Наиболее эффективный способ получить целочисленный идентификатор типа в семействе общих базовых типов
Эта проблема:
У меня есть семейство объектов с общей базой, и мне нужно иметь возможность идентифицировать конкретный конкретный тип с помощью целочисленного значения.
Для этого есть два очевидных подхода, однако оба они сопровождаются недопустимыми накладными расходами с точки зрения памяти или процессорного времени. Поскольку проект имеет дело с миллиардами объектов, самые незначительные накладные расходы оказываются сильно выраженными, и я проверял это, это не случай преждевременной оптимизации. Все операции, выполняемые при обработке объектов, являются тривиальными, а накладные расходы на виртуальные вызовы значительно снижают производительность.
-
чистый виртуальный
int type()функция реализована для каждого типа, к сожалению, это связано с издержками виртуального вызова для чего-то столь же тривиального, как возвращение статического целочисленного значения -
int typeчлен для каждого экземпляра, указанного в типе конструктора, который вводит 4-байтовые издержки для каждого из этих миллиардов объектов, тратит память, загрязняет кэш и т. д.
Я помню, как некоторое время назад кто-то спрашивал о «статических виртуальных переменных-членах», и, естественно, ответы сводились к «нет, это не имеет смысла», однако он мог поместить пользовательскую переменную в виртуальную таблицу и иметь возможность установить ее значение. для каждого конкретного типа, кажется, очень эффективное решение моей проблемы.
Таким образом, избегаются оба вышеупомянутых накладных расхода, виртуальные вызовы не требуются, и нет никаких накладных расходов памяти для каждого экземпляра. Единственные издержки — это перенаправление на получение vtable, но, учитывая частоту доступа к этим данным, они, скорее всего, большую часть времени будут храниться в кэше процессора.
Мой текущий очевидный вариант — сделать «ручное ООП» — сделать vtables вручную, чтобы включить в них необходимые «мета» данные, инициализировать указатель vtable для каждого типа и использовать неловкий синтаксис для вызова псевдо «членских» функций. Или даже вообще опустите использование указателя vtable, и вместо этого сохраните идентификатор и используйте его в качестве индекса для таблицы vtables, что будет еще более эффективным, поскольку позволит избежать косвенного обращения и уменьшит размер, поскольку мне нужно только 2 ^ 14 различных типов.
Было бы хорошо, если бы я мог не изобретать велосипед. Я не придирчив к решению, поскольку оно может дать мне гарантии эффективности.
Может быть, есть способ получить целочисленное значение моего идентификатора типа в vtable, или, может быть, есть и другой способ, который весьма возможен, поскольку я не успеваю за тенденциями, а в C ++ появилось много новых функций в последние несколько года.
Естественно, эти идентификаторы должны быть единообразными и непротиворечивыми, а не какими-либо произвольными значениями того, что компилятор готовит внутри. Если бы это не было требованием, я бы просто использовал значения указателя vtable для еще более эффективного решения, которое позволяет избежать косвенного обращения.
Есть идеи?
Решение
Если у вас гораздо больше экземпляров, чем у типов, то самым простым решением будет абстрагироваться на уровне однородного контейнера, а не одного экземпляра.
Вместо:
{PolymorphicContainer}: Foo*, Bar*, Baz*, Foo*, Bar*, Bar*, Baz*, ...
… и необходимость хранить некоторую информацию о типе (vtable, type поле и т. д.) для различения каждого элемента при доступе к памяти наиболее частыми способами вы можете иметь:
{FooContainer}: Foo, Foo, Foo, Foo, Foo, ...
{BarContainer}: Bar, Bar, Bar, Bar, Bar, ...
{BazContainer}: Baz, Baz, Baz, Baz, Baz, ...
{PolymorphicContainer}: FooContainer*, BarContainer*, BazContainer*
И вы храните информацию о типе (vtable или что нет) внутри контейнеров. Это означает, что вам нужны шаблоны доступа, которые обычно бывают более однородными, но часто такое решение может быть достигнуто в большинстве проблем, с которыми я сталкивался.
Gamedevs делали такие вещи, как сортировка полиморфных базовых указателей по подтипам, в то же время используя собственный распределитель для каждого из них, чтобы хранить их непрерывно. Эта комбинация сортировки по базовому адресу указателя и выделения каждого типа из отдельных пулов позволяет получить аналогичный эквивалент:
Foo*, Foo*, Foo*, Foo*, ..., Bar*, Bar*, Bar*, Bar*, ..., Baz*, Baz*, Baz*, ...
При этом большинство из них хранятся смежно, потому что каждый из них использует свой собственный распределитель, который помещает все Foo в непрерывные блоки отдельно от всех баров, например, Затем поверх пространственной локальности вы также получаете временную локальность на виртуальных таблицах, если вы обращаетесь к вещам в последовательном порядке.
Но для меня это более болезненно, чем абстрагирование на уровне контейнера, и для его выполнения по-прежнему требуются два указателя (128 бит на 64-битных машинах) на объект (vptr и базовый указатель на сам объект). ). Вместо обработки орков, гоблинов, людей и т. Д. Индивидуально через Creature* базовый указатель, имеет смысл хранить их в однородных контейнерах, абстрагировать их и обрабатывать Creatures* указатели, которые указывают на целые однородные коллекции. Вместо:
class Orc: public Creature {...};
… мы делаем:
// vptr only stored once for all orcs in the entire game.
class Orcs: public Creatures
{
public:
// public interface consists predominantly of functions
// which process entire ranges of orcs at once (virtual
// dispatch only paid once possibly for a million orcs
// rather than a million times over per orc).
...
private:
struct OrcData {...};
std::vector<OrcData> orcs;
};
Вместо:
for each creature:
creature.do_something();
Мы делаем:
for each creatures:
creatures.do_something();
Используя эту стратегию, если нам понадобится миллион орков в нашей видеоигре, мы сократили бы расходы, связанные с виртуальной отправкой, vptrs и базовыми указателями, до 1/1 000 000-й от первоначальной стоимости, не говоря уже о том, что вы получаете очень оптимальное расположение Ссылка также бесплатно.
Если в некоторых случаях нам нужно что-то сделать с конкретным существом, вы можете сохранить индекс из двух частей (может уместить его в 32-битной или, возможно, 48), хранить индекс типа существа, а затем относительный индекс существа в этот контейнер, хотя эта стратегия наиболее полезна, когда вам не нужно вызывать функции только для обработки одного существа на ваших критических путях. Как правило, вы можете вписать это в 32-битные индексы или, возможно, в 48-битные, если затем вы установите предел для каждого однородного контейнера в 2 ^ 16, прежде чем он будет считаться «полным», и создадите еще один для того же типа, например. Нам не нужно хранить все существа одного типа в одном контейнере, если мы хотим заполнить наши индексы.
Я не могу с уверенностью сказать, применимо ли это к вашему случаю, потому что это зависит от шаблонов доступа, но обычно это первое решение, которое я рассматриваю, когда у вас возникают проблемы с производительностью, связанные с полиморфизмом. Первый способ, которым я смотрю на это, заключается в том, что вы оплачиваете расходы, такие как виртуальная диспетчеризация, потеря последовательных шаблонов доступа, потеря временной локальности для vtables, накладные расходы памяти vptr и т. Д. На слишком детальном уровне. Сделайте дизайн более грубым (более крупные объекты, такие как объекты, представляющие целую коллекцию вещей, а не отдельный объект на вещь), и затраты снова станут незначительными.
Как бы то ни было, вместо того, чтобы думать об этом с точки зрения vtables, а что нет, подумайте об этом с точки зрения того, как вы упорядочиваете данные, просто биты и байты, чтобы вам не приходилось хранить указатель или целое число с каждым один маленький объект. Рисуйте вещи, думая только о битах и байтах, а не о классах и виртуальных таблицах, виртуальных функциях, хороших открытых интерфейсах и так далее. Подумайте об этом позже, после того как вы остановитесь на представлении / расположении памяти и начнете думать только о битах и байтах, например:
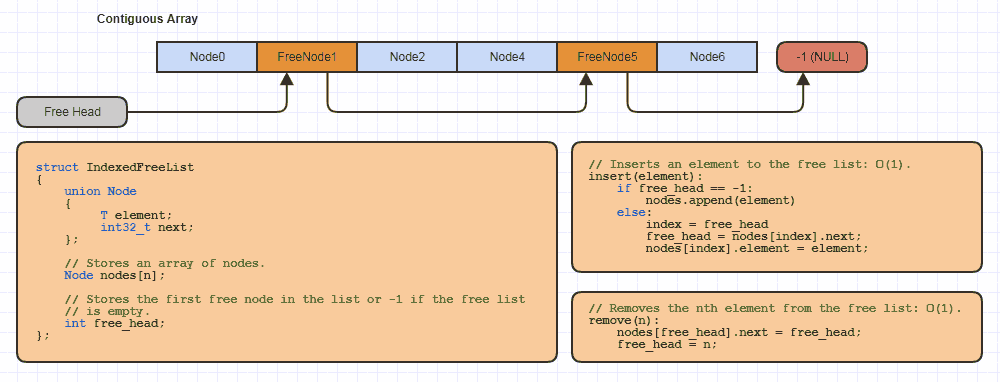
Я считаю, что гораздо проще думать об ориентированных на данные проектах с заранее ожидаемыми критически важными для производительности требованиями, чем пытаться думать о языковых механизмах, хороших интерфейсах и прочем. Вместо этого я думаю C-образным способом, в первую очередь, просто битами и байтами, и сообщаю и набрасываю свои идеи как structs и выяснить, куда должны идти биты и байты. Затем, как только вы поймете это, вы сможете выяснить, как поместить хороший интерфейс на вершину.
В любом случае, для избежания накладных расходов на информацию о типе для каждого объекта, это означает, что они каким-то образом группируются в памяти и сохраняют поле аналогичного типа один раз для каждой группы, а не один раз для каждого элемента в группе. Распределение элементов определенного типа единообразным способом может также дать вам эту информацию на основе их адреса или индекса указателя, например, Есть много способов обойти это, но просто подумайте об этом с точки зрения данных, хранящихся в памяти, как общей стратегии.
Ответ несколько встроен в тему вашего вопроса:
Наиболее эффективный способ получить целочисленный идентификатор типа в общей семье
базовые типы […]
Целочисленный идентификатор сохраняется один раз для каждого семейства или хотя бы один раз для нескольких объектов в этом семействе, а не один раз для каждого объекта. Это единственный способ, как бы вы к нему ни подходили, избегать его сохранения по одному объекту, если информация уже не доступна. Альтернатива состоит в том, чтобы вывести его из некоторой другой доступной информации, как, например, вы можете вывести его из индекса объекта или адреса указателя, после чего сохранение идентификатора будет просто избыточной информацией.
Другие решения
Других решений пока нет …