opencv c ++ сравнивает ключевые точки в разных изображениях
При сравнении 2 изображений через feature extractionкак вы сравниваете keypoint расстояния, чтобы игнорировать те, которые явно неверны?
Я обнаружил, что при сравнении похожих изображений друг с другом большую часть времени он может быть достаточно точным, но в других случаях он может создавать совершенно разные совпадения.
Так что я после того, как смотреть на 2 комплекта keypoints по обоим изображениям и определения соответствия keypoints относительно в одинаковых местах на обоих. Как в нем знает что keypoints 1, 2 и 3 находятся на большом расстоянии друг от друга на изображении 1, поэтому соответствующие ключевые точки, сопоставленные на изображении 2, должны снова находиться на довольно близком расстоянии друг от друга.
Я использовал RANSAC а также minimum distance проверки в прошлом, но только с некоторым эффектом, они не кажутся такими тщательными, как я.
(С помощью ORB а также BruteForce)
РЕДАКТИРОВАТЬ
Изменено «х, у и г» в «1, 2 и 3»
РЕДАКТИРОВАТЬ 2 — Я попытаюсь объяснить дальше с помощью быстрых примеров, сделанных Paint:
Скажем, у меня есть это как мой образ:

И я даю это изображение для сравнения:

Это обрезанная и сжатая версия оригинала, но, очевидно, похожая.
Теперь, скажем, вы пробежали feature detection и он вернулся с этими результатами для keypoints для двух изображений:


keypoints на обоих изображениях находятся примерно в одинаковых областях и пропорционально на одинаковом расстоянии друг от друга. Возьмите keypoint Я обведен, давайте назовем это «Изображение 1 Ключевой пункт 1».
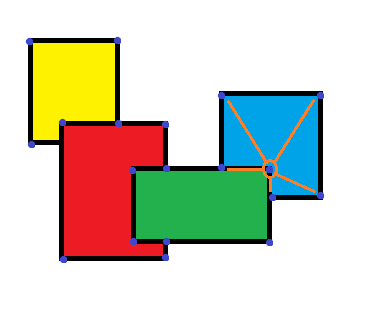
Мы можем видеть, что есть 5 keypoints вокруг него. Это эти расстояния между ними и «Изображение 1 Ключевой пункт 1» что я хочу получить, чтобы сравнить их с «Изображение 2, ключевой момент 1» и его 5 окружают keypoints в той же области (см. ниже), чтобы не просто сравнить keypoint другому keypoint, но для сравнения «известные фигуры» основанный на местонахождении keypoints,
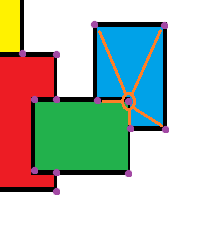
—
Имеет ли это смысл?
Решение
Сопоставление ключевых точек является проблемой с несколькими измерениями. Эти размеры:
- пространственный расстояние, т. е.
(x,y)расстояние, измеренное от расположения двух ключевых точек на разных изображениях - особенность расстояние, то есть расстояние, которое описывает насколько две ключевые точки выглядят одинаково.
В зависимости от вашего контекста, вы не хотите вычислять одно и то же расстояние или хотите комбинировать оба. Вот несколько вариантов использования:
- оптический поток, как реализовано в OpenCV разреженный оптический поток Лукаса-Канаде. В этом случае ключевые точки называются хорошие функции вычисляются в каждом кадре, а затем сопоставляются на пространственный основа расстояния. Это работает, потому что изображение должно изменяться относительно медленно (входные кадры имеют частоту видеокадров);
- сшивание изображения, как вы можете реализовать из OpenCV features2d (бесплатно или несвободный). В этом случае изображения радикально меняются, поскольку вы перемещаете камеру. Затем ваша цель состоит в том, чтобы найти устойчивые точки, то есть точки, которые присутствуют на двух или более изображениях независимо от их местоположения. В этом случае вы будете использовать особенность расстояние. Это также верно, когда у вас есть шаблонное изображение объекта, которое вы хотите найти в изображениях запросов.
Для того, чтобы вычислить особенность расстояние, вам нужно вычислить кодированный вариант их появления. Эта операция выполняется DescriptorExtractor учебный класс.
Затем вы можете вычислить расстояния между выходными данными описаний: если расстояние между двумя описаниями невелико, исходные ключевые точки с большой вероятностью соответствуют одной и той же точке сцены.
Обратите внимание, когда вы вычисляете расстояния, чтобы использовать правильную функцию расстояния: ORB, FREAK, BRISK полагаются на расстояние Хэмминга, в то время как SIFt и SURF используют более обычное расстояние L2.
Фильтрация совпадений
Если у вас есть отдельные совпадения, вы можете захотеть выполнить фильтрацию совпадений, чтобы отклонить хорошие индивидуальные совпадения, которые могут возникнуть из-за неясностей сцены. Подумайте, например, о ключевой точке, которая исходит из угла окна дома. Тогда вполне вероятно, что оно будет совпадать с другим окном в другом доме, но это может быть не хороший дом или хорошее окно.
У вас есть несколько способов сделать это:
- RANSAC выполняет проверку согласованности вычисленных совпадений с текущей оценкой решения. По сути, он выбирает некоторые совпадения случайным образом, вычисляет решение проблемы (обычно это геометрическое преобразование между двумя изображениями), а затем подсчитывает, сколько совпадений соответствует этой оценке. Оценка с более высоким числом выигрышей;
- Дэвид Лоу выполнил другой вид фильтрации в оригинальной SIFT-статье.
Он оставил двух лучших кандидатов на совпадение с заданной ключевой точкой запроса, то есть точками, которые имели наименьшее расстояние (или наибольшее сходство). Затем он рассчитал соотношениеsimilarity(query, best)/similarity(query, 2nd best), Если это соотношение слишком низкое, то второй лучший вариант также является хорошим кандидатом на совпадение, и результат сопоставления дублируется неоднозначно и отклоняется.
То, как именно вы должны это делать в вашем случае, очень вероятно, будет зависеть от вашего конкретного применения.
Ваш конкретный случай
В вашем случае вы хотите разработать дескриптор альтернативной функции это основано на соседних ключевых точках.
Небо здесь явно предел, но вот несколько шагов, которым я бы следовал:
-
сделать вращение дескриптора и масштабировать инвариантным путем вычисления PCA из ключевых точек:
// Form a matrix from KP locations in current image cv::Mat allKeyPointsMatrix = gatherAllKeypoints(keypoints); // Compute PCA basis cv::PCA currentPCA(allKeyPointsMatrix, 2); // Reproject keypoints in new basis cv::Mat normalizedKeyPoints = currentPCA.project(allKeyPointsMatrix); -
(необязательно) сортировка ключевых точек в дереве quadtree или kd для ускорения пространственной индексации
- Вычислить для каждой ключевой точки дескриптор, который (например) является смещением в нормализованных координатах 4 или 5 ближайших ключевых точек
- Сделайте то же самое в вашем изображении запроса
- Сопоставьте ключевые точки обоих магов на основе этих новых дескрипторов.
Другие решения
Что именно вы пытаетесь сделать именно? Требуется больше информации, чтобы дать вам хороший ответ. В противном случае он должен быть очень широким и, скорее всего, бесполезным для ваших нужд.
А с вашим утверждением «определение, находятся ли совпадающие ключевые точки относительно в одинаковых местах на обоих», вы имеете в виду буквально на одних и тех же точках x, y между двумя изображениями?
Я бы попробовал алгоритм SURF. Это работает очень хорошо для того, что вы описали выше (хотя я нашел, что это будет немного медленно, если вы не используете ускорение GPU, 5 кадр / с против 34 кадр / с).
Вот учебник для серфинга, лично я нашел его очень полезным, но исполняемые файлы предназначены только для пользователей Linux. Однако вы можете просто удалить специфичные для ОС привязки в исходном коде и оставить только привязки, связанные с opencv, и сделать так, чтобы компиляция + работала на linux точно такой же.
https://code.google.com/p/find-object/#Tutorials
Надеюсь, это помогло!
Вы можете сделать фильтр по расстоянию в пикселях между двумя ключевыми точками.
Допустим, совпадения — это ваш вектор совпадений, kp_1 — ваш вектор ключевых точек на первом изображении и kp_2 — на втором. Вы можете использовать приведенный выше код для устранения явно неправильных совпадений. Вам просто нужно установить порог.
double threshold= YourValue;
vector<DMatch> good_matches;
for (int i = 0; i < matches.size(); i++)
{
double dist_p = sqrt(pow(abs(kp_1[matches[i][0].queryIdx].pt.x - kp_2[matches[i][0].trainIdx].pt.x), 2) + pow(abs(kp_1[matches[i][0].queryIdx].pt.y - kp_2[matches[i][0].trainIdx].pt.y), 2));
if (dist_p < threshold)
{
good_matches.push_back(matches[i][0]);
}
}