Мне нужно некоторое руководство по написанию хэш-функции для сортировки ~ 160 000 строк
Мой инструктор бросил это на нас и сказал, что нам просто нужно Google, как написать хеш-функцию. Я совершенно бессмысленен в этом. Мы написали базовый шаблон Hash Table для класса, но у меня есть проект, который требует, чтобы ~ 160 000 строк были отсортированы в таблицу с как минимум 500 сегментами (я хочу сделать больше для скорости).
Я просто понятия не имею, где искать краткую, легко усваиваемую информацию по этому вопросу.
Любая помощь будет принята с благодарностью.
Решение
Я предлагаю универсальная хеш-функция. Этот тип функции гарантирует небольшое количество столкновений в ожидании, даже если данные выбираются противником. Существует множество универсальных хеш-функций.
В случае строк вы можете использовать следующую хеш-функцию.
Для персонажа с мы определяем # (С) арифметическое значение с то есть (ASCII). Для строки x=c1c1...cn мы определяем 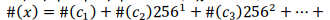
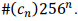
Если HSIZE является целым числом и К большое простое число (вы определяете его) для диапазона 0<a,b<k*HSizeпусть хеш-функция будет:
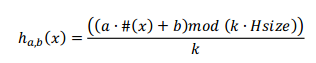
Эта функция обеспечивает вывод между [0, HSize-1]
Выходное значение рассчитывается по правилу Хорнера, находя по модулю k*HSize деление после каждой операции.
Итак, создайте функцию хэш-функция и передайте строку, которую вы хотите хэшировать в качестве параметра.
Вот код:
#define k 7919
#define Hsize 1009
#define a 321
#define b 43112
long long HashFunction(string text)
{
int i;
long long res = 0;
long long M = (Hsize * k);
cout<<"M = "<<M<<endl;
cout<<"Hsize = "<<Hsize<<endl;
cout<<"k = "<<k<<endl;
int s=text.size();
for(i = s-1; i >= 0; i--)
{
res = a * (res * 256 + (int)text[i]);
//cout<<"res before modulo = "<<res<<endl;
res=res % M;
//cout<<"res after modulo = "<<res<<endl;
}
long long res1 = (res + b) / k;
return res1;
}
Другие решения
Других решений пока нет …