Почему транспонирование сетки CUDA (но не ее потоковых блоков) все еще замедляет вычисления?
РЕДАКТИРОВАТЬ: Кажется, что, по крайней мере, в этом случае, транспонирование сетки негативно влияет на пропускную способность кэша L2. Это было получено от визуального профилировщика. Причина, по которой мне пока не ясно.
Я пришел к вычислительной ситуации на GPU, в которой требуется транспонировать сетку CUDA. Так что если block_ {х, у} изначально действовал на область данных D_ {х, у}, теперь он действует на область данных D_ {у, х}, следовательно block_ {у, х} будет действовать на область данных D_ {х, у}. Пример представлен на следующем рисунке.
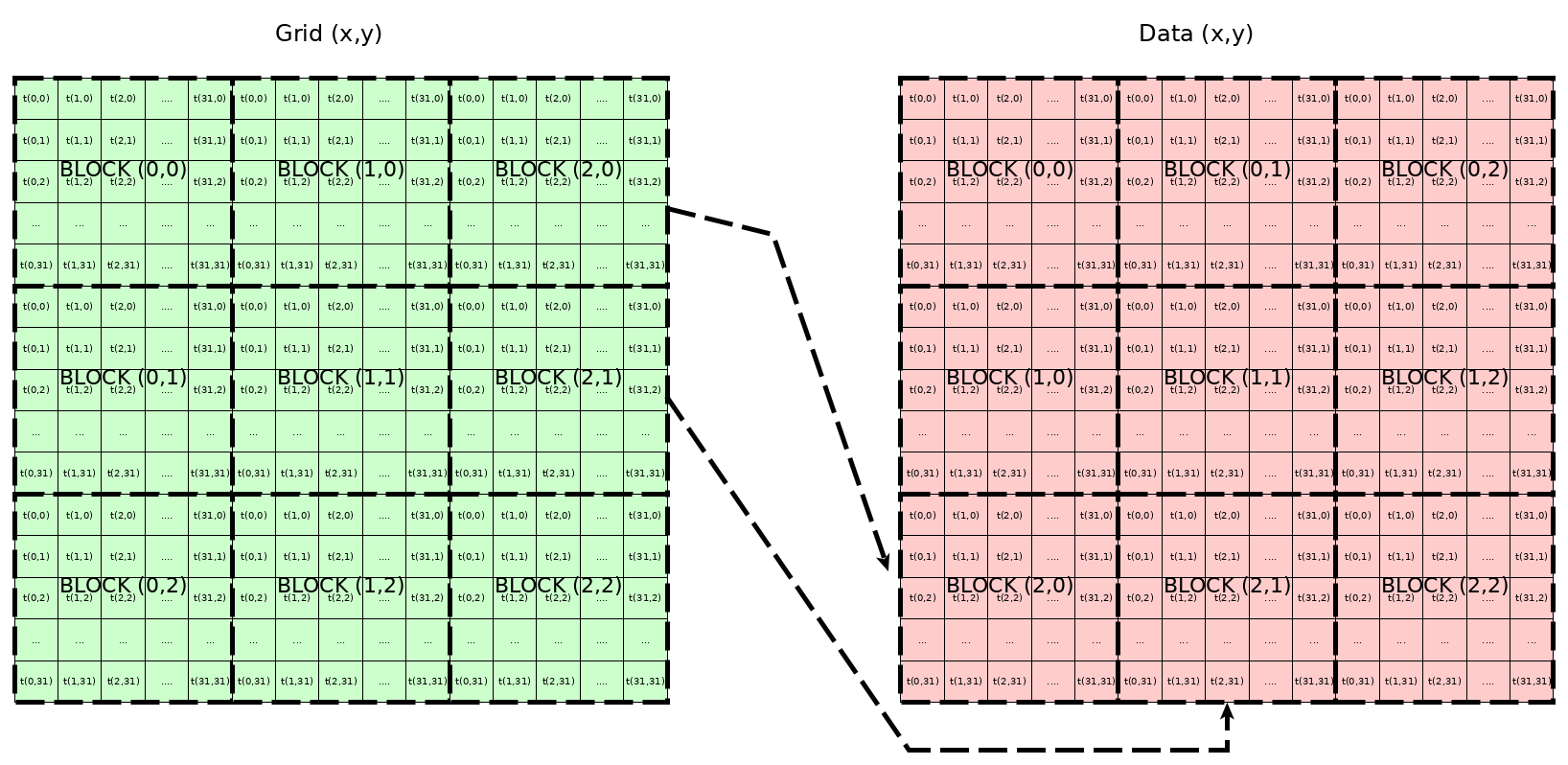
Стоит отметить, что потоки не перемещаются внутри каждого блока, то есть, когда блок расположен, threadIdx.x а также threadIdx.y значения используются обычным образом для их смещений x и y соответственно.
Из того, что я знаю, в теории этот дизайн не должен наносить ущерба производительности, так как шаблон объединения памяти все еще сохраняется, то есть потоки внутри блока не транспонируются, это просто сетка, которая переупорядочивает свои блоки. Однако я обнаружил, что при транспонировании сетки ядро работает ок. В 2 раза медленнее, чем в обычном случае. Я сделал игрушечный пример, чтобы проиллюстрировать ситуацию.
➜ transpose-grid ./prog 10000 10000 100 0
init data.....................done: zero matrix of 10000 x 10000
copy data to GPU..............done
preparing grid................done: block(32, 32, 1), grid(313, 313, 1)
normal_kernel (100 rep).......done: 0.935132 ms
verifying correctness.........ok
➜ transpose-grid ./prog 10000 10000 100 1
init data.....................done: zero matrix of 10000 x 10000
copy data to GPU..............done
preparing grid................done: block(32, 32, 1), grid(313, 313, 1)
transp_kernel (100 rep).......done: 1.980445 ms
verifying correctness.........ok
Я был бы очень признателен за любое объяснение этого вопроса. Вот исходный код для воспроизведения поведения.
// -----------------------------------
// can compile as nvcc main.cu -o prog
// -----------------------------------
#include <cuda.h>
#include <cstdio>
#define BSIZE2D 32
__global__ void normal_kernel(int *dmat, const int m, const int n){
const int i = blockIdx.y*blockDim.y + threadIdx.y;
const int j = blockIdx.x*blockDim.x + threadIdx.x;
if(i < m && j < n){
dmat[i*n + j] = 1;
}
}
__global__ void transp_kernel(int *dmat, const int m, const int n){
const int i = blockIdx.x*blockDim.x + threadIdx.y;
const int j = blockIdx.y*blockDim.y + threadIdx.x;
if(i < m && j < n){
dmat[i*n + j] = 1;
}
}int verify(int *hmat, const int m, const int n){
printf("verifying correctness........."); fflush(stdout);
for(int i=0; i<m*n; ++i){
if(hmat[i] != 1){
fprintf(stderr, "Incorrect value at m[%i,%i] = %i\n", i/n, i%n);
return 0;
}
}
printf("ok\n"); fflush(stdout);
return 1;
}
int main(int argc, char **argv){
if(argc != 5){
printf("\nrun as ./prog m n r t\n\nr = number of repeats\nt = transpose (1 or 0)\n");
exit(EXIT_FAILURE);
}
const int m = atoi(argv[1]);
const int n = atoi(argv[2]);
const int r = atoi(argv[3]);
const int t = atoi(argv[4]);
const unsigned int size = m*n;
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
float time;
int *hmat, *dmat;printf("init data....................."); fflush(stdout);
hmat = (int*)malloc(sizeof(int)*(size));
for(int i=0; i<size; ++i){
hmat[i] = 0;
}
printf("done: zero matrix of %i rows x %i cols\n", m, n);printf("copy data to GPU.............."); fflush(stdout);
cudaMalloc(&dmat, sizeof(int)*(size));
cudaMemcpy(dmat, hmat, sizeof(int)*(size), cudaMemcpyHostToDevice);
printf("done\n");printf("preparing grid................"); fflush(stdout);
dim3 block(BSIZE2D, BSIZE2D, 1);
dim3 grid;
// if transpose or not
if(t){
grid = dim3((m + BSIZE2D - 1)/BSIZE2D, (n + BSIZE2D - 1)/BSIZE2D, 1);
}
else{
grid = dim3((n + BSIZE2D - 1)/BSIZE2D, (m + BSIZE2D - 1)/BSIZE2D, 1);
}
printf("done: block(%i, %i, %i), grid(%i, %i, %i)\n", block.x, block.y, block.z, grid.x, grid.y, grid.z);if(t){
printf("transp_kernel (%3i rep).......", r); fflush(stdout);
cudaEventRecord(start, 0);
for(int i=0; i<r; ++i){
transp_kernel<<<grid, block>>>(dmat, m, n);
cudaDeviceSynchronize();
}
cudaEventRecord(stop,0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time, start, stop); // that's our time!
printf("done: %f ms\n", time/(float)r);
}
else{
printf("normal_kernel (%3i rep).......", r); fflush(stdout);
cudaEventRecord(start, 0);
for(int i=0; i<r; ++i){
normal_kernel<<<grid, block>>>(dmat, m, n);
cudaDeviceSynchronize();
}
cudaEventRecord(stop,0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time, start, stop); // that's our time!
printf("done: %f ms\n", time/(float)r);
}cudaMemcpy(hmat, dmat, sizeof(int)*size, cudaMemcpyDeviceToHost);
verify(hmat, m, n);
exit(EXIT_SUCCESS);
}
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …