Почему std :: nth_element возвращает отсортированные векторы для входных векторов с N & lt; 33 элемента?
я использую std::nth_element чтобы получить (примерно правильное) значение для процентиля вектора, вот так:
double percentile(std::vector<double> &vectorIn, double percent)
{
std::nth_element(vectorIn.begin(), vectorIn.begin() + (percent*vectorIn.size())/100, vectorIn.end());
return vectorIn[(percent*vectorIn.size())/100];
}
Я заметил, что для векторов длиной до 32 элементов вектор полностью сортируется. Начиная с 33 элементов, он никогда не сортируется (как и ожидалось).
Не уверен, имеет ли это значение, но функция находится в «(Matlab-) mex c ++ code», который скомпилирован через Matlab с использованием «Microsoft Windows SDK 7.1 (C ++)».
РЕДАКТИРОВАТЬ:
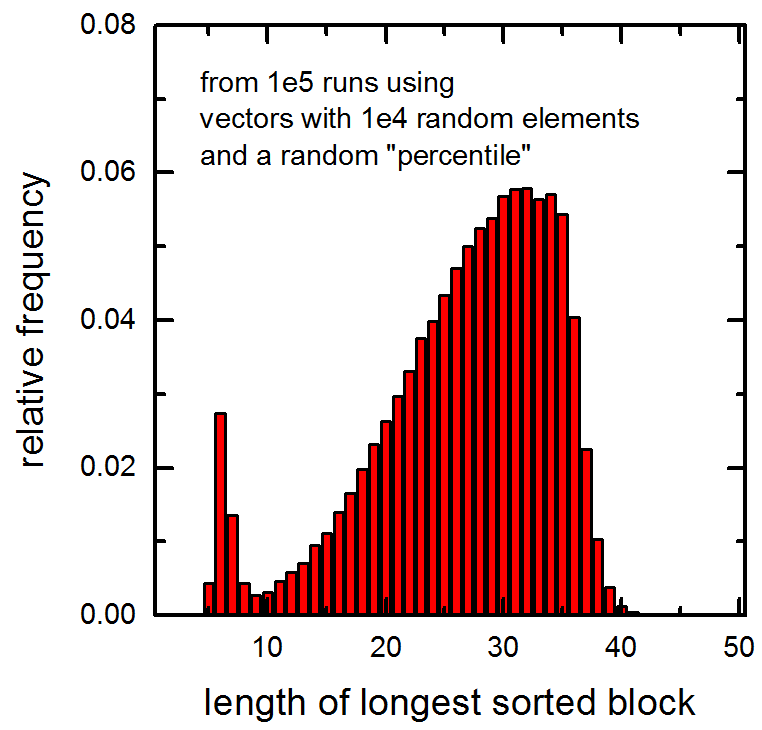
Также см. Следующую гистограмму длин самых отсортированных блоков в 1e5 векторах, переданных в функцию (векторы содержали 1e4 случайных элемента и был вычислен случайный процентиль). Обратите внимание на пик при очень малых значениях.
Решение
Это будет варьироваться от реализации стандартной библиотеки к реализации стандартной библиотеки (и может отличаться в зависимости от других факторов), но в общих чертах:
-
std :: nth_element разрешается переставлять входной контейнер так, как он считает нужным, при условии, что nth_element находится в позиции n, а контейнер разделен в позиции n.
-
Для небольших контейнеров, как правило, быстрее выполнить полную сортировку вставок, чем быстрый выбор, даже если это не масштабируется.
Так как авторы стандартной библиотеки обычно выбирают самое быстрое решение, большинство реализаций nth_element (и, в этом отношении, реализации сортировки) используют настраиваемые алгоритмы для небольших входных данных (или для небольших сегментов в нижней части рекурсии), что может сортировать контейнер более агрессивно, чем кажется необходимым. Для векторов скалярных значений сортировка вставки выполняется чрезвычайно быстро, поскольку она использует все преимущества кэша. Благодаря потоковым расширениям можно ускорить его, выполнив параллельные сравнения.
Кстати, вы можете сэкономить небольшое количество вычислений, только вычисляя пороговый итератор один раз, который может быть более читабельным:
double percentile(std::vector<double> &vectorIn, double percent)
{
auto nth = vectorIn.begin() + (percent*vectorIn.size())/100;
std::nth_element(vectorIn.begin(), nth, vectorIn.end());
return *nth;
}
Другие решения