Почему обработка нескольких потоков данных медленнее, чем обработка одного?
Я тестирую, как чтение нескольких потоков данных влияет на производительность кэширования ЦП. Я использую следующий код для сравнения. Тест считывает целые числа, хранящиеся последовательно в памяти, и записывает частичные суммы обратно последовательно. Количество последовательных блоков, которые считываются, варьируется. Целые числа из блоков читаются в циклическом порядке.
#include <iostream>
#include <vector>
#include <chrono>
using std::vector;
void test_with_split(int num_arrays) {
int num_values = 100000000;
// Fix up the number of values. The effect of this should be insignificant.
num_values -= (num_values % num_arrays);
int num_values_per_array = num_values / num_arrays;
// Initialize data to process
auto results = vector<int>(num_values);
auto arrays = vector<vector<int>>(num_arrays);
for (int i = 0; i < num_arrays; ++i) {
arrays.emplace_back(num_values_per_array);
}
for (int i = 0; i < num_values; ++i) {
arrays[i%num_arrays].emplace_back(i);
results.emplace_back(0);
}
// Try to clear the cache
const int size = 20*1024*1024; // Allocate 20M. Set much larger then L2
char *c = (char *)malloc(size);
for (int i = 0; i < 100; i++)
for (int j = 0; j < size; j++)
c[j] = i*j;
free(c);
auto start = std::chrono::high_resolution_clock::now();
// Do the processing
int sum = 0;
for (int i = 0; i < num_values; ++i) {
sum += arrays[i%num_arrays][i/num_arrays];
results[i] = sum;
}
std::cout << "Time with " << num_arrays << " arrays: " << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count() << " ms\n";
}
int main() {
int num_arrays = 1;
while (true) {
test_with_split(num_arrays++);
}
}
Вот моменты времени для разделения 1-80 тактов на процессоре Intel Core 2 Quad Q9550 с частотой 2,83 ГГц:
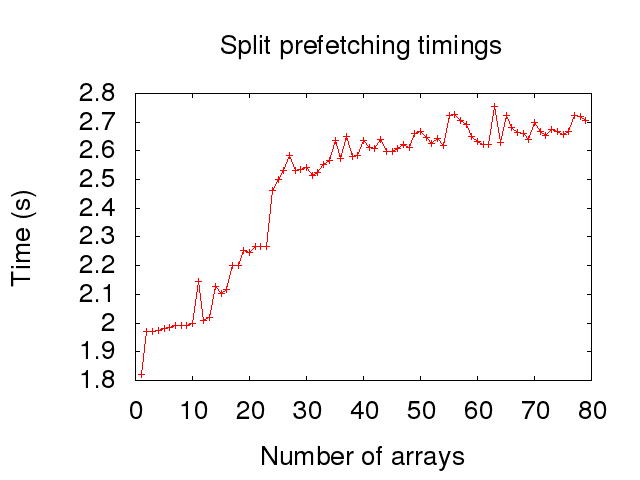
Увеличение скорости вскоре после 8 потоков имеет смысл для меня, так как процессор имеет 8-сторонний ассоциативный кэш L1. 24-сторонний ассоциативный кэш L2, в свою очередь, объясняет рост 24 потоков. Это особенно верно, если я получаю те же эффекты, что и в Почему один цикл намного медленнее двух?, где несколько больших распределений всегда оказываются в одном наборе ассоциативности. Для сравнения я включил в конце времени, когда распределение сделано в одном большом блоке.
Тем не менее, я не полностью понимаю удар от одного потока до двух потоков. Я думаю, что это как-то связано с предварительной загрузкой в кэш L1. Чтение Справочное руководство по оптимизации архитектур Intel 64 и IA-32 кажется, что потоковый предварительный выборщик L2 поддерживает отслеживание до 32 потоков данных, но такая информация не предоставляется для потокового предварительного выборщика L1. Префиксер L1 не может отслеживать несколько потоков, или здесь есть что-то еще?
Фон
Я исследую это, потому что хочу понять, как организация сущностей в игровом движке как компонентов в стиле структуры массивов влияет на производительность. На данный момент кажется, что данные, необходимые для преобразования, состоящего из двух компонентов по сравнению с 8-10 компонентами, не будут иметь большого значения для современных процессоров. Однако приведенное выше тестирование показывает, что иногда имеет смысл избегать разбиения некоторых данных на несколько компонентов, если это позволит преобразованию с «узкими местами» использовать только один компонент, даже если это означает, что какое-то другое преобразование должно будет считывать данные. не заинтересованы в.
Выделение в одном блоке
Вот временные интервалы, если вместо того, чтобы выделять несколько блоков данных, только один выделяется и к нему обращаются пошагово. Это не меняет удар от одного потока к двум, но я включил его для полноты картины.

И вот модифицированный код для этого:
void test_with_split(int num_arrays) {
int num_values = 100000000;
num_values -= (num_values % num_arrays);
int num_values_per_array = num_values / num_arrays;
// Initialize data to process
auto results = vector<int>(num_values);
auto array = vector<int>(num_values);
for (int i = 0; i < num_values; ++i) {
array.emplace_back(i);
results.emplace_back(0);
}
// Try to clear the cache
const int size = 20*1024*1024; // Allocate 20M. Set much larger then L2
char *c = (char *)malloc(size);
for (int i = 0; i < 100; i++)
for (int j = 0; j < size; j++)
c[j] = i*j;
free(c);
auto start = std::chrono::high_resolution_clock::now();
// Do the processing
int sum = 0;
for (int i = 0; i < num_values; ++i) {
sum += array[(i%num_arrays)*num_values_per_array+i/num_arrays];
results[i] = sum;
}
std::cout << "Time with " << num_arrays << " arrays: " << std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count() << " ms\n";
}
Редактировать 1
Я убедился, что различие между 1 и 2 не связано с тем, что компилятор развернул цикл и по-разному оптимизировал первую итерацию. С использованием __attribute__ ((noinline)) Я убедился, что рабочая функция не встроена в основную функцию. Я проверил, что это не произошло, посмотрев на сгенерированную сборку. Время после этих изменений было одинаковым.
Решение
Чтобы ответить на основную часть вашего вопроса: Может ли устройство предварительной выборки L1 отслеживать несколько потоков?
Нет. Это на самом деле, потому что кэш L1 вообще не имеет предварительной выборки. Кэш L1 недостаточно велик, чтобы рисковать спекулятивным извлечением данных, которые могут быть не использованы. Это приведет к слишком большому количеству выселений и отрицательно скажется на любом программном обеспечении, которое не считывает данные в определенных шаблонах, подходящих для этой конкретной схемы прогнозирования кэша L1. Вместо этого L1 кэширует данные, которые были явно читать или писать. Кэши L1 полезны только тогда, когда вы пишете данные и перечитываете данные, к которым недавно обращались.
Реализация кеша L1 не является причиной увеличения профиля от 1X до 2X глубины массива. При потоковом чтении, подобном тому, который вы настроили, кэш L1 играет мало или вообще не влияет на производительность. Большинство ваших чтений поступают непосредственно из кэша L2. В вашем первом примере с использованием вложенных векторов некоторое количество операций чтения, вероятно, извлекается из L1 (см. Ниже).
Я предполагаю, что ваш рост от 1X до 2X имеет много общего с алгоритмом и тем, как компилятор его оптимизирует. Если компилятор знает num_arrays это константа, равная 1, тогда она автоматически устранит много накладных расходов на каждую итерацию.
Теперь для второй части, что касается почему вторая версия быстрее?:
Причина того, что вторая версия более быстрая, заключается не столько в том, как данные расположены в физической памяти, а в том, что внутренняя логика меняет вложенную структуру. std::vector<std::vector<int>> Тип подразумевает.
Во вложенном (первом) случае скомпилированный код выполняет следующие шаги:
- Доступ на верхний уровень
std::vectorучебный класс. Этот класс содержит указатель на начало массива данных. - Это значение указателя должно быть загружено из памяти.
- Добавить смещение токовой петли
[i%num_arrays]к этому указателю. - Доступ вложен
std::vectorданные класса. (Вероятно, попадание в кэш L1) - Загрузить указатель на начало вектора массива данных. (Вероятно, попадание в кэш L1)
- Добавить смещение цикла
[i/num_arrays] - Читать данные. В заключение!
(обратите внимание, что шансы получить попадания в кэш L1 на шагах № 4 и № 5 резко уменьшаются после 24 потоков или около того, из-за вероятности выселения перед следующей итерацией через цикл)
Вторая версия, для сравнения:
- Доступ на верхний уровень
std::vectorучебный класс. - Загрузить указатель на начало вектора массива данных.
- Добавить смещение
[(i%num_arrays)*num_values_per_array+i/num_arrays] - Читай данные!
Весь набор ступеней под капотом удален. Расчет для смещения немного длиннее, так как он требует дополнительного умножения на num_values_per_array, Но другие шаги более чем восполняют это.
Другие решения
detector