Моя нейронная сеть не изучает правильные ответы
Во-первых, я полный любитель, поэтому могу перепутать терминологию.
Я работал над нейронной сетью, чтобы сыграть в Connect 4 / Four In A Row.
Текущий дизайн модели сети состоит из 170 входных значений, 417 скрытых нейронов и 1 выходного нейрона. Сеть полностью подключена, то есть каждый вход связан с каждым скрытым нейроном, а каждый скрытый нейрон связан с выходным узлом.
Каждое соединение имеет независимый вес, а каждый скрытый узел и единственный выходной узел имеют дополнительный узел смещения с весом.
Входное представление 170 значений для игрового состояния Connect 4:
- 42 пары значений (84 входных переменных), которые обозначают, занято ли место игроком 1, игроком 2 или вакантно.
0,0означает, что это бесплатно1,0означает, что это позиция игрока 10,1означает, что это позиция игрока 21,1это невозможно
- Еще 42 пары значений (84 входных переменных), которые обозначают, даст ли добавление части здесь игроку 1 или игроку 2 «Соединить 4» / «Четыре в ряд». Комбинация значений означает то же, что и выше.
- 2 последние входные переменные для обозначения чей это очереди:
1,0ход игрока 10,1ход игрока 21,1а также0,0не возможно
Я измерил среднюю среднеквадратическую ошибку для 100 игр, а для 10000 игр различных конфигураций было получено:
- 417 скрытых нейронов
- Скорость обучения альфа и бета 0,1 в начале и линейным падением до 0,01 по общему количеству эпох
- Лямбда-значение 0,5
- 90 из 100 ходов случайны в начале и опускаются до 10 из каждых 100 после первых 50% эпох. Таким образом, в средней точке 10 из 100 ходов являются случайными
- Первые 50% эпох начинаются со случайного хода
- Функция активации сигмоида, используемая в каждом узле
Это изображение показывает результаты различных конфигураций, нанесенных в логарифмическом масштабе. Вот как я определил, какую конфигурацию использовать.
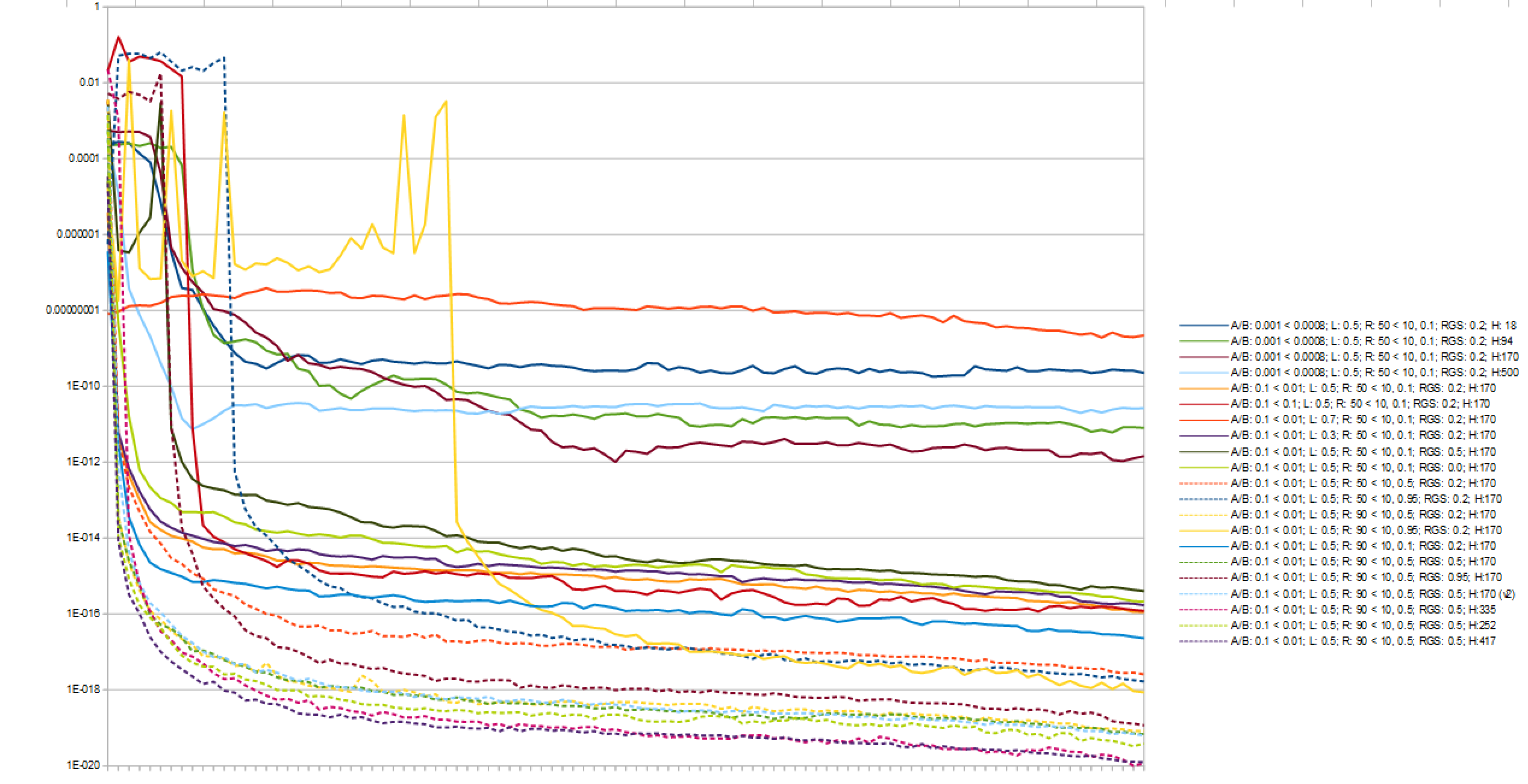
Я вычисляю эту среднеквадратическую ошибку, сравнивая вывод платы в выигрышном состоянии с -1 для игрока 2 победа и 1 для игрока 1 победа. Я складываю их в каждые 100 игр и делю общее количество на 100, чтобы получить 1000 значений для построения графика на приведенном выше графике. То есть фрагмент кода:
if(board.InARowConnected(4) == Board<7,6,4>::Player1)
{
totalLoss += NN->BackPropagateFinal({1},previousNN,alpha,beta,lambda);
winState = true;
}
else if(board.InARowConnected(4) == Board<7,6,4>::Player2)
{
totalLoss += NN->BackPropagateFinal({-1},previousNN,alpha,beta,lambda);
winState = true;
}
else if(!board.IsThereAvailableMove())
{
totalLoss += NN->BackPropagateFinal({0},previousNN,alpha,beta,lambda);
winState = true;
}
...
if(gameNumber % 100 == 0 && gameNumber != 0)
{
totalLoss = totalLoss / gamesToOutput;
matchFile << std::fixed << std::setprecision(51) << totalLoss << std::endl;
totalLoss = 0.0;
}
Я тренирую сеть, заставляя ее играть против себя снова и снова. Это прямая сеть, и я использую TD-Lambda для обучения ее для каждого хода (каждый ход, который не был выбран случайным образом).
Состояние Правления, которое передается Нейронной сети, осуществляется через это:
template<std::size_t BoardWidth, std::size_t BoardHeight, std::size_t InARow>
void create_board_state(std::array<double,BoardWidth*BoardHeight*4+2>& gameState, const Board<BoardWidth,BoardHeight,InARow>& board,
const typename Board<BoardWidth,BoardHeight,InARow>::Player player)
{
using BoardType = Board<BoardWidth,BoardHeight,InARow>;
auto bb = board.GetBoard();
std::size_t stateIndex = 0;
for(std::size_t boardIndex = 0; boardIndex < BoardWidth*BoardHeight; ++boardIndex, stateIndex += 2)
{
if(bb[boardIndex] == BoardType::Free)
{
gameState[stateIndex] = 0;
gameState[stateIndex+1] = 0;
}
else if(bb[boardIndex] == BoardType::Player1)
{
gameState[stateIndex] = 1;
gameState[stateIndex+1] = 0;
}
else
{
gameState[stateIndex] = 0;
gameState[stateIndex+1] = 1;
}
}
for(std::size_t x = 0; x < BoardWidth; ++x)
{
for(std::size_t y = 0; y < BoardHeight; ++y)
{
auto testBoard1 = board;
auto testBoard2 = board;
testBoard1.SetBoardChecker(x,y,Board<BoardWidth,BoardHeight,InARow>::Player1);
testBoard2.SetBoardChecker(x,y,Board<BoardWidth,BoardHeight,InARow>::Player2);
// player 1's set
if(testBoard1.InARowConnected(4) == Board<7,6,4>::Player1)
gameState[stateIndex] = 1;
else
gameState[stateIndex] = 0;
// player 2's set
if(testBoard2.InARowConnected(4) == Board<7,6,4>::Player2)
gameState[stateIndex+1] = 1;
else
gameState[stateIndex+1] = 0;
stateIndex += 2;
}
}
if(player == Board<BoardWidth,BoardHeight,InARow>::Player1)
{
gameState[stateIndex] = 1;
gameState[stateIndex+1] = 0;
}
else
{
gameState[stateIndex] = 0;
gameState[stateIndex+1] = 1;
}
}
Это сделано для того, чтобы потом было легче что-то менять. Я не верю, что что-то не так в вышесказанном.
Моя функция активации сигмоида:
inline double sigmoid(const double x)
{
// return 1.0 / (1.0 + std::exp(-x));
return x / (1.0 + std::abs(x));
}
Мой Нейрон Класс
template<std::size_t NumInputs>
class Neuron
{
public:
Neuron()
{
for(auto& i : m_inputValues)
i = 9;
for(auto& e : m_eligibilityTraces)
e = 9;
for(auto& w : m_weights)
w = 9;
m_biasWeight = 9;
m_biasEligibilityTrace = 9;
m_outputValue = 9;
}
void SetInputValue(const std::size_t index, const double value)
{
m_inputValues[index] = value;
}
void SetWeight(const std::size_t index, const double weight)
{
if(std::isnan(weight))
throw std::runtime_error("Shit! this is a nan bread");
m_weights[index] = weight;
}
void SetBiasWeight(const double weight)
{
m_biasWeight = weight;
}
double GetInputValue(const std::size_t index) const
{
return m_inputValues[index];
}
double GetWeight(const std::size_t index) const
{
return m_weights[index];
}
double GetBiasWeight() const
{
return m_biasWeight;
}
double CalculateOutput()
{
m_outputValue = 0;
for(std::size_t i = 0; i < NumInputs; ++i)
{
m_outputValue += m_inputValues[i] * m_weights[i];
}
m_outputValue += 1.0 * m_biasWeight;
m_outputValue = sigmoid(m_outputValue);
return m_outputValue;
}
double GetOutput() const
{
return m_outputValue;
}
double GetEligibilityTrace(const std::size_t index) const
{
return m_eligibilityTraces[index];
}
void SetEligibilityTrace(const std::size_t index, const double eligibility)
{
m_eligibilityTraces[index] = eligibility;
}
void SetBiasEligibility(const double eligibility)
{
m_biasEligibilityTrace = eligibility;
}
double GetBiasEligibility() const
{
return m_biasEligibilityTrace;
}
void ResetEligibilityTraces()
{
for(auto& e : m_eligibilityTraces)
e = 0;
m_biasEligibilityTrace = 0;
}
private:
std::array<double,NumInputs> m_inputValues;
std::array<double,NumInputs> m_weights;
std::array<double,NumInputs> m_eligibilityTraces;
double m_biasWeight;
double m_biasEligibilityTrace;
double m_outputValue;
};
Мой класс нейронной сети
шаблон
класс NeuralNetwork
{
общественности:
void RandomiseWeights()
{
double inputToHiddenRange = 4.0 * std::sqrt(6.0 / (NumInputs+1+NumOutputs));
RandomGenerator inputToHidden(-inputToHiddenRange,inputToHiddenRange);
double hiddenToOutputRange = 4.0 * std::sqrt(6.0 / (NumHidden+1+1));
RandomGenerator hiddenToOutput(-hiddenToOutputRange,hiddenToOutputRange);
for(auto& hiddenNeuron : m_hiddenNeurons)
{
for(std::size_t i = 0; i < NumInputs; ++i)
hiddenNeuron.SetWeight(i, inputToHidden());
hiddenNeuron.SetBiasWeight(inputToHidden());
}
for(auto& outputNeuron : m_outputNeurons)
{
for(std::size_t h = 0; h < NumHidden; ++h)
outputNeuron.SetWeight(h, hiddenToOutput());
outputNeuron.SetBiasWeight(hiddenToOutput());
}
}
double GetOutput(const std::size_t index) const
{
return m_outputNeurons[index].GetOutput();
}
std::array<double,NumOutputs> GetOutputs()
{
std::array<double, NumOutputs> returnValue;
for(std::size_t o = 0; o < NumOutputs; ++o)
returnValue[o] = m_outputNeurons[o].GetOutput();
return returnValue;
}
void SetInputValue(const std::size_t index, const double value)
{
for(auto& hiddenNeuron : m_hiddenNeurons)
hiddenNeuron.SetInputValue(index, value);
}
std::array<double,NumOutputs> Calculate()
{
for(auto& h : m_hiddenNeurons)
h.CalculateOutput();
for(auto& o : m_outputNeurons)
o.CalculateOutput();
return GetOutputs();
}
std::array<double,NumOutputs> FeedForward(const std::array<double,NumInputs>& inputValues)
{
for(std::size_t h = 0; h < NumHidden; ++h)//auto& hiddenNeuron : m_hiddenNeurons)
{
for(std::size_t i = 0; i < NumInputs; ++i)
m_hiddenNeurons[h].SetInputValue(i,inputValues[i]);
m_hiddenNeurons[h].CalculateOutput();
}
std::array<double, NumOutputs> returnValue;
for(std::size_t h = 0; h < NumHidden; ++h)
{
auto hiddenOutput = m_hiddenNeurons[h].GetOutput();
for(std::size_t o = 0; o < NumOutputs; ++o)
m_outputNeurons[o].SetInputValue(h, hiddenOutput);
}
for(std::size_t o = 0; o < NumOutputs; ++o)
{
returnValue[o] = m_outputNeurons[o].CalculateOutput();
}
return returnValue;
}
double BackPropagateFinal(const std::array<double,NumOutputs>& actualValues, const NeuralNetwork<NumInputs,NumHidden,NumOutputs>* NN, const double alpha, const double beta, const double lambda)
{
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = actualValues[iO];
for(std::size_t iH = 0; iH < NumHidden; ++iH)
{
auto e = NN->m_outputNeurons[iO].GetEligibilityTrace(iH);
auto h = NN->m_hiddenNeurons[iH].GetOutput();
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
double e1 = lambda * e + (y * (1.0 - y) * h);
double w1 = w + beta * (y1 - y) * e1;
m_outputNeurons[iO].SetEligibilityTrace(iH,e1);
m_outputNeurons[iO].SetWeight(iH,w1);
}
auto e = NN->m_outputNeurons[iO].GetBiasEligibility();
auto h = 1.0;
auto w = NN->m_outputNeurons[iO].GetBiasWeight();
double e1 = lambda * e + (y * (1.0 - y) * h);
double w1 = w + beta * (y1 - y) * e1;
m_outputNeurons[iO].SetBiasEligibility(e1);
m_outputNeurons[iO].SetBiasWeight(w1);
}
for(std::size_t iH = 0; iH < NumHidden; ++iH)
{
auto h = NN->m_hiddenNeurons[iH].GetOutput();
for(std::size_t iI = 0; iI < NumInputs; ++iI)
{
auto e = NN->m_hiddenNeurons[iH].GetEligibilityTrace(iI);
auto x = NN->m_hiddenNeurons[iH].GetInputValue(iI);
auto u = NN->m_hiddenNeurons[iH].GetWeight(iI);
double sumError = 0;
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = actualValues[iO];
auto grad = y1 - y;
double e1 = lambda * e + (y * (1.0 - y) * w * h * (1.0 - h) * x);
sumError += grad * e1;
}
double u1 = u + alpha * sumError;
m_hiddenNeurons[iH].SetEligibilityTrace(iI,sumError);
m_hiddenNeurons[iH].SetWeight(iI,u1);
}
auto e = NN->m_hiddenNeurons[iH].GetBiasEligibility();
auto x = 1.0;
auto u = NN->m_hiddenNeurons[iH].GetBiasWeight();
double sumError = 0;
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = actualValues[iO];
auto grad = y1 - y;
double e1 = lambda * e + (y * (1.0 - y) * w * h * (1.0 - h) * x);
sumError += grad * e1;
}
double u1 = u + alpha * sumError;
m_hiddenNeurons[iH].SetBiasEligibility(sumError);
m_hiddenNeurons[iH].SetBiasWeight(u1);
}
double retVal = 0;
for(std::size_t o = 0; o < NumOutputs; ++o)
{
retVal += 0.5 * alpha * std::pow((NN->GetOutput(o) - GetOutput(0)),2);
}
return retVal / NumOutputs;
}
double BackPropagate(const NeuralNetwork<NumInputs,NumHidden,NumOutputs>* NN, const double alpha, const double beta, const double lambda)
{
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = m_outputNeurons[iO].GetOutput();
for(std::size_t iH = 0; iH < NumHidden; ++iH)
{
auto e = NN->m_outputNeurons[iO].GetEligibilityTrace(iH);
auto h = NN->m_hiddenNeurons[iH].GetOutput();
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
double e1 = lambda * e + (y * (1.0 - y) * h);
double w1 = w + beta * (y1 - y) * e1;
m_outputNeurons[iO].SetEligibilityTrace(iH,e1);
m_outputNeurons[iO].SetWeight(iH,w1);
}
auto e = NN->m_outputNeurons[iO].GetBiasEligibility();
auto h = 1.0;
auto w = NN->m_outputNeurons[iO].GetBiasWeight();
double e1 = lambda * e + (y * (1.0 - y) * h);
double w1 = w + beta * (y1 - y) * e1;
m_outputNeurons[iO].SetBiasEligibility(e1);
m_outputNeurons[iO].SetBiasWeight(w1);
}
for(std::size_t iH = 0; iH < NumHidden; ++iH)
{
auto h = NN->m_hiddenNeurons[iH].GetOutput();
for(std::size_t iI = 0; iI < NumInputs; ++iI)
{
auto e = NN->m_hiddenNeurons[iH].GetEligibilityTrace(iI);
auto x = NN->m_hiddenNeurons[iH].GetInputValue(iI);
auto u = NN->m_hiddenNeurons[iH].GetWeight(iI);
double sumError = 0;
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = m_outputNeurons[iO].GetOutput();
auto grad = y1 - y;
double e1 = lambda * e + (y * (1.0 - y) * w * h * (1.0 - h) * x);
sumError += grad * e1;
}
double u1 = u + alpha * sumError;
m_hiddenNeurons[iH].SetEligibilityTrace(iI,sumError);
m_hiddenNeurons[iH].SetWeight(iI,u1);
}
auto e = NN->m_hiddenNeurons[iH].GetBiasEligibility();
auto x = 1.0;
auto u = NN->m_hiddenNeurons[iH].GetBiasWeight();
double sumError = 0;
for(std::size_t iO = 0; iO < NumOutputs; ++iO)
{
auto w = NN->m_outputNeurons[iO].GetWeight(iH);
auto y = NN->m_outputNeurons[iO].GetOutput();
auto y1 = m_outputNeurons[iO].GetOutput();
auto grad = y1 - y;
double e1 = lambda * e + (y * (1.0 - y) * w * h * (1.0 - h) * x);
sumError += grad * e1;
}
double u1 = u + alpha * sumError;
m_hiddenNeurons[iH].SetBiasEligibility(sumError);
m_hiddenNeurons[iH].SetBiasWeight(u1);
}
double retVal = 0;
for(std::size_t o = 0; o < NumOutputs; ++o)
{
retVal += 0.5 * alpha * std::pow((NN->GetOutput(o) - GetOutput(0)),2);
}
return retVal / NumOutputs;
}
std::array<double,NumInputs*NumHidden+NumHidden+NumHidden*NumOutputs+NumOutputs> GetNetworkWeights() const
{
std::array<double,NumInputs*NumHidden+NumHidden+NumHidden*NumOutputs+NumOutputs> returnVal;
std::size_t weightPos = 0;
for(std::size_t h = 0; h < NumHidden; ++h)
{
for(std::size_t i = 0; i < NumInputs; ++i)
returnVal[weightPos++] = m_hiddenNeurons[h].GetWeight(i);
returnVal[weightPos++] = m_hiddenNeurons[h].GetBiasWeight();
}
for(std::size_t o = 0; o < NumOutputs; ++o)
{
for(std::size_t h = 0; h < NumHidden; ++h)
returnVal[weightPos++] = m_outputNeurons[o].GetWeight(h);
returnVal[weightPos++] = m_outputNeurons[o].GetBiasWeight();
}
return returnVal;
}
static constexpr std::size_t NumWeights = NumInputs*NumHidden+NumHidden+NumHidden*NumOutputs+NumOutputs;void SetNetworkWeights(const std::array<double,NumInputs*NumHidden+NumHidden+NumHidden*NumOutputs+NumOutputs>& weights)
{
std::size_t weightPos = 0;
for(std::size_t h = 0; h < NumHidden; ++h)
{
for(std::size_t i = 0; i < NumInputs; ++i)
m_hiddenNeurons[h].SetWeight(i, weights[weightPos++]);
m_hiddenNeurons[h].SetBiasWeight(weights[weightPos++]);
}
for(std::size_t o = 0; o < NumOutputs; ++o)
{
for(std::size_t h = 0; h < NumHidden; ++h)
m_outputNeurons[o].SetWeight(h, weights[weightPos++]);
m_outputNeurons[o].SetBiasWeight(weights[weightPos++]);
}
}
void ResetEligibilityTraces()
{
for(auto& h : m_hiddenNeurons)
h.ResetEligibilityTraces();
for(auto& o : m_outputNeurons)
o.ResetEligibilityTraces();
}
private:
std::array<Neuron<NumInputs>,NumHidden> m_hiddenNeurons;
std::array<Neuron<NumHidden>,NumOutputs> m_outputNeurons;
};
Я считаю, что одно из мест, где у меня может быть проблема, это BackPropagate а также BackPropagateFinal методы в классе нейронной сети.
Вот мой main функция, которая обучает сеть:
int main()
{
std::ofstream matchFile("match.txt");
RandomGenerator randomPlayerStart(0,1);
RandomGenerator randomMove(0,100);
Board<7,6,4> board;
auto NN = new NeuralNetwork<7*6*4+2,417,1>();
auto previousNN = new NeuralNetwork<7*6*4+2,417,1>();
NN->RandomiseWeights();
const int numGames = 3000000;
double alpha = 0.1;
double beta = 0.1;
double lambda = 0.5;
double learningRateFloor = 0.01;
double decayRateAlpha = (alpha - learningRateFloor) / numGames;
double decayRateBeta = (beta - learningRateFloor) / numGames;
double randomChance = 90; // out of 100
double randomChangeFloor = 10;
double percentToReduceRandomOver = 0.5;
double randomChangeDecay = (randomChance-randomChangeFloor) / (numGames*percentToReduceRandomOver);
double percentOfGamesToRandomiseStart = 0.5;
int numGamesWonP1 = 0;
int numGamesWonP2 = 0;
int gamesToOutput = 100;
matchFile << "Num Games: " << numGames << "\t\ta,b,l: " << alpha << ", " << beta << ", " << lambda << std::endl;
Board<7,6,4>::Player playerStart = randomPlayerStart() > 0.5 ? Board<7,6,4>::Player1 : Board<7,6,4>::Player2;
double totalLoss = 0.0;
for(int gameNumber = 0; gameNumber < numGames; ++gameNumber)
{
bool winState = false;
Board<7,6,4>::Player playerWhoTurnItIs = playerStart;
playerStart = playerStart == Board<7,6,4>::Player1 ? Board<7,6,4>::Player2 : Board<7,6,4>::Player1;
board.ClearBoard();
int turnNumber = 0;
while(!winState)
{
Board<7,6,4>::Player playerWhoTurnItIsNot = playerWhoTurnItIs == Board<7,6,4>::Player1 ? Board<7,6,4>::Player2 : Board<7,6,4>::Player1;
bool wasRandomMove = false;
std::size_t selectedMove;
bool moveFound = false;
if(board.IsThereAvailableMove())
{
std::vector<std::size_t> availableMoves;
if((gameNumber <= numGames * percentOfGamesToRandomiseStart && turnNumber == 0) || randomMove() > 100.0-randomChance)
wasRandomMove = true;
std::size_t bestMove = 8;
double bestWorstResponse = playerWhoTurnItIs == Board<7,6,4>::Player1 ? std::numeric_limits<double>::min() : std::numeric_limits<double>::max();
for(std::size_t m = 0; m < 7; ++m)
{
Board<7,6,4> testBoard = board; // make a copy of the current board to run our tests
if(testBoard.AvailableMoveInColumn(m))
{
if(wasRandomMove)
{
availableMoves.push_back(m);
}
testBoard.AddChecker(m, playerWhoTurnItIs);
double worstResponse = playerWhoTurnItIs == Board<7,6,4>::Player1 ? std::numeric_limits<double>::max() : std::numeric_limits<double>::min();
std::size_t worstMove = 8;
for(std::size_t m2 = 0; m2 < 7; ++m2)
{
Board<7,6,4> testBoard2 = testBoard;
if(testBoard2.AvailableMoveInColumn(m2))
{
testBoard2.AddChecker(m,playerWhoTurnItIsNot);
StateType state;
create_board_state(state, testBoard2, playerWhoTurnItIs);
auto outputs = NN->FeedForward(state);
if(playerWhoTurnItIs == Board<7,6,4>::Player1 && (outputs[0] < worstResponse || worstMove == 8))
{
worstResponse = outputs[0];
worstMove = m2;
}
else if(playerWhoTurnItIs == Board<7,6,4>::Player2 && (outputs[0] > worstResponse || worstMove == 8))
{
worstResponse = outputs[0];
worstMove = m2;
}
}
}
if(playerWhoTurnItIs == Board<7,6,4>::Player1 && (worstResponse > bestWorstResponse || bestMove == 8))
{
bestWorstResponse = worstResponse;
bestMove = m;
}
else if(playerWhoTurnItIs == Board<7,6,4>::Player2 && (worstResponse < bestWorstResponse || bestMove == 8))
{
bestWorstResponse = worstResponse;
bestMove = m;
}
}
}
if(bestMove == 8)
{
std::cerr << "wasn't able to determine the best move to make" << std::endl;
return 0;
}
if(gameNumber <= numGames * percentOfGamesToRandomiseStart && turnNumber == 0)
{
std::size_t rSelection = int(randomMove()) % (availableMoves.size());
selectedMove = availableMoves[rSelection];
moveFound = true;
}
else if(wasRandomMove)
{
std::remove(availableMoves.begin(),availableMoves.end(),bestMove);
std::size_t rSelection = int(randomMove()) % (availableMoves.size());
selectedMove = availableMoves[rSelection];
moveFound = true;
}
else
{
selectedMove = bestMove;
moveFound = true;
}
}
StateType prevState;
create_board_state(prevState,board,playerWhoTurnItIs);
NN->FeedForward(prevState);
*previousNN = *NN;
// now that we have the move, add it to the board
StateType state;
board.AddChecker(selectedMove,playerWhoTurnItIs);
create_board_state(state,board,playerWhoTurnItIsNot);
auto outputs = NN->FeedForward(state);
if(board.InARowConnected(4) == Board<7,6,4>::Player1)
{
totalLoss += NN->BackPropagateFinal({1},previousNN,alpha,beta,lambda);
winState = true;
++numGamesWonP1;
}
else if(board.InARowConnected(4) == Board<7,6,4>::Player2)
{
totalLoss += NN->BackPropagateFinal({-1},previousNN,alpha,beta,lambda);
winState = true;
++numGamesWonP2;
}
else if(!board.IsThereAvailableMove())
{
totalLoss += NN->BackPropagateFinal({0},previousNN,alpha,beta,lambda);
winState = true;
}
else if(turnNumber > 0 && !wasRandomMove)
{
NN->BackPropagate(previousNN,alpha,beta,lambda);
}
if(!wasRandomMove)
{
outputs = NN->FeedForward(state);
}
++turnNumber;
playerWhoTurnItIs = playerWhoTurnItIsNot;
}
alpha -= decayRateAlpha;
beta -= decayRateBeta;
NN->ResetEligibilityTraces();
if(gameNumber > 0 && randomChance > randomChangeFloor && gameNumber <= numGames * percentToReduceRandomOver)
{
randomChance -= randomChangeDecay;
if(randomChance < randomChangeFloor)
randomChance = randomChangeFloor;
}
if(gameNumber % gamesToOutput == 0 && gameNumber != 0)
{
totalLoss = totalLoss / gamesToOutput;
matchFile << std::fixed << std::setprecision(51) << totalLoss << std::endl;
totalLoss = 0.0;
}
}
matchFile << std::endl << "Games won: " << numGamesWonP1 << " . " << numGamesWonP2 << std::endl;
auto weights = NN->GetNetworkWeights();
matchFile << std::endl;
matchFile << std::endl;
for(const auto& w : weights)
matchFile << std::fixed << std::setprecision(51) << w << ", \n";
matchFile << std::endl;
return 0;
}
Я думаю, у меня может возникнуть проблема с минимаксом, который выбирает лучший ход.
Есть несколько дополнительных статей, которые, я думаю, не имеют отношения к моим проблемам.
Проблемы
-
Кажется, не имеет значения, тренирую я 1000 игр или 3000000 игр, игрок 1 или игрок 2 выиграет в подавляющем большинстве игр. Примерно 90 из 100 игр, выигранных одним игроком. Если я вывожу фактические отдельные ходы и результаты игры, я вижу, что игры, выигранные другим игроком, почти всегда являются результатом случайного случайного хода.
В то же время я замечаю, что прогноз выводит своего рода «пользу» игроку. То есть выходы, кажется, на отрицательной стороне
0Так, например, Игрок 1 всегда делает лучшие ходы, какие только может, но все они, по-видимому, предсказывают победу Игрока 2.Иногда это Игрок 1, который выигрывает большинство, иногда Игрок 2. Я предполагаю, что это из-за инициализации случайных весов
незначительно по отношению к одному игроку.Первая игра или около того не одобряет одного игрока над другим, но она очень быстро начинает «наклоняться» в одну сторону.
-
Я пробовал тренировать более 3000000 игр, что заняло 3 дня, но сеть все еще не может принимать правильные решения. Я проверил сеть, заставив ее играть в других «ботов» на riddles.io Connect 4 comp.
- Он не может распознать, что ему нужно блокировать противников 4 подряд
- Он даже после 3000000 игр не играет центральную колонну в качестве первого хода, который, как мы знаем, является единственным стартовым ходом, который вы можете сделать, чтобы гарантировать победу.
Любая помощь и направление будет принята с благодарностью. В частности, правильна ли моя реализация обратного распространения TD-Lambda?
Решение
Задача ещё не решена.
Другие решения
Других решений пока нет …