Почему этот метод, использующий putchar_unlocked, медленнее, чем printf и cout для печати строк?
Я изучаю способы ускорения своих кодов для соревнований по программированию, используя в качестве основы ускорение обработки ввода и вывода.
Я в настоящее время использую нить небезопасно putchar_unlocked функция для печати некоторых тестов. Я считал, что эта функция была быстрее, чем соиЬ е Printf к некоторым типам данных, если они реализованы должным образом из-за своей разблокируемой потоком природы.
Я реализовал функцию для печати строк таким способом (очень простой, на мой взгляд):
void write_str(char s[], int n){
int i;
for(i=0;i<n;i++)
putchar_unlocked(s[i]);
}
Я проверил со строкой размера N и точно N персонажи.
Но это самый медленный из трех, как мы можем видеть на этом графике числа выходных записей в зависимости от времени в секундах:
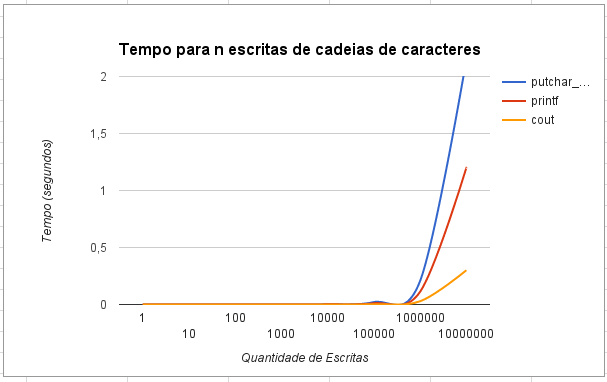
Почему это самый медленный?
Решение
Выбор более быстрого способа вывода строк вступает в конфликт с используемой платформой, операционной системой, настройками компилятора и библиотекой времени выполнения, но есть некоторые обобщения, которые могут помочь понять, что выбрать.
Во-первых, учтите, что операционная система может иметь средство отображения строк по сравнению с символами по одному за раз, и если это так, то циклическое выполнение системного вызова для вывода символов по одному за раз естественным образом вызовет издержки для каждого вызова системы, в отличие от затрат на один системный вызов, обрабатывающий массив символов.
Это в основном то, с чем вы сталкиваетесь, системный вызов.
Повышение производительности putchar_unlocked по сравнению с putchar может быть значительным, но только между этими двумя функциями. Кроме того, большинство библиотек времени выполнения не имеют putchar_unlocked (я нахожу это в более старой документации MAC OS X, но не в Linux или Windows).
Тем не менее, заблокировано или разблокировано, для каждого символа по-прежнему будут накладные расходы, которые могут быть исключены для системного вызова, обрабатывающего весь массив символов, и такие понятия распространяются на вывод в файлы или другие устройства, а не только на консоль.
Другие решения
Предполагая, что измерения времени примерно для 1 000 000 миллионов символов ниже порога измерения, и записи в std::cout а также stdout сделаны с использованием формы с использованием массовых записей (например, std::cout.write(str, size)), Я думаю, что putchar_unlock() тратит большую часть своего времени на обновление некоторой части структур данных в дополнение к вводу символа. Другие массовые записи будут копировать данные в буфер навалом (например, используя memcpy()) и обновлять структуры данных только один раз.
То есть коды будут выглядеть примерно так (это код-пиджон, то есть просто примерно показывает, что происходит; реальный код будет, по крайней мере, немного сложнее):
int putchar_unlocked(int c) {
*stdout->put_pointer++ = c;
if (stdout->put_pointer != stdout->buffer_end) {
return c;
}
int rc = write(stdout->fd, stdout->buffer_begin, stdout->put_pointer - stdout->buffer_begin);
// ignore partial writes
stdout->put_pointer = stdout->buffer_begin;
return rc == stdout->buffer_size? c: EOF;
}
Массовая версия кода вместо этого делает что-то вроде этого (используя нотацию C ++, так как легче быть разработчиком C ++; опять же, это pidgeon-код):
int std::streambuf::write(char const* s, std::streamsize n) {
std::lock_guard<std::mutex> guard(this->mutex);
std::streamsize b = std::min(n, this->epptr() - this->pptr());
memcpy(this->pptr(), s, b);
this->pbump(b);
bool success = true;
if (this->pptr() == this->epptr()) {
success = this->this->epptr() - this->pbase()
!= write(this->fd, this->pbase(), this->epptr() - this->pbase();
// also ignoring partial writes
this->setp(this->pbase(), this->epptr());
memcpy(this->pptr(), s + b, n - b);
this->pbump(n - b);
}
return success? n: -1;
}
Второй код может выглядеть немного сложнее, но выполняется только один раз для 30 символов. Большая часть проверки удалена из интересного. Даже если есть какая-то блокировка, она блокирует неконтролируемый мьютекс и не будет сильно тормозить обработку.
Особенно, когда не выполняется профилирование цикла с использованием putchar_unlocked() не будет сильно оптимизирован. В частности, код не будет векторизован, что приведет к немедленному коэффициенту, по крайней мере, около 3, но, вероятно, даже ближе к 16 в остальном цикле. Стоимость за замок быстро уменьшится.
Кстати, просто для того, чтобы создать достаточно ровную игровую площадку: помимо оптимизации вы должны также позвонить std::sync_with_stdio(false) при использовании C ++ стандартных потоковых объектов.
Мое личное предположение состоит в том, что printf () делает это в чанках, и для каждого чанка нужно только иногда проходить границу приложения / ядра.
putchar_unlocked () делает это для каждого записанного байта.