Оптимизация компилятора устраняет последствия ложного обмена. Как?
Я пытаюсь повторить эффект ложного обмена с использованием OpenMP, как описано в Введение в OpenMP Тимом Мэттсоном.
Моя программа выполняет простую числовую интеграцию (см. Ссылку для математических деталей), и я реализовал две версии, первая из которых должна быть кеш-ориентированной, чтобы каждый поток сохранял локальную переменную для накопления своей части пространства индекса ,
const auto num_slices = 100000000;
const auto num_threads = 4; // Swept from 1 to 9 threads
const auto slice_thickness = 1.0 / num_slices;
const auto slices_per_thread = num_slices / num_threads;
std::vector<double> partial_sums(num_threads);
#pragma omp parallel num_threads(num_threads)
{
double local_buffer = 0;
const auto thread_num = omp_get_thread_num();
for(auto slice = slices_per_thread * thread_num; slice < slices_per_thread * (thread_num + 1); ++slice)
local_buffer += func(slice * slice_thickness); // <-- Updates thread-exclusive buffer
partial_sums[thread_num] = local_buffer;
}
// Sum up partial_sums to receive final result
// ...
в то время как вторая версия имеет каждый поток обновить элемент в общем std::vector<double>вызывая каждую запись, чтобы сделать недействительными строки кэша во всех других потоках
// ... as above
#pragma omp parallel num_threads(num_threads)
{
const auto thread_num = omp_get_thread_num();
for(auto slice = slices_per_thread * thread_num; slice < slices_per_thread * (thread_num + 1); ++slice)
partial_sums[thread_num] += func(slice * slice_thickness); // <-- Invalidates caches
}
// Sum up partial_sums to receive final result
// ...
Проблема в том, что Я не вижу каких-либо последствий ложного обмена, пока не отключу оптимизацию.
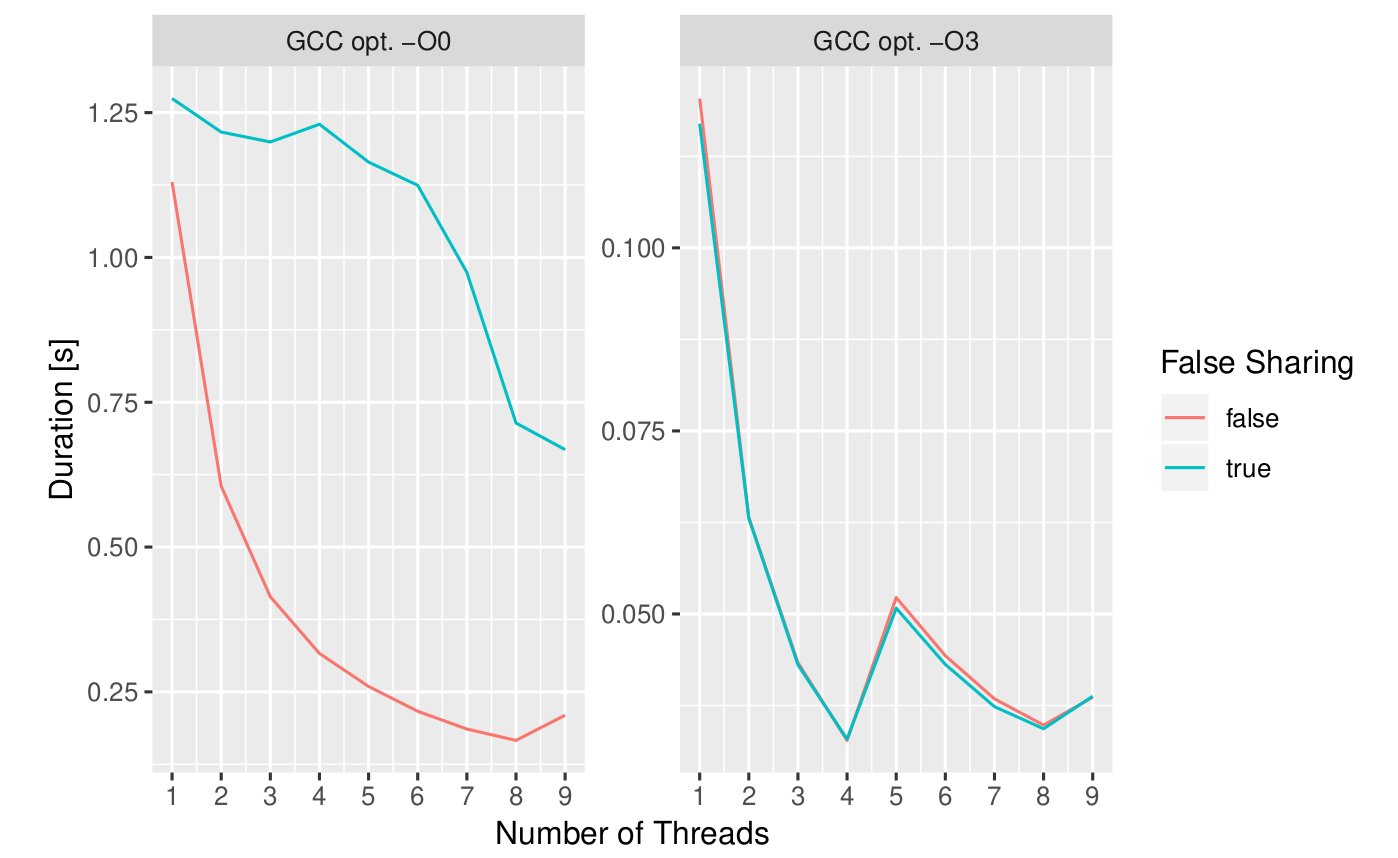
Компиляция моего кода (который должен учитывать несколько больше деталей, чем приведенные выше фрагменты) с использованием GCC 8.1 без оптимизации (-O0) дает результаты, которых я наивно ожидал, при использовании полной оптимизации (-O3) устраняет любые различия в производительности между две версии, как показано на сюжете.
Чем это объясняется? Устраняет ли компилятор ложное совместное использование? Если нет, то почему этот эффект настолько мал при запуске оптимизированного кода?
Я на машине с Core-i7, использующей Fedora. График отображает средние значения, для которых стандартные отклонения выборки не добавляют никакой информации к этому вопросу.
Решение
tl; dr: компилятор оптимизирует вашу вторую версию в первую.
Рассмотрим код в цикле вашей второй реализации — на мгновение игнорируем его OMP / многопоточный аспект.
У вас есть приращения значения в пределах std::vector — который обязательно находится в куче (ну, в любом случае, вплоть до C ++ 17). Компилятор видит, что вы добавляете значение в кучу в цикле; это типичный кандидат на оптимизацию: он берет доступ к куче из цикла и использует регистр в качестве буфера. Это даже не нужно читать из кучи, так как они просто дополнения — так что это, по сути, приходит к вашему первому решению.
Смотрите это происходит на GodBolt (с упрощенным примером) — обратите внимание, как код для bar1() а также bar2() почти то же самое, с накоплением происходит в регистрах.
Теперь тот факт, что задействованы многопоточность и OMP, не меняет вышесказанного. Если бы вы использовали, скажем, std::atomic<double> вместо double, Затем это может быть изменились (и, может быть, даже тогда, если компилятор достаточно умен).
Заметки:
- Спасибо @Evg за то, что он заметил явную ошибку в коде предыдущей версии этого ответа.
- Компилятор должен быть в состоянии знать тот
func()также не изменит значение вашего вектора — или решит, что для целей добавления это не должно иметь большого значения. - Эта оптимизация может рассматриваться как Снижение Силы — от операции в куче до операции в реестре — но я не уверен, что термин используется в этом случае.
Другие решения
Других решений пока нет …