многопоточность — C ++ итерирует вектор случайным образом
Я работаю над многопоточной программой, где все потоки имеют общий вектор (только для чтения). Цель каждого потока — пройти весь вектор. Тем не менее, все потоки должны посещать этот вектор по-разному.
Поскольку вектор является константным и общим для всех потоков, я не могу использовать random_shuffle и просто перебирать его. На данный момент мое решение состоит в том, чтобы построить
перекрестный вектор, который будет содержать индексы по общему вектору, а затем
перетасовать этот вектор, т.е.
std::vector<int> crossref(SIZE) ; // SIZE is the size of the shared vector
std::iota (std::begin(crossref), std::end(crossref), 0); // Fill with indices ref
std::mt19937 g(SEED); // each thread has it own seed.
std::shuffle (crossref_.begin(), crossref_.end(), g); // Shuffle it
Тем не менее, выполнение этого выявляет некоторые проблемы (1) это не очень эффективно, так как каждый поток должен получить доступ к своему перекрестному вектору перед доступом к общему, (2) у меня есть некоторые проблемы производительности из-за количества требуемой памяти: общий вектор очень большой и у меня много потоков и процессоров.
У кого-нибудь есть идеи по улучшению, которые позволят избежать необходимости в дополнительной памяти?
Решение
Вы можете использовать алгебраическое понятие первообразный корень по модулю n.
В принципе
Если n — положительное целое число, целые числа от 1 до n — 1, которые
взаимно простыми образуют группу примитивных классов по модулю n. Эта группа
является циклическим тогда и только тогда, когда n равно 2, 4, p ^ k или 2p ^ k, где p ^ k
степень нечетного простого числа
Википедия показывает, как вы можете генерировать числа ниже 7 с помощью 3 как генератор.
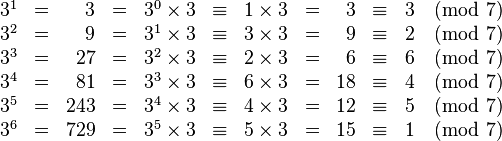
Из этого утверждения вы выводите алгоритм.
- Возьми свой номер
n - Найти следующее простое число
mкоторый больше чемn - Для каждой вашей темы выберите уникальное случайное число
F(0)между2а такжеm - Вычислить следующий индекс, используя
F(i+1) = (F(i) * F(0)) mod m, Если этот индекс находится в пределах[0, n]диапазон, доступ к элементу. Если нет, переходите к следующему указателю. - Остановись после
m - 1итерации (или когда вы получаете 1, это то же самое).
Так как m простое число, каждое число от 2 до m-1 взаимно простое с m так же генератор последовательности {1 ... m}, Вам гарантировано, что ни один номер не повторится в первом m - 1 шаги, и это все m - 1 цифры появятся.
Сложность:
- Шаг 2: Выполнено один раз, сложность эквивалентна нахождению простых чисел до n, т.е. сито из Эратосфена
- Шаг 3: Сделано один раз, вы можете выбрать 2, 3, 4, 5 и т. Д.
O(thread count) - Шаг 4:
O(m)время,O(1)в пространстве на поток. Вам не нужно хранить F (I). Вам нужно только знать первое значение и последнее значение. Это те же свойства, что и приращение
Другие решения
Если я хорошо понимаю, вы хотите генерировать случайную перестановку в пошаговом порядке, то есть ты хочешь позвонить N раз функция е так что он генерирует все переставленные числа от 1 до N, так что эта функция имеет постоянную память.
Я сомневаюсь, что он существует, если вы хотите получить равномерное распределение среди перестановок, но вы можете быть удовлетворены подмножеством набора перестановок.
Если это так, вы можете создать перестановку, взяв число п премьер с N и рассчитать для каждого я в [1, n]: i.p (mod n),
Например, если у вас n = 5 и p = 7, то 7% 5 = 2, 14% 5 = 4, 21% 5 = 1, 28% 5 = 3, 35% 5 = 0. Вы можете объединить несколько таких функций, чтобы получить что-то удовлетворяющее вас …
Если память является вашей самой большой проблемой, то вам придется поменять местами циклы ЦП на пространство памяти.
Например. C ++ s std::vector<bool> (http://en.cppreference.com/w/cpp/container/vector_bool) — это битовый массив, поэтому достаточно эффективно использует память.
У каждого потока может быть свой vector<bool> указывает на то, посетил ли он определенный индекс. Тогда вам придется использовать циклы ЦП, чтобы случайным образом выбрать индекс, который он еще не посещал, и завершить работу, когда все boolс true,
Похоже на то этот парень решил твою проблему очень хорошим способом.
Вот что он говорит в первой строке поста: В этом посте я собираюсь показать, как создать итератор, который будет посещать элементы в списке в случайном порядке, посещать каждый элемент только один раз и сообщать вам, когда он прошел все элементы и закончен. Он делает это без сохранения перемешанного списка, и ему также не нужно отслеживать, какие элементы он уже посетил.
Он использует возможности алгоритма блочного шифра с переменной длиной битов, чтобы генерировать каждый индекс в массиве.
Это не полный ответ, но он должен привести нас к правильному решению.
Вы написали некоторые вещи, которые мы могли бы принять за предположения:
(1) это не очень эффективно, так как каждый поток должен иметь доступ к своему
перекрестный вектор перед доступом к общему,
Это вряд ли будет правдой. Мы говорим об одном косвенном поиске. Если ваши справочные данные не являются вектором целых чисел, это будет представлять бесконечно малую часть вашего времени выполнения. Если ваши справочные данные представляют собой вектор целых чисел, просто сделайте их N копий и перемешайте их …
(2) у меня есть проблемы с производительностью из-за объема памяти
требуется: общий вектор очень большой, и у меня много потоков
и процессоры.
Насколько велик? Вы измерили это? Сколько дискретных объектов есть в векторе? Насколько большой каждый?
Сколько потоков?
Сколько процессоров?
Сколько у тебя памяти?
Вы профилировали код? Ты конечно где узкое место производительности? Вы рассматривали более элегантный алгоритм?