Отображение японских символов в визуальном переполнении стека
У кого-нибудь здесь есть идея, как работать с японским персонажем в Visual C ++?
Я пытаюсь отобразить японское имя в консоли с Visual C ++.
#include "stdafx.h"#include <string>
#include <iostream>
using namespace std;
int main()
{
cout << "北島 美奈" << endl;
return 0;
}
Вывод в консоль:
?? ??
Press any key to continue ...
Надеюсь, кто-то может помочь. Спасибо.
Решение
Я тестировал свой собственный код как UTF-8, так и EUC-KR (корейский) в окне консоли, используя cmd.exe.
Это мой исходный код.
#include <string>
#include <iostream>
#include <windows.h>
int main()
{
int codepage = CP_ACP; //CP_ACP, CP_OEMCP
int conv_codepage = CP_UTF8; //CP_UTF8
char str[256];
char str1[256];
wchar_t tstr[256], tstr2[256];
memset(str, 0x00, 256);
memset(str1, 0x00, 256);
memset(tstr, 0x00, 256);
memset(tstr2, 0x00, 256);
memcpy(str, " 北島 美奈", sizeof(str));
int nLen = MultiByteToWideChar(codepage, 0, str, -1, 0, 0);
MultiByteToWideChar(codepage, 0, str, -1, tstr, nLen);
int len = WideCharToMultiByte( conv_codepage, 0, tstr, -1, NULL, 0, 0, 0 );
WideCharToMultiByte(conv_codepage, 0, tstr, -1, str1, len ,0 ,0);
cout << "2... " << str1 << endl;
return 0;
}
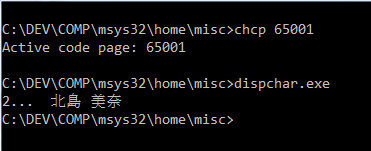
случай 1 UTF-8: результат на консоли
Вывод является разумным, потому что переменная str1 является строкой utf-8.
У меня правильный utf-8 в окне консоли utf-8.
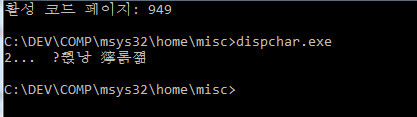
случай 2 EUC-KR: результат на консоли
Я думаю, что в этом случае также допустима строка utf-8 со строкой utf-8.
Затем изменив код следующим образом
cout << "2... " << str << endl;
в
cout << "2... " << str1 << endl;
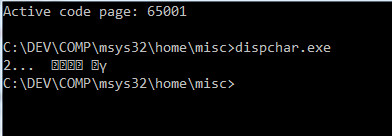
случай 1 UTF-8: результат на консоли
Я думаю, что это нормально для строки Unicode на консоли utf-8.
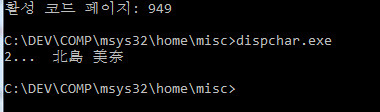
случай 1 EUC-KR: результат на консоли
Это все еще правильная строка Юникода в кодовой странице euc-kr.
Другие решения
Других решений пока нет …