Почему резко доступ к статической памяти через кеш с ++?
Фон
Я изучал возможность использования MPC5200 статическое пространство оперативной памяти как блокнот памяти. У нас есть 16 КБ неиспользуемой памяти, которая появляется на процессорной шине (источник).
Теперь некоторые важные замечания по реализации:
-
Эта память используется BestComm DMA контроллер, под
RTEMSэто по существу настроит таблицу задач в начале SRAM с набором из 16 задач, которые могут работать как буферы для периферийного интерфейса, I2C, Ethernet и т. д. Чтобы использовать это пространство без конфликтов и зная, что наша система использует только около 2 КБ буферов драйвера Ethernet, я сместил начало SRAM на 8 КБ, так что теперь у нас есть 8 КБ памяти, которая, как мы знаем, не будет использоваться системой. -
RTEMSопределяет массив, который указывает на статическую память следующим образом:
(источник)
typedef struct {
...
...
volatile uint8_t sram[0x4000];
} mpc5200_t;
extern volatile mpc5200_t mpc5200;
И я знаю, что массив sram указывает на статическую память, потому что, когда я редактирую первый раздел и распечатываю блок памяти (MBAR + 0x8000 источник)
Отсюда я могу сказать следующее, у меня есть RTEMS определенный доступ к SRAM с помощью mpc5200.sram[0 -> 0x2000], Это означает, что я могу начать тестирование на скорость, с которой я могу справиться.
Тестовое задание
Чтобы оценить скорость, я настроил следующий тест:
int a; // Global that is separate from the test.
**TEST**
// Set up the data.
const unsigned int listSize = 0x1000;
uint8_t data1[listSize];
for (int k = 0; k < listSize; ++k) {
data1[k] = k;
mpc5200.sram[k] = k;
}
// Test 1, data on regular stack.
clock_t start = clock();
for (int x = 0; x < 5000; ++x) {
for (int y = 0; y < 0x2000; ++y) {
a = (data1[y]);
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
printf("elapsed dynamic: %f\n" ,elapsedTime);
// Test 2, get data from the static memory.
start = clock();
for (int x = 0; x < 5000; ++x) {
for (int y = 0; y < 0x2000; ++y) {
a = (mpc5200.sram[y]);
}
}
elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
printf("elapsed static: %f\n" ,elapsedTime);
Довольно просто, концепция заключается в том, что мы перебираем доступное пространство и устанавливаем глобальное. Следует ожидать, что статическая память должна иметь примерно одинаковое время.
РЕЗУЛЬТАТ
Итак, мы получаем следующее:
elapsedDynamic = 1.415
elapsedStatic = 6.348
Так что здесь что-то происходит, потому что статика почти в 6 раз медленнее, чем кеш.
гипотеза
Итак, у меня было 3 идеи о том, почему это так:
- Кеш пропускает, я подумал, может быть, тот факт, что мы смешиваем динамический и статический баран, происходит нечто странное. Итак, я попробовал этот тест:
.
// Some pointers to use as incrementers
uint8_t *i = reinterpret_cast<uint8_t*>(0xF0000000+0x8000+0x1000+1);
uint8_t *j = reinterpret_cast<uint8_t*>(0xF0000000+0x8000+0x1000+2);
uint8_t *b = reinterpret_cast<uint8_t*>(0xF0000000+0x8000+0x1000+3);// I replaced all of the potential memory accesses with the static ram
// variables. That way the tests have no interaction in terms of
// memory locations.
start = clock();
// Test 2, get data from the static memory.
for ((*i) = 0; (*i) < 240; ++(*i)) {
for ((*j) = 0; (*j) < 240; ++(*j)) {
(*b) = (mpc5200.sram[(*j)]);
}
}
elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
printf("elapsed static: %f\n" ,elapsedTime);
У нас есть следующие результаты:
elapsedDynamic = 0.0010
elapsedStatic = 0.2010
Так теперь это в 200 раз медленнее? Так что, я думаю, это не связано с этим?
-
Статическая память отличается от нормальной, Следующее, что я подумал, было то, что, возможно, он не взаимодействует так, как я думал, из-за этой строки:
MPC5200 содержит 16 Кбайт встроенной памяти SRAM. Эта память напрямую доступна устройству BestComm DMA. Используется в основном как
хранилище для таблицы задач и дескрипторов буфера, используемых BestComm DMA для перемещения периферийных данных в SDRAM и из других мест. Эти
дескрипторы должны быть загружены в SRAM при загрузке.
Эта SRAM находится во внутреннем регистровом пространстве MPC5200 и также доступна для ядра процессора. Как таковой он может быть использован для других
цели, такие как хранение блокнота. SRAM 16 КБ начинается с местоположения MBAR + 0x8000.
(источник)
Я не уверен, как это подтвердить или опровергнуть?
- Более медленные статические часы, Возможно, статическая память работает медленнее, как в некоторых системах?
Это можно опровергнуть, посмотрев в руководство:
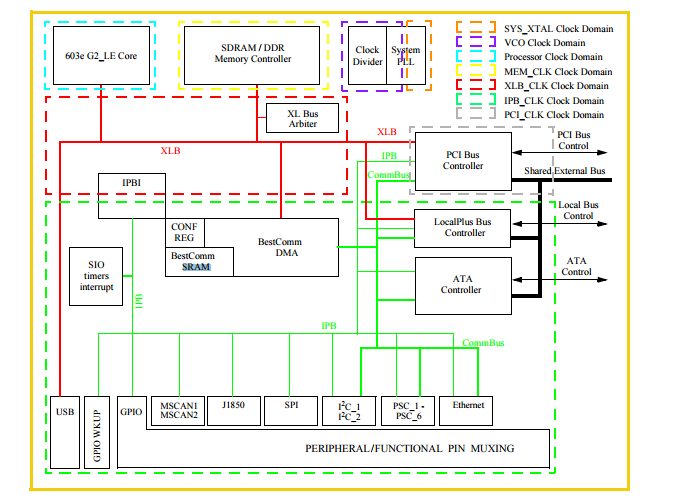
(источник)
SRAM и процессор были на одинаковых часах, XLB_CLK работает на основной частоте процессора (источник)
ВОПРОС
Что может быть причиной этого, есть ли причины вообще не использовать SRAM для хранения блокнота? Я знаю, что на современных процессорах это даже не рассматривается, но это более старый встроенный процессор, и мы боремся за скорость и пространство.
ДОПОЛНИТЕЛЬНЫЕ ИСПЫТАНИЯ
Итак, после комментариев ниже я выполнил несколько дополнительных тестов:
- добавлять
volatileчлену стека, чтобы увидеть, являются ли скорости более равными:
.
elapsedDynamic = 0.98
elapsedStatic = 5.97
Так что все еще намного быстрее, и никаких изменений с летучий??
- Разберите код, чтобы увидеть, что происходит
.
// original code
int a = 0;
uint8_t data5[0x2000];
void assemblyFunction(void) {
int * test = (int*) 0xF0008000;
mpc5200.sram[0] = a;
data5[0] = a;
test[0] = a;
}
void assemblyFunction(void) {
// I think this is to load up A
0: 3d 20 00 00 lis r9,0
8: 80 09 00 00 lwz r0,0(r9)
14: 54 0a 06 3e clrlwi r10,r0,24
mpc5200.sram[0] = a;
1c: 3d 60 00 00 lis r11,0
20: 39 6b 00 00 addi r11,r11,0
28: 3d 6b 00 01 addis r11,r11,1 // Where do these come from?
2c: 99 4b 80 00 stb r10,-32768(r11)
test[0] = a;
c: 3d 20 f0 00 lis r9,-4096 // This should be the same as above??
10: 61 29 80 00 ori r9,r9,32768
24: 90 09 00 00 stw r0,0(r9)
data5[0] = a;
4: 3d 60 00 00 lis r11,0
18: 99 4b 00 00 stb r10,0(r11)
Я не особенно хорош во взаимопроникающем ассемблере, но, может быть, у нас есть проблема здесь? Доступ к глобальной памяти и ее настройка, кажется, требуют больше инструкций для SRAM?
- Из приведенного выше теста кажется, что для указателя меньше инструкций, поэтому я добавил это:
.
uint8_t *p = (uint8_t*)0xF0008000;
// Test 3, get data from static with direct pointer.
for (int x = 0; x < 5000; ++x) {
for (int y = 0; y < 0x2000; ++y) {
a = (p[y]);
}
}
И я получаю следующий результат:
elapsed dynamic: 0.952750
elapsed static: 5.160250
elapsed pointer: 5.642125
Таким образом, указатель принимает ЕЩЕ ДОЛЬШЕ! Я бы подумал, что будет точно так же? Это просто становится незнакомым.
Решение
Похоже, есть несколько факторов, которые могут привести к этому.
- Я больше не уверен, что SRAM работает на той же тактовой частоте, что и процессор. Как указано @ user58697,
SRAMвремя на IPB, хотя похоже, что время шины на XLB. Кроме того, есть эта схема:
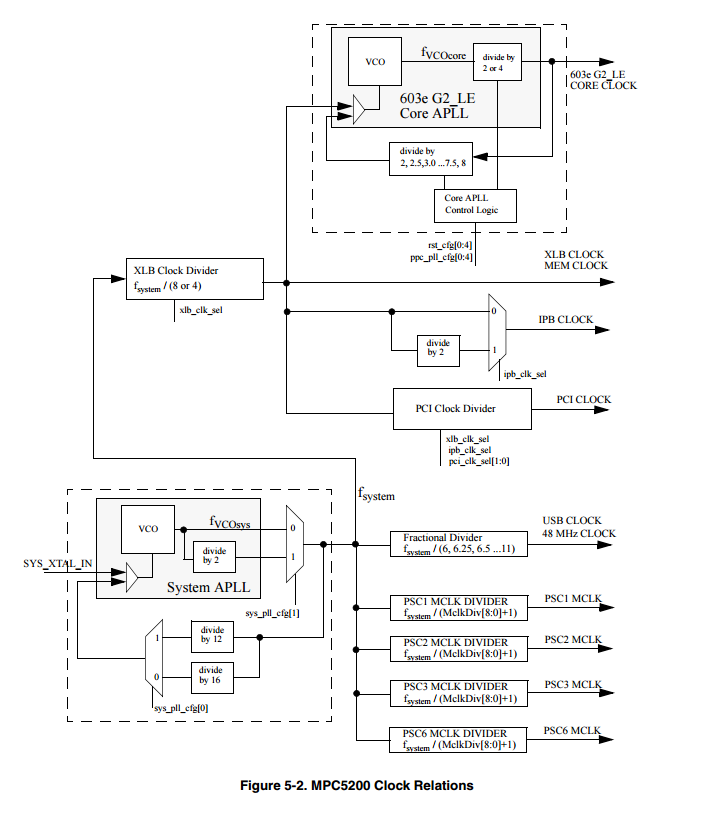
(источник)
Кажется, это указывает на то, что часы памяти находятся на пути XLB, но что путь XLB находится на более низкой частоте, чем часы CORE. Это можно подтвердить здесь:
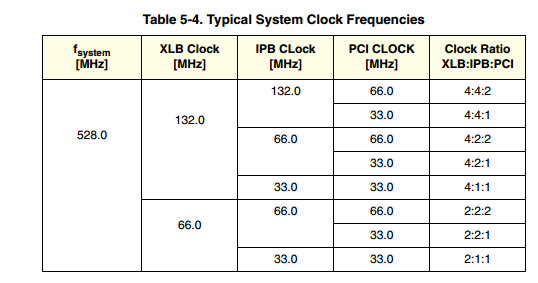
(источник)
Что указывает на то, что XLB_Bus работает медленнее, чем процессор.
- Чтобы проверить, что SRAM, по крайней мере, быстрее, чем динамический ОЗУ, я провел следующий тест:
.
// Fill up the cache with pointless stuff
for (int i = 0; i < 4097; ++i) {
a = (int)TSin[i];
}
// 1. Test the dynamic RAM access with a cache miss every time.
ticks = timer_now();
// += 16 to ensure a cache line miss.
for (int y = 0; y < listSize; y += 16) {
a = (data1[y]);
}
elapsedTicks = timer_now() - ticks;
// Fill up the cache with pointless stuff again ...
ticks = timer_now();
// Test 2, do the same cycles but with static memory.
for (int y = 0; y < listSize; y += 16) {
a = (mpc5200.sram[y]);
}
elapsedTicks = timer_now() - ticks;
И с этим мы получаем следующие результаты:
elapsed dynamic: 294.84 uS
elapsed static: 57.78 uS
Таким образом, мы можем сказать, что статическое ОЗУ быстрее, чем динамическое ОЗУ (ожидаемое), но когда динамическая ОЗУ загружается в кэш, доступ к статическому ОЗУ намного медленнее, потому что доступ к кэшу осуществляется на скорости процессора, а скорость статического ОЗУ равна намного меньше чем это.
Другие решения