeof(char)); так как int в настоящее время тип приведен к char но тогда программа вылетает.
Из любопытства кто-нибудь получил объяснение, почему автор OpenOffice придумывает # а пробелы?
Решение
for(int num = 0; num < 128; num++)
file.write (reinterpret_cast<const char *>(&num), sizeof(num));
В этих строках вы пишете число num в двоичном виде, как 4-байтовое целое число. (sizeof(num), где num является int). Поскольку все значения, которые вы пишете, меньше 128, первые три байта num всегда 0x000000, Таким образом, для каждого значения, которое вы пишете, вы получаете три нуля, а затем символ ASCII, который вы намеревались.
Microsoft Notepad абсолютно глупый, и когда он достигает символа ASCII, который нельзя распечатать, например, NULL, он просто отображает пробел. Обратите внимание, что ваши значения ASCII имеют «пробелы» между ними. Кроме того, держу пари, что это выглядит примерно так, где я заменил некоторые пробелы подчеркиванием. Обратите внимание, что 10-е значение (новая строка) вызывает новую строку.
_________
__ ! " # $ % & ' ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ _ ` a b c d e f g h i j k l m n o p q r s t u v w x y z { | } ~
Notepad ++ намного умнее, и вместо преобразования всех странных вещей в пробелы показывает их имя или номер. Notepad ++ также, похоже, запутался из-за символа 13 (возврат каретки), поскольку 13 также обычно является частью новой строки. Он (разумно) решил сделать эту новую линию также. Notepad ++ обрабатывает этот файл, возможно, более правильно. Это можно проверить, посмотрев на первые восемь символов:NUL NUL NUL NUL - SOH NUL NUL NUL«Сначала ноль, затем символ« SOH ». Если мы посмотрим на вашу диаграмму ASCII, то там будет сказано, что первым символом ASCII является« SOH — начало курса ».
Другие решения
Других решений пока нет …