OpenCV — удаление шума на изображении
У меня есть изображение здесь с таблицей .. В столбце справа фон заполнен шумом
Как обнаружить участки с шумом? Я только хочу применить какой-то фильтр к частям с шумом, потому что мне нужно сделать OCR для него, и любой вид фильтра уменьшит общее распознавание
А какой фильтр лучше всего удаляет фоновые шумы на изображении?
Как сказал мне нужно сделать OCR на изображении
Решение
Я пробовал некоторые фильтры / операции в OpenCV, и это, кажется, работает довольно хорошо.
Шаг 1: распространяться изображение —
kernel = np.ones((5, 5), np.uint8)
cv2.dilate(img, kernel, iterations = 1)

Как видите, шум исчез, но символы очень легкие, поэтому я размыл изображение.
Шаг 2: разъедать изображение —
kernel = np.ones((5, 5), np.uint8)
cv2.erode(img, kernel, iterations = 1)

Как видите, шум исчез, однако некоторые символы в других столбцах не работают. Я бы порекомендовал выполнять эти операции только на шумном столбце. Вы можете использовать HoughLines найти последний столбец. Затем вы можете извлечь только этот столбец, выполнить расширение + эрозию и заменить его соответствующим столбцом в исходном изображении.
Кроме того, дилатация + эрозия на самом деле операция называется закрытие. Это вы можете позвонить напрямую, используя —
cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
Как предположил @Ermlg, medianBlur с ядром 3 также прекрасно работает.
cv2.medianBlur(img, 3)
Альтернативный Шаг
Как видите, все эти фильтры работают, но лучше применять эти фильтры только в той части, где присутствует шум. Для этого используйте следующее:
edges = cv2.Canny(img, 50, 150, apertureSize = 3) // img is gray here
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 100, 1000, 50) // last two arguments are minimum line length and max gap between two lines respectively.
for line in lines:
for x1, y1, x2, y2 in line:
print x1, y1
// This gives the start coordinates for all the lines. You should take the x value which is between (0.75 * w, w) where w is the width of the entire image. This will give you essentially **(x1, y1) = (1896, 766)**
Затем вы можете извлечь эту часть только как:
extract = img[y1:h, x1:w] // w, h are width and height of the image

Затем примените фильтр (медиана или закрытие) на этом изображении. После удаления шума вам нужно поместить это отфильтрованное изображение вместо размытой части исходного изображения.
изображение [y1: h, x1: w] = медиана
Это просто в C ++:
extract.copyTo(img, new Rect(x1, y1, w - x1, h - y1))
Окончательный результат с альтернативным методом
Надеюсь, поможет!
Другие решения
Мое решение основано на пороговой настройке, чтобы получить изображение в 4 шага.
- Читать изображение по
OpenCV 3.2.0, - Применять
GaussianBlur()чтобы сгладить изображение, особенно область в сером цвете. - Маска изображения, чтобы изменить текст на белый, а остальные на черный.
- Инвертировать замаскированное изображение в черный текст белым.
Код находится в Python 2.7, Это можно изменить на C++ без труда.
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# read Danish doc image
img = cv2.imread('./imagesStackoverflow/danish_invoice.png')
# apply GaussianBlur to smooth image
blur = cv2.GaussianBlur(img,(5,3), 1)
# threshhold gray region to white (255,255, 255) and sets the rest to black(0,0,0)
mask=cv2.inRange(blur,(0,0,0),(150,150,150))
# invert the image to have text black-in-white
res = 255 - mask
plt.figure(1)
plt.subplot(121), plt.imshow(img[:,:,::-1]), plt.title('original')
plt.subplot(122), plt.imshow(blur, cmap='gray'), plt.title('blurred')
plt.figure(2)
plt.subplot(121), plt.imshow(mask, cmap='gray'), plt.title('masked')
plt.subplot(122), plt.imshow(res, cmap='gray'), plt.title('result')
plt.show()
Ниже приведены нанесенные изображения по коду для справки.
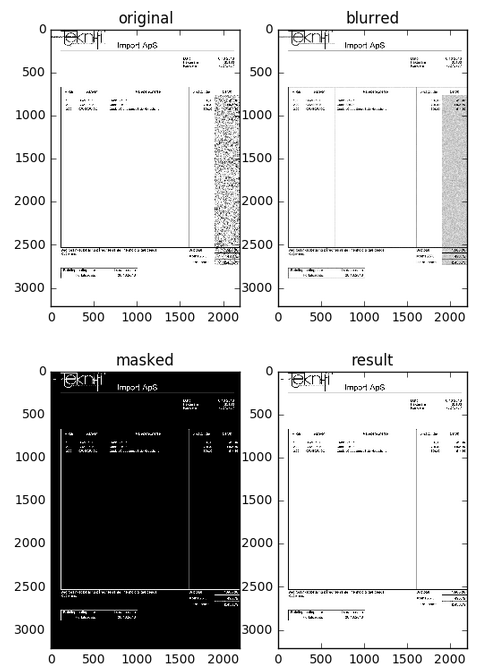
Здесь изображение результата в 2197 х 3218 пикселей.
Как я знаю, медианный фильтр — лучшее решение для снижения шума. Я бы порекомендовал использовать медианный фильтр с окном 3х3. Смотрите функцию резюме :: medianBlur ().
Но будьте осторожны при использовании любой фильтрации шума одновременно с OCR. Это может привести к снижению точности распознавания.
Также я рекомендовал бы попробовать использовать пару функций (cv :: erode () и cv :: dlate ()). Но я не уверен, что это будет лучшим решением, чем cv :: medianBlur () с окном 3×3.
Я бы пошел с медианным размытием (вероятно, 5 * 5 ядро).
если вы планируете применить OCR изображение. Я бы посоветовал вам следующее:
- Фильтруйте изображение с помощью Median Filter.
- Находя контуры на отфильтрованном изображении, вы получите только текстовые контуры (называйте их F).
- Найти контуры в исходном изображении (назовите их О).
- выделить все контуры в О которые пересекаются с любым контуром в F.
Более быстрое решение:
- Найти контуры в исходном изображении.
- Фильтруйте их по размеру.
Если вы очень беспокоитесь об удалении пикселей, которые могут повредить обнаружение распознавания текста. Не добавляя артефакты, вы можете быть настолько чистыми, насколько это возможно. Затем вы должны создать BLOB-фильтр. И удалите любые капли, которые меньше n пикселей или около того.
Не собираюсь писать код, но я знаю, что это прекрасно работает, так как я использую это сам, хотя я не использую openCV (я написал свой собственный многопоточный blobfilter из соображений скорости). И извините, но я не могу поделиться своим кодом здесь. Просто описываю, как это сделать.
Если время обработки не является проблемой, очень эффективным способом в этом случае будет вычисление всех компонентов, соединенных черным, и удаление тех, которые меньше нескольких пикселей. Это удалит все зашумленные точки (кроме тех, которые касаются допустимого компонента), но сохранит все символы и структуру документа (строки и т. Д.).
Функция для использования будет connectedComponentWithStats (прежде чем вам, вероятно, понадобится создать негативное изображение, порог функция с THRESH_BINARY_INV будет работать в этом случае), рисуя белые прямоугольники, где маленькие связанные компоненты, где найдены.
Фактически, этот метод может использоваться для поиска символов, определенных как связанные компоненты заданного минимального и максимального размера и с соотношением сторон в заданном диапазоне.
Я уже сталкивался с той же проблемой и получил лучшее решение.
Преобразовать исходное изображение в изображение в градациях серого и применить fastNlMeanDenoising функция, а затем применить порог.
Как это — fastNlMeansDenoising (серый, ДСТ, 3.0,21,7);
Порог (ДСТ, finaldst, 150255, THRESH_BINARY);
ТАКЖЕ использовать можно настроить порог в соответствии с вашим фоновым шумом изображения.
например- Порог (ДСТ, finaldst, 200255, THRESH_BINARY);
ПРИМЕЧАНИЕ. — Если ваши строки столбцов были удалены … Вы можете взять маску строк столбцов из исходного изображения и применить к обесцвеченному полученному изображению, используя такие операции BITWISE, как AND, OR, XOR.