Поддерживают ли нынешние архитектуры x86 невременные нагрузки (из «обычной» памяти)?
Мне известно о множестве вопросов по этой теме, однако я не видел ни четких ответов, ни каких-либо контрольных измерений. Таким образом, я создал простую программу, которая работает с двумя массивами целых чисел. Первый массив a очень большой (64 МБ) и второй массив b мал, чтобы поместиться в кэш L1. Программа перебирает a и добавляет свои элементы к соответствующим элементам b в модульном смысле (когда конец b программа запускается с начала снова). Измеренное количество пропусков кэша L1 для разных размеров b как следует:

Измерения проводились на процессоре типа Xeon E5 2680v3 Haswell с кэшем данных L1 32 КБ. Поэтому во всех случаях b встроен в кэш L1. Тем не менее, количество промахов значительно выросло примерно на 16 КБ b след памяти. Этого можно ожидать, так как нагрузки обоих a а также b вызывает аннулирование строк кэша с начала b с этой точки зрения.
Нет абсолютно никаких причин сохранять элементы a в кеше они используются только один раз. Поэтому я запускаю вариант программы с временными нагрузками a данные, но количество промахов не изменилось. Я также запускаю вариант с невременной предварительной загрузкой a данные, но все же с теми же результатами.
Мой контрольный код выглядит следующим образом (показан вариант без временной выборки):
int main(int argc, char* argv[])
{
uint64_t* a;
const uint64_t a_bytes = 64 * 1024 * 1024;
const uint64_t a_count = a_bytes / sizeof(uint64_t);
posix_memalign((void**)(&a), 64, a_bytes);
uint64_t* b;
const uint64_t b_bytes = atol(argv[1]) * 1024;
const uint64_t b_count = b_bytes / sizeof(uint64_t);
posix_memalign((void**)(&b), 64, b_bytes);
__m256i ones = _mm256_set1_epi64x(1UL);
for (long i = 0; i < a_count; i += 4)
_mm256_stream_si256((__m256i*)(a + i), ones);
// load b into L1 cache
for (long i = 0; i < b_count; i++)
b[i] = 0;
int papi_events[1] = { PAPI_L1_DCM };
long long papi_values[1];
PAPI_start_counters(papi_events, 1);
uint64_t* a_ptr = a;
const uint64_t* a_ptr_end = a + a_count;
uint64_t* b_ptr = b;
const uint64_t* b_ptr_end = b + b_count;
while (a_ptr < a_ptr_end) {
#ifndef NTLOAD
__m256i aa = _mm256_load_si256((__m256i*)a_ptr);
#else
__m256i aa = _mm256_stream_load_si256((__m256i*)a_ptr);
#endif
__m256i bb = _mm256_load_si256((__m256i*)b_ptr);
bb = _mm256_add_epi64(aa, bb);
_mm256_store_si256((__m256i*)b_ptr, bb);
a_ptr += 4;
b_ptr += 4;
if (b_ptr >= b_ptr_end)
b_ptr = b;
}
PAPI_stop_counters(papi_values, 1);
std::cout << "L1 cache misses: " << papi_values[0] << std::endl;
free(a);
free(b);
}
Что меня интересует, так это то, поддерживают ли производители процессоров поддержку или не поддерживают временную загрузку / предварительную выборку, или каким-либо другим способом пометить некоторые данные как не удерживаемые в кеше (например, пометить их как LRU). Существуют ситуации, например, в HPC, где подобные сценарии распространены на практике. Например, в разреженных итерационных линейных решателях / собственных решениях матричные данные обычно очень велики (больше, чем объемы кэша), но векторы иногда достаточно малы, чтобы поместиться в кэш L3 или даже L2. Затем мы хотели бы сохранить их там любой ценой. К сожалению, загрузка матричных данных может привести к аннулированию особенно строк x-векторного кэша, хотя в каждой итерации решателя матричные элементы используются только один раз, и нет никакой причины сохранять их в кэше после их обработки.
ОБНОВИТЬ
Я только что провел аналогичный эксперимент на Intel Xeon Phi KNC, пока измерял время выполнения вместо пропусков L1 (я не нашел способа, как надежно их измерять; PAPI и VTune дали странные метрики.) Результаты здесь:
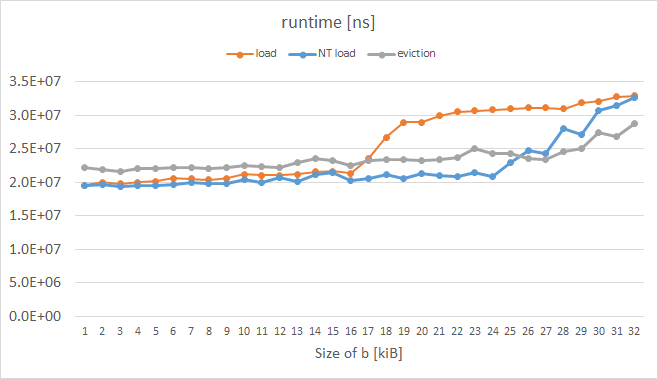
Оранжевая кривая представляет обычные нагрузки и имеет ожидаемую форму. Синяя кривая представляет нагрузки с так называемой подсказкой о выселении (EH), установленной в префиксе инструкции, а серая кривая представляет случай, когда каждая строка кэша a был вручную выселен; оба эти трюка, включенные KNC, очевидно, работали так, как мы хотели для b более 16 КБ. Код измеряемой петли следующий:
while (a_ptr < a_ptr_end) {
#ifdef NTLOAD
__m512i aa = _mm512_extload_epi64((__m512i*)a_ptr,
_MM_UPCONV_EPI64_NONE, _MM_BROADCAST64_NONE, _MM_HINT_NT);
#else
__m512i aa = _mm512_load_epi64((__m512i*)a_ptr);
#endif
__m512i bb = _mm512_load_epi64((__m512i*)b_ptr);
bb = _mm512_or_epi64(aa, bb);
_mm512_store_epi64((__m512i*)b_ptr, bb);
#ifdef EVICT
_mm_clevict(a_ptr, _MM_HINT_T0);
#endif
a_ptr += 8;
b_ptr += 8;
if (b_ptr >= b_ptr_end)
b_ptr = b;
}
ОБНОВЛЕНИЕ 2
На Xeon Phi, icpc генерируется для варианта с нормальной нагрузкой (оранжевая кривая) для предварительной выборки для a_ptr:
400e93: 62 d1 78 08 18 4c 24 vprefetch0 [r12+0x80]
Когда я вручную (путем шестнадцатеричного редактирования исполняемого файла) изменил это так:
400e93: 62 d1 78 08 18 44 24 vprefetchnta [r12+0x80]
Я получил желаемые результаты, даже лучше, чем сине-серые кривые. Тем не менее, я не смог заставить компилятор генерировать невременные prefetchnig для меня, даже используя #pragma prefetch a_ptr:_MM_HINT_NTA до цикла 🙁
Решение
Чтобы конкретно ответить на главный вопрос:
да, недавний1 основные процессоры Intel поддерживают невременные нагрузки на нормальный 2 памяти — но только «косвенно» с помощью инструкций невременной предварительной выборки, а не напрямую с помощью инструкций невременной загрузки, таких как movntdqa, Это в отличие от невременных хранилищ, где вы можете просто использовать соответствующие невременные инструкции хранилища3 непосредственно.
Основная идея заключается в том, что вы выпускаете prefetchnta в строку кэша перед любой нормальной загрузкой, а затем выдайте загрузку в обычном режиме. Если строка не была уже в кеше, она будет загружена невременным способом. Точное значение невременная мода зависит от архитектуры, но общая схема такова, что строка загружается как минимум в L1 и, возможно, в некоторые более высокие уровни кэша. Действительно, для того, чтобы предварительная выборка была полезной, она должна вызывать загрузку строки, по крайней мере, в немного уровень кэша для потребления при более поздней загрузке. Строка также может обрабатываться специально в кеше, например, отмечая ее как высокий приоритет для выселения или ограничивая способы ее размещения.
Результатом всего этого является то, что в то время как невременные нагрузки поддержанный в некотором смысле, они действительно только частично не временные, в отличие от магазинов, где вы действительно не оставляете следов ни на одном из уровней кэша. Временные нагрузки будут вызывать немного загрязнение кеша, но, как правило, меньше, чем обычные нагрузки. Точные детали зависят от архитектуры, и я включил некоторые детали ниже для современного Intel (вы можете найти чуть более длинную рецензию в этом ответе).
Skylake Client
На основании тестов в этом ответе кажется, что поведение для prefetchnta Skylake должен нормально загружать в кэш L1, полностью пропускать L2 и ограниченным образом загружать в кэш L3 (возможно, только одним или двумя способами, так что общее количество L3 доступно для nta предварительные выборки ограничены).
Это было проверено на Клиент Skylake, но я полагаю, что это основное поведение, вероятно, распространяется в обратном направлении, вероятно, на Sandy Bridge и более ранние (на основе формулировок в руководстве по оптимизации Intel), а также на Kaby Lake и более поздние архитектуры на основе клиента Skylake. Таким образом, если вы не используете компоненты Skylake-SP или Skylake-X, или очень старый процессор, это, вероятно, поведение, которое вы можете ожидать от prefetchnta,
Skylake Server
Единственный недавно выпущенный чип Intel имеет другое поведение: Skylake сервер (используется в Skylake-X, Skylake-SP и некоторых других линиях). Это значительно изменило архитектуру L2 и L3, и L3 больше не включает гораздо больший L2. Для этого чипа кажется, что prefetchnta скачет и то и другое кэши L2 и L3, поэтому в этой архитектуре загрязнение кэша ограничено L1.
Такое поведение было сообщил пользователь Mysticial в комментарии. Недостатком, как указано в этих комментариях, является то, что это делает prefetchnta гораздо более хрупкие: если вы неправильно определили расстояние или время предварительной выборки (особенно легко, когда задействована гиперпоточность и активен одноуровневый элемент), и данные извлекаются из L1 перед использованием, вы скорее вернетесь обратно в основную память чем L3 на более ранних архитектурах.
1 последний здесь, вероятно, что-то значит в последнее десятилетие или около того, но я не имею в виду, что более раннее оборудование не поддерживало невременную предварительную выборку: возможно, что поддержка восходит к введению prefetchnta но у меня нет оборудования, чтобы проверить это, и я не могу найти существующий надежный источник информации о нем.
2 Нормальный здесь просто означает WB (обратную запись) память, которая в подавляющем большинстве случаев имеет дело с памятью на уровне приложения.
3 В частности, инструкции по хранению NT movnti для регистров общего назначения и movntd* а также movntp* семьи для SIMD регистров.
Другие решения
Я отвечаю на свой собственный вопрос, поскольку нашел следующий пост на форуме разработчиков Intel, который имеет для меня смысл. Это было написано Джоном Маккальпином:
Результаты для основных процессоров не удивительны — при отсутствии настоящей памяти «блокнота» неясно, можно ли реализовать реализацию «невременного» поведения, которая не вызывает неприятных сюрпризов. Два подхода, которые использовались в прошлом, это (1) загрузка строки кэша, но пометка ее как LRU вместо MRU, и (2) загрузка строки кэша в один конкретный «набор» ассоциативно-множественного кэша. В любом случае относительно легко генерировать ситуации, в которых кеш отбрасывает данные до того, как процессор завершит их чтение.
Оба этих подхода рискуют ухудшить производительность в случаях, работающих с более чем небольшим количеством массивов, и их значительно труднее реализовать без «ловушек», если учитывать HyperThreading.
В других контекстах я приводил доводы в пользу реализации инструкций «загрузить несколько», которые гарантировали бы, что все содержимое строки кэша будет копироваться в регистры атомарно. Я рассуждаю так: аппаратное обеспечение абсолютно гарантирует, что строка кэша перемещается атомарно и что время, необходимое для копирования оставшейся части строки кэша в регистры, было настолько маленьким (дополнительные 1-3 цикла, в зависимости от поколения процессора), что оно могло быть безопасно реализованным как атомарная операция.
Начиная с Haswell, ядро может читать 64 байта за один цикл (2 256-битных выравниваемых чтения AVX), поэтому воздействие непреднамеренных побочных эффектов становится еще ниже.
Начиная с KNL, загрузка полной строки кэша (выровненная) должна быть «естественно» атомарной, поскольку передачи из кэша данных L1 в ядро являются полными строками кэша, и все данные помещаются в целевой регистр AVX-512. (Это не означает, что Intel гарантирует атомарность в реализации! У нас нет четкого представления об ужасных угловых случаях, которые должны учитывать дизайнеры, но разумно сделать вывод, что большую часть времени выровненные 512-битные нагрузки будут происходить атомарно.) При этом «естественном» 64-байтовом атомарности некоторые приемы, использовавшиеся в прошлом для уменьшения загрязнения кэша из-за «невременных» нагрузок, могут заслуживать другого взгляда ….
Инструкция MOVNTDQA предназначена главным образом для чтения из диапазонов адресов, которые сопоставлены как «Комбинирование записи» (WC), а не для чтения из обычной системной памяти, которая сопоставлена «Обратная запись» (WB). В описании тома 2 SWDM говорится, что реализация «может» делать что-то особенное с MOVNTDQA для регионов WB, но упор делается на поведение для типа памяти WC.
Тип памяти «Write-Combining» почти никогда не используется для «реальной» памяти — он используется почти исключительно для областей ввода-вывода с отображением в памяти.
Смотрите здесь весь пост: https://software.intel.com/en-us/forums/intel-isa-extensions/topic/597075