MMX v / s SSE2 Сравнение производительности
Проблема:
Я преобразовал MMX в код в соответствующий код SSE2. И я ожидал почти 1,5x-2x ускорения. Но оба заняли одно и то же время. Почему это?
Сценарий:
Я изучаю набор инструкций SIMD и их сравнение производительности. Я взял операцию массива так, что Z = X^2 + Y^2 где X и Y — большой одномерный массив типа «Символ». Значения X и Y ограничены менее 10, так что Z всегда <255 (1 байт). (Не беспокоиться о переполнении).
Сначала я написал код на C ++, проверил время. Затем написал соответствующий код ASSEMBLY (~ 3x ускорение). Затем я написал код MMX (~ 12x v / s C ++). Затем я преобразовал MMX в код SSE2, и он потребляет точно такую же скорость, что и код MMX. Теоретически, в SSE2 я ожидал ускорения в 2 раза по сравнению с MMX.
Для преобразования из MMX в SSE2 я преобразовал все ммх рег в хмм рег. Затем поменял пару инструкций по движению и так далее.
Мои коды MMX и SSE вставлены здесь: https://gist.github.com/abidrahmank/5281486
(Я не хочу вставлять их все здесь)
Эти функции позже вызываются из файла main.cpp, где массивы передаются в качестве аргументов.
Что я сделал :
1 — я просмотрел несколько руководств по оптимизации от Intel и других сайтов. Основная проблема с кодами SSE2 заключается в 16 выравнивание памяти. Когда я вручную проверил адреса, оказалось, что все они выровнены. Но я использовал оба MOVDQU а также MOVDQA, но оба дают тот же результат и не ускорение по сравнению с MMX.
2 — Я перешел в режим отладки и проверил значения каждого регистра с выполненными инструкциями. И они выполняются точно так же, как я думал, т.е. берется 16 байтов, и в результате выводятся 16 байтов.
Ресурсы :
Я использую процессор Intel Core i5 с Windows 7 и Visual C ++ 2010.
Вопрос:
Итак, последний вопрос: почему нет улучшения производительности для кода SSE2 по сравнению с кодом MMX? Я делаю что-то не так в коде SSE? Или есть другое объяснение?
Решение
ГарольдКомментарий был абсолютно верным. Массивы, которые вы обрабатываете, не помещаются в кеш на вашем компьютере, поэтому ваши вычисления полностью зависят от хранилища.
Я рассчитал пропускную способность ваших вычислений на i7 текущего поколения для буферов различной длины, а также пропускную способность той же процедуры со всем, кроме удаленных загрузок и хранилищ:
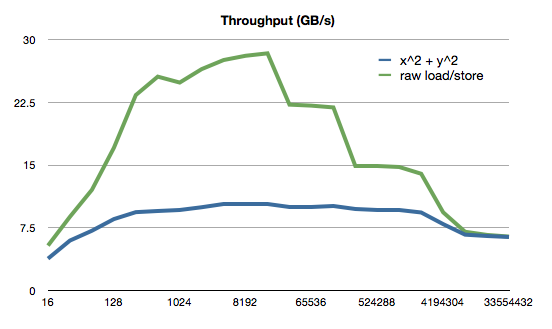
Здесь мы наблюдаем то, что как только буфер становится настолько большим, что он выходит из кэша L3, пропускная способность ваших вычислений точно соответствует достигнутой пропускной способности загрузки / хранения. Это говорит нам о том, что как обработка данных практически не имеет значения (если вы не сделаете это значительно медленнее); скорость вычислений ограничена способностью процессора перемещать данные в / из памяти.
Если вы определите время для меньших массивов, вы увидите разницу между двумя вашими реализациями.
Другие решения
Других решений пока нет …