Непоследовательное поведение в идентичном коде
После выполнения имитации физики в течение примерно 20 минут срабатывает ловушка ошибки. Понимая, что это будет проблематично, я продублировал соответствующую подпрограмму в новом проекте и назвал ее жестко закодированными копиями исходных входных данных в момент возникновения ошибки. Но ловушка ошибки не сработала! После двух дней кропотливой работы, чтобы выделить точную точку, где поведение двух экземпляров подпрограммы расходится, я проследил проблему до очень простой функции для вычисления Cross_Product.
Эта функция Cross_Product идентична в обеих программах. Я даже проверил разборку и убедился, что компилятор выдает идентичный код. Функция также получает идентичные входные данные в обоих случаях. Я даже явно проверил режим округления внутри функций, и они идентичны. Тем не менее, они возвращают немного разные результаты. В частности, LSB отличается для двух из трех возвращенных векторных компонентов. Даже сам отладчик подтверждает, что эти две из трех переменных не равны выражениям, которые им были явно назначены. (Смотрите скриншот ниже.)
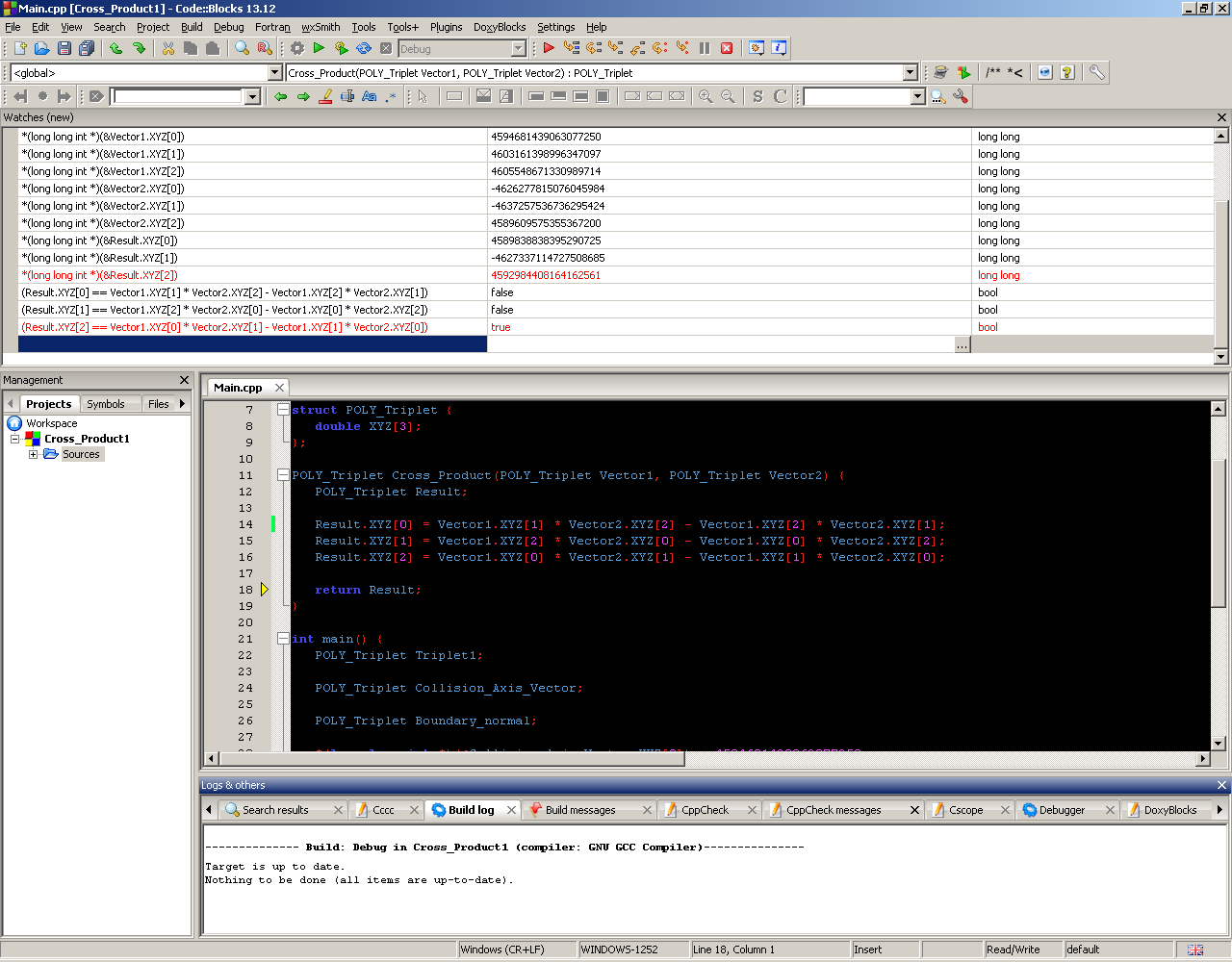
В исходной программе отладчик показывает «true» во всех трех последних строках списка наблюдения, а не только в последней.
Я использую Code :: Blocks 13.12 с компилятором GCC на XP с процессором AMD Athlon 64. Однако я перекомпилировал и запустил тестовую программу в Code :: Blocks 16.01 на гораздо более современной машине с Windows 10 с процессором Intel Core i5, и результаты были идентичны.
Вот мой минимальный, полный и проверяемый код для воспроизведения странного результата, который не соответствует моей исходной программе и самому отладчику (к сожалению, я не могу включить оригинальную физическую программу, потому что она ОГРОМНА):
extern "C" {
__declspec(dllimport) int __stdcall IsDebuggerPresent(void);
__declspec(dllimport) void __stdcall DebugBreak(void);
}
struct POLY_Triplet {
double XYZ[3];
};
POLY_Triplet Cross_Product(POLY_Triplet Vector1, POLY_Triplet Vector2) {
POLY_Triplet Result;
Result.XYZ[0] = Vector1.XYZ[1] * Vector2.XYZ[2] - Vector1.XYZ[2] * Vector2.XYZ[1];
Result.XYZ[1] = Vector1.XYZ[2] * Vector2.XYZ[0] - Vector1.XYZ[0] * Vector2.XYZ[2];
Result.XYZ[2] = Vector1.XYZ[0] * Vector2.XYZ[1] - Vector1.XYZ[1] * Vector2.XYZ[0];
return Result;
}
int main() {
POLY_Triplet Triplet1;
POLY_Triplet Collision_Axis_Vector;
POLY_Triplet Boundary_normal;
*(long long int *)(&Collision_Axis_Vector.XYZ[0]) = 4594681439063077250;
*(long long int *)(&Collision_Axis_Vector.XYZ[1]) = 4603161398996347097;
*(long long int *)(&Collision_Axis_Vector.XYZ[2]) = 4605548671330989714;
*(long long int *)(&Triplet1.XYZ[0]) = -4626277815076045984;
*(long long int *)(&Triplet1.XYZ[1]) = -4637257536736295424;
*(long long int *)(&Triplet1.XYZ[2]) = 4589609575355367200;
if (IsDebuggerPresent()) {
DebugBreak();
}
Boundary_normal = Cross_Product(Collision_Axis_Vector, Triplet1);
return 0;
}
Для удобства вот соответствующие строки для списка наблюдения, как показано на скриншоте:
(Result.XYZ[0] == Vector1.XYZ[1] * Vector2.XYZ[2] - Vector1.XYZ[2] * Vector2.XYZ[1])
(Result.XYZ[1] == Vector1.XYZ[2] * Vector2.XYZ[0] - Vector1.XYZ[0] * Vector2.XYZ[2])
(Result.XYZ[2] == Vector1.XYZ[0] * Vector2.XYZ[1] - Vector1.XYZ[1] * Vector2.XYZ[0])
Кто-нибудь может объяснить, пожалуйста, это поведение?
Решение
Я могу подтвердить, что получаемый вами проблемный результат может быть вызван изменением точности x87. Значение точности сохраняется в регистре управления FPU x87, и при изменении оно сохраняется в течение всего времени жизни вашего потока, влияя на весь код x87, выполняющийся в потоке.
По-видимому, какой-то другой компонент вашей огромной программы (или используемой вами внешней библиотеки) иногда меняет длину мантиссы с 53 бит (что по умолчанию) до 64 бит (что означает использование полной точности этих 80-битных регистров x87).
Лучший способ исправить это — переключить ваш компилятор с x87 на SSE2 target. SSE всегда использует 32- или 64-разрядные числа с плавающей запятой (в зависимости от используемых инструкций), у него вообще нет 80-разрядных регистров. Даже ваш 2003 Athlon 64 уже поддерживает этот набор инструкций. Как побочный эффект, ваш код станет несколько быстрее.
Обновить: Если вы не хотите переключаться на SSE2, вы можете сбросить точность до любого значения, которое вам нравится. Вот как это сделать в Visual C ++:
#include <float.h>
uint32_t prev;
_controlfp_s( &prev, _PC_53, _MCW_PC ); // or _PC_64 for 80-bit
Для GCC это что-то вроде этого (не проверено)
#include <fpu_control.h>
#define _FPU_PRECISION ( _FPU_SINGLE | _FPU_DOUBLE | _FPU_EXTENDED )
fpu_control_t prev, curr;
_FPU_GETCW( prev );
curr = ( prev & ~_FPU_PRECISION ) | _FPU_DOUBLE; // or _FPU_EXTENDED for 80 bit
_FPU_SETCW( curr );
Другие решения
*(long long int *)(&Collision_Axis_Vector.XYZ[0]) = 4594681439063077250;
и все подобные строки вводят Неопределенное поведение в программе, потому что они нарушают Строгое правило алиасинга:
вы получаете двойное значение как long long int
Скомпилировал ваш пример с Visual C ++.
Я могу подтвердить, что вывод немного отличается от того, что вы видите в отладчике, вот мой:
CAV: 4594681439063077250, 4603161398996347097, 4605548671330989714
T1: -4626277815076045984, -4637257536736295424, 4589609575355367200
CP: 4589838838395290724, -4627337114727508684, 4592984408164162561
Я не знаю наверняка, что может вызвать разницу, но вот идея.
Поскольку вы уже рассматривали машинный код, что вы компилируете в устаревшую версию x87 или SSE? Я предполагаю, что это SSE, большинство компиляторов выбирают его по умолчанию уже в течение многих лет. Если вы пройдете -march native к gcc, очень вероятно, что ваш процессор имеет некоторый набор инструкций FMA (AMD с конца 2011 года, Intel с 2013 года). Поэтому ваш компилятор GCC использовал эти _mm_fmadd_pd / _mm_fmsub_pd внутренние, вызывая вашу 1-битную разницу.
Однако это все теория. Мой совет, вместо того, чтобы пытаться выяснить, что вызвало эту разницу, вы должны исправить свой внешний код.
Плохая идея отлавливать отладчик в результате таких условий.
Числовая разница очень мала. Это наименее значимый бит в 52-битной мантиссе, то есть ошибка составляет всего 2 ^ (- 52).
Даже если вы узнаете, что вызвало это, отключите, например, FMA или что-то другое, что вызвало проблему, делая это хрупко, то есть вы будете поддерживать этот хак в течение всего срока реализации проекта. Вы модернизируете свой компилятор, или компилятор решит оптимизировать ваш код по-другому, или даже вы обновите ЦП — ваш код может сломаться аналогичным образом.
Лучше подход, просто перестаньте сравнивать числа с плавающей запятой для точного равенства. Вместо этого рассчитайте, например, абсолютная разница, и сравните это с достаточно маленькой константой.